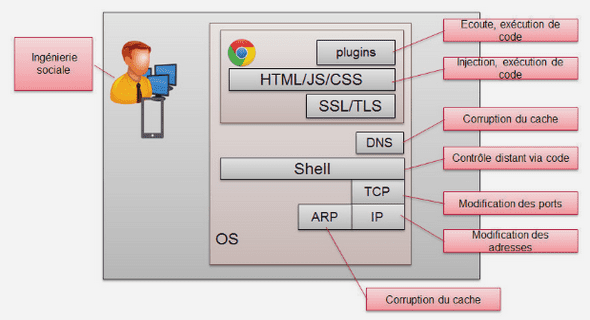
Cours UML comment modéliser avec UML ?, tutoriel & guide de travaux pratiques en pdf.
Approche fonctionnelle versus approche objet
L’approche fonctionnelle
La découpe fonctionnelle d’un problème informatique : une approche intuitive La découpe fonctionnelle d’un problème (sur laquelle reposent les langages de programmation structurée) consiste à découper le problème en blocs indépendants. En ce sens, elle présente un caractère intuitif fort.
La réutilisabilité du code Le découpage d’un problème en blocs indépendants (fonctions et procédures) va permettre aux programmeurs de réutiliser les fonctions déjà développées (à condition qu’elles soient suffisamment génériques). La productivité se trouve donc accrue.
Le revers de la médaille : maintenance complexe en cas d’évolution Le découpage en blocs fonctionnels n’a malheureusement pas que des avantages. Les fonctions sont devenues interdépendantes : une simple mise à jour du logiciel à un point donné, peut impacter en cascade une multitude d’autres fonctions. On peut minorer cet impact, pour peu qu’on utilise des fonctions plus génériques et des structures de données ouvertes. Mais respecter ces contraintes rend l’écriture du logiciel et sa maintenance plus complexe.
En cas d’évolution majeure du logiciel (passage de la gestion d’une bibliothèque à celle d’une médiathèque par exemple), le scénario est encore pire. Même si la structure générale du logiciel reste valide, la multiplication des points de maintenance, engendrée par le chaînage des fonctions, rend l’adaptation très laborieuse. Le logiciel doit être retouché dans sa globalité : – on a de nouvelles données à gérer (ex : DVD) – les traitements évoluent : l’affichage sera différent selon le type (livre, CD, DVD …)
Problèmes générés par la séparation des données et des traitements : Examinons le problème de l’évolution de code fonctionnel plus en détail…
Faire évoluer une application de gestion de bibliothèque pour gérer une médiathèque, afin de prendre en compte de nouveaux types d’ouvrages (cassettes vidéo, CD-ROM, etc…), nécessite : – de faire évoluer les structures de données qui sont manipulées par les fonctions,
– d’adapter les traitements, qui ne manipulaient à l’origine qu’un seul type de document (des livres). Il faudra donc modifier toutes les portions de code qui utilisent la base documentaire, pour gérer les données et les actions propres aux différents types de documents.
Il faudra par exemple modifier la fonction qui réalise l’édition des « lettres de rappel » (une lettre de rappel est une mise en demeure, qu’on envoie automatiquement aux personnes qui tardent à rendre un ouvrage emprunté). Si l’on désire que le délai avant rappel varie selon le type de document emprunté, il faut prévoir une règle de calcul pour chaque type de document.
En fait, c’est la quasi-totalité de l’application qui devra être adaptée, pour gérer les nouvelles données et réaliser les traitements correspondants. Et cela, à chaque fois qu’on décidera de gérer un nouveau type de document !
1ère amélioration : rassembler les valeurs qui caractérisent un type, dans le type Une solution relativement élégante à la multiplication des branches conditionnelles et des redondances dans le code (conséquence logique d’une trop grande ouverture des données), consiste tout simplement à centraliser dans les structures de données, les valeurs qui leurs sont propres. Par exemple, le délai avant rappel peut être défini pour chaque type de document. Cela permet donc de créer une fonction plus générique qui s’applique à tous les types de documents.
2ème amélioration : centraliser les traitements associés à un type, auprès du type Pourquoi ne pas aussi rassembler dans une même unité physique les types de données et tous les traitements associés ?
Que se passerait-il par exemple si l’on centralisait dans un même fichier, la structure de données qui décrit les documents et la fonction de calcul du délai avant rappel ? Cela nous permettrait de retrouver immédiatement la partie de code qui est chargée de calculer le délai avant rappel d’un document, puisqu’elle se trouve au plus près de la structure de données concernée.
Ainsi, si notre médiathèque devait gérer un nouveau type d’ouvrage, il suffirait de modifier une seule fonction (qu’on sait retrouver instantanément), pour assurer la prise en compte de ce nouveau type de document dans le calcul du délai avant rappel. Plus besoin de fouiller partout dans le code…
Ecrit en ces termes, le logiciel serait plus facile à maintenir et bien plus lisible. Le stockage et le calcul du délai avant rappel des documents, serait désormais assuré par une seule et unique unité physique (quelques lignes de code, rapidement identifiables).
Pour accéder à la caractéristique « délai avant rappel » d’un document, il suffit de récupérer la valeur correspondante parmi les champs qui décrivent le document. Pour assurer la prise en compte d’un nouveau type de document dans le calcul du délai avant rappel, il suffit de modifier une seule fonction, située au même endroit que la structure de données qui décrit les documents.