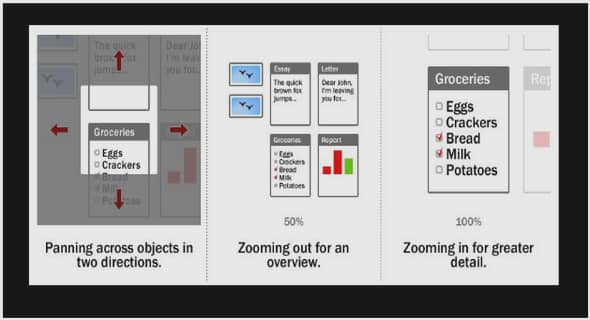
Ce prototype, qui vit le jour en 2003 sous le nom framespace, avant de prendre celui de procspace, serait le plus justement décrit comme un outliner collaboratif pourvu d’extensions de datamining. L’idée d’outline est généralement attribuée à Douglas Engelbart qui reconnaissait les avantages des listes hiérarchiques dépliables pour la représentation des structures conceptuelles dans le contexte des interfaces graphiques. Dans les GUI modernes, on les retrouve à maints endroits, en particulier lorsqu’il faut visualiser des arborescences de dossiers, par exemple dans l’Explorateur de Microsoft Windows. La famille des outliners utilise ce concept dans le cadre d’un éditeur de texte hiérarchique qui permet de structurer des informations et des documents d’une façon simple et rapide. Conformément au sujet de ce travail, nous avons conçu l’outil en tant que métatechnologie dans un double sens : premièrement, le dispositif joue le rôle d’une scène de structuration communautaire des documents et ressources trouvés sur le Web et deuxièmement il devient acteur à travers un système d’agents qui utilisent les structures sémantiques, découvertes et crées par les usagers, dans la génération de « regards » automatiques ainsi que dans la recherche de nouveaux contenus sur le Web.
En veillant surtout à l’application du principe de participation, nous avons choisi de partir d’un outil semi-structuré qui nécessite un certain travail de réflexion et de préparation du côté des usagers sur la Au niveau des apports pratiques, le dispositif est censé partager entre les participants la tâche de chercher et gérer des ressources documentaires en promouvant les effets de synergie qui peuvent se manifester dans un groupe de travail. Avant et pendant la mise en place du premier prototype, cinq axes de réflexion se sont dégagés qui ont par la suite orienté la confrontation des prototypes successifs avec des usagers, testeurs et critiques. La fonctionnalité de base de procspace consiste tout simplement à permettre à un utilisateur de récupérer un document situé sur l’Internet ou sur son disque dur local et à l’insérer dans cette structure éditable de dossiers qu’est l’outline. Il est aussi possible de rédiger un document directement en ligne par le biais d’un formulaire standard. Ainsi, les membres d’un groupe partagent un espace d’information qu’ils alimentent et étendent collectivement. Les ressources trouvées par un usager sont donc mises à la disposition des autres, bien qu’il existe également la possibilité de créer des dossiers privés.
L’une des idées de départ consistait à parier sur la capacité de traitement des êtres humains pour filtrer l’avalanche de documents et d’informations provenant du Web : la cible de notre dispositif, la communauté de pratique, se constitue, dans le contexte scientifique, autour d’un champ de recherche et il est fortement probable que les ressources insérées par un membre du groupe présentent un intérêt pour les autres. En ce sens le dispositif permet, au plan le plus basique, à chaque membre de profiter du travail de sélection et de filtrage de ses collègues. les plus souvent utilisés dans les sciences humaines – texte, Word, PDF, PowerPoint et HTML – le dispositif peut donc accueillir tous les autres types de fichiers même si les agents ne sont pas en mesure de les traiter. Une fois insérés dans le système, ces nœuds peuvent êtres accédés localement dans la base de données du système ou par le biais d’un hyperlien en leur lieu d’origine sur le Web. La collaboration se manifeste déjà par le simple fait qu’un groupe (p.ex. une équipe de recherche) travaille sur la même outline, c’est-à-dire le même espace d’information.
Ce système de recommandation implicite est étendu par un système technique qui permet aux membres d’évaluer la qualité d’une ressource sous la forme d’un vote sur une échelle de cinq valeurs. Rappelant la gestion de la visibilité des messages exploitée dans Slashdot, cela donne lieu à un filtrage de l’outline par la qualité, telle que perçue par la communauté. Adoptant la perspective établie dans la première partie de ce travail, le but de ces deux fonctions était de favoriser par les moyens techniques un processus de « peer review », une évaluation par les pairs, où une partie du travail d’organisation est déléguée à la structure du système qui représente une scène fonctionnelle pour le « jeu » des acteurs humains. Le processus informel du filtrage collaboratif qui a lieu dans chaque communauté de pratique est ainsi transposé dans une structure technique, accessible en permanence à partir de tout ordinateur équipé d’une connexion Internet. Par des moyens plutôt simples, la nature souvent éphémère de la collaboration dans les sciences humaines peut ainsi devenir plus tangible ou « matérielle ».