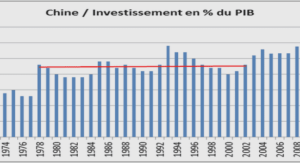
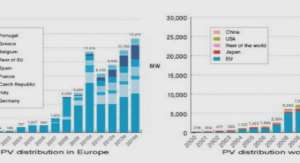
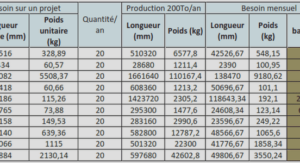
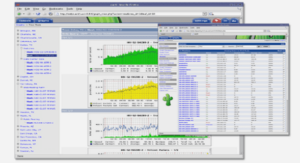
L’analyse des données
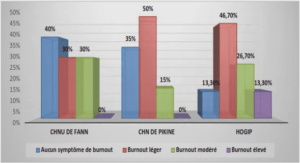
Pour l’essentiel l’analyse des données comprend deux étapes : la classification de l’information et l’analyse proprement dite des données. Les informations recueillies sur un objet de recherche grâce à des protocoles ordonnés d’exploitation des observations que sont les techniques de recherche constituent malgré tout autant d’éléments fragmentaires du phénomène observé et doivent être structurées et articulées de façon cohérente dans un système de relations explicatives. Mais concrètement, comment traiter la quantité d’informations recueillies? Il faut les ordonner, les classer ou les regrouper pour pouvoir les analyser à proprement parler. Les informations recueillies ou les faits observés doivent être isolés, regroupés et classés dans des catégories, dans des tableaux, des graphiques (diagrammes, histogrammes, courbes, etc.). C’est la seule manière de permettre à la quantité importante d’informations de prendre sens en laissant découvrir les liens qui n’étaient pas toujours évidents. Il faut donc traiter les informations ou les faits pour les transformer en données analysables. En principe le terme de « donnée » est réservé pour qualifier l’information traitée. Les informations recueillies subissent un traitement quantitatif par l’analyse statistique descriptive et par l’analyse statistique explicative. Les informations qualitatives sont recueillies et traitées par l’analyse documentaire ou par l’analyse de contenu. Les données sont collectées afin de répondre à une problématique de recherche, pour résoudre un problème posé. En recherche quantitative surtout, les tableaux et les figures (diagrammes, histogrammes, courbes, etc.) sont utiles pour représenter les données. Celles-ci peuvent concerner les modalités d’une seule variable : on peut décrire la distribution des effectifs et les pourcentages des modalités de réponses. Dans une perspective d’explication sociologique, il est possible de construire un tableau qui croise deux variables pour mettre en lumière l’action éventuelle d’un facteur social, l’effet d’un déterminant social. La variable indépendante est celle qui représente, selon l’hypothèse, un facteur qui influe sur… La variable dépendante (qui dépend de l’action de la première) est celle qui est censée subir l’action de ce facteur.
Habituellement, les réponses à la partie du questionnaire par exemple qui porte sur l’objet explicite de la recherche sont considérées comme des variables dépendantes. Ces dernières sont croisées avec les réponses empruntées à la partie du questionnaire cherchant à approcher les facteurs supposés être influents. Le tableau croisé veut rendre visible l’action supposée de la variable indépendante sur la variable dépendante. C’est d’ailleurs par rapport à la variable indépendante qu’on calcule les pourcentages. Par exemple, si l’on pense que le niveau d’étude est un des éléments qui intervient dans la pratique religieuse, on établit un tableau croisant la variable indépendante «niveau d’étude » et la variable dépendante « pratique religieuse ». La structure du tableau doit supposer la relation et fournir des pourcentages calculés par rapport à la variable indépendante. Il arrive qu’une variable test entre en ligne de compte pour permettre de vérifier une relation observée entre deux variables, de mesurer l’effet de la variable indépendante. C’est le cas de l’analyse multivariée. Pour en rester au tableau croisé avec deux variables, considérons, avec tout le sérieux requis, les «règles »que François De Singly fixe pour disposer un tableau (pour une lecture rapide, par l’accoutumance de l’œil, cf. les deux premières règles) et pour analyser les données du tableau. Ce mode de lecture rompt avec la lecture majoritaire qui est le mode de lecture le plus fréquent pour les commentaires de sondage d’opinion. Il ne faut pas regarder ligne par ligne les nombres les plus importants, (souligné par nous), car sinon c’est la modalité la plus fréquente de la variable dépendante dans le groupe considéré (défini par une modalité de la variable indépendante) qui ressort. […] »indiquent l’action de la variable indépendante, il convient d’écrire un ou plusieurs énoncés résumant la ou les variations observées. Le commentaire se concentre donc sur les variations observées selon le principe de la troisième règle. Les phrases doivent être construites autour des termes « plus que » et «moins que » afin de bien marquer la logique comparative de la perspective explicative. ».
L’introduction d’une variable test ne modifie pas les règles de présentation et de lecture des tableaux statistiques. La variable indépendante doit toujours être disposée en ligne et la variable dépendante en colonne. Ce qui change, c’est le nombre de sous-tableaux croisant la variable indépendante et la variable dépendante, fonction du nombre de modalité de la variable test […][…] Pour la lecture de tableaux doublement croisés (c’est-à-dire avec trois variables), il convient de disposer de manière cohérente le tableau selon le contrôle que l’on veut effectuer. La variation recherchée (effet associé au sexe de l’enfant, ou l’effet associé au milieu social de la famille) désigne la variable indépendante, et les conditions dans lesquelles le test est effectué renvoient à la variable test (qui est une variable indépendante qui change provisoirement de statut. »Marie-Fabienne Fortin (1996 : 326) écrit : «Normalement, présenter des résultats consiste à fournir tous les résultats pertinents relativement aux questions de recherche ou aux hypothèses formulées. Lorsque le chercheur présente les résultats de son étude, il doit s’en tenir strictement à une présentation sous forme narrative des résultats qu’il a reproduits dans les tableaux et les figures. L’interprétation des résultats se fera ensuite par une discussion». En fait, selon le type d’étude, la présentation des résultats peut être une analyse descriptive des données (description des variables et de leurs relations pour dégager un portrait de l’ensemble des caractéristiques des sujets) ou être une analyse explicative ou inférentielle des données recherchant la confirmation ou non des hypothèses qui ont été mises à l’épreuve au moyen de tests statistiques.