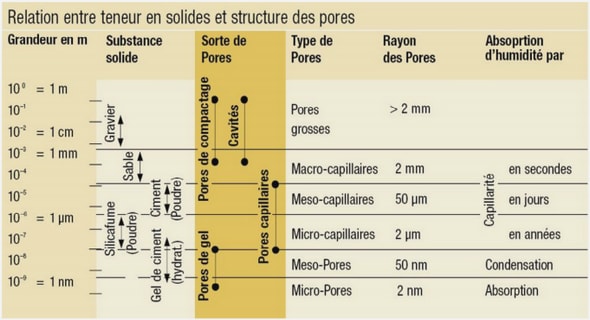
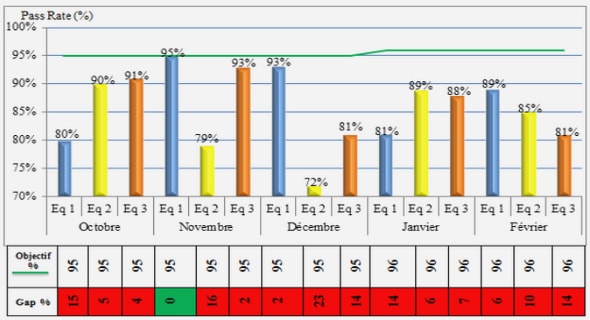
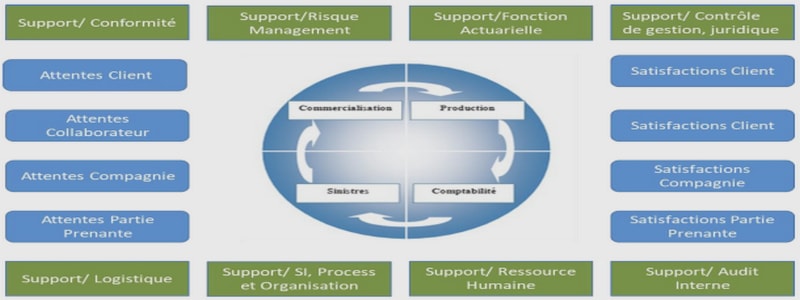
Cours avec résultats et interprétations , tutoriel & guide de travaux pratiques en pdf.
Construction du système d’inférence flou (SIF)
Choix des modalités floues et de quelques paramètres
Dans notre travail, nous avons choisi les modalités floues selon cinq approches : une 1ère approche qui s‟inspire directement de l‟expertise humaine (cardiologue) et les autres approches qui se basent sur la nature de variation des données.
Critères de performances
Nous utilisons le logiciel FisPro pour générer les différents types d‟arbres de décision flous (base de données utilisée : MIT-BIH).
Pour valider les performances de chaque expérimentation quelques critères ont été utilisés. Nous définissons les notions suivantes :
1- Vrai positif : exemple prédit dans C et appartenant à C.
2- Vrai négatif : exemple prédit dans C et appartenant à C .
3- Faux positif : exemple prédit dans C et appartenant à C .
4- Faux négatif : exemple prédit dans C et appartenant à C.
Considérons une règle de la forme A C
Étape de construction et d’analyse de l’arbre de décision flou
Dans cette partie nous allons commencer par générer l‟arbre de décision flou (lecture de l‟arbre) ensuite analyser ses règles de décision extraites (branches de l‟arbre).
Lecture de l’arbre
Après lecture des caractéristiques de l‟arbre, nous générons deux types d‟arbres :
Arbre complet : sans optimisation.
Arbre élagué : après optimisation par la base de validation avec une tolérance de 0,1
Extraction de règles de classification à partir d’un arbre de décision
L‟avantage principal d‟un arbre de décision flou est l‟interprétabilité des résultats et sa capacité d‟induction des règles de décision, ce qui constitue un intérêt majeur dans un système d‟aide au diagnostic [13].
Les règles sont sous la forme suivante :
« Si A et SEF1 et B est SEF2 et…alors c‟est C1 »
Choix initiaux des modalités floues
1ere expérimentation
Nous avons choisi les modalités floues selon l‟expert humain (cardiologue) en gardant les paramètres d‟entrée présentés dans le tableau suivant :
Où tous les sous ensemble flous (SEF) sont initialisés manuellement
Nous remarquons à partir des histogrammes précédents que les valeurs des tous les paramètres choisis son couverts par les modalités floues à l‟exception du paramètre RR0 qui n‟a pas beaucoup de valeurs représentatives pour le sous ensemble Grand.
Le choix des points modaux est aussi important pour la suite dans la génération de l‟arbre, dans notre cas nous avons choisi les points cas par cas selon la variation des données de chaque paramètre.
Génération de l’arbre complet :
L‟arbre complet généré par FisPro est constitué de 48 branches (48 feuilles). Le gain apporté à chaque feuille est présenté sous forme d‟entropie.
Chaque branche (règles de décision) indique une classe avec un certain degré de pureté par exemple dans les feuilles (10 feuilles) l‟arbre a tranché avec un degré de pureté de 100%.
Pour les autres branches l‟arbre a tranché avec un degré de pureté qui varie entre 0 et 100%.
Ils existent plusieurs cas où l‟arbre a donné une réponse répartie sur les 4 classes (N, V, A, J) , c‟est une situation d‟indécision avec une entropie maximale ce qui confirme d‟une manière claire que malgré le gain d‟information apporté est important mais l‟arbre n‟a pas tranché c’est-à-dire chaque feuille indique une classe avec un faible pourcentage (<50%).
Commentaire :
On remarque que les sept règles n‟ont pas utilisé les paramètres RRO et RRS, ce qui montre que ces paramètres n‟on pas d‟importance dans le diagnostique de l‟expertise humain. Les classe 3(A), classe 1(N) ont étaient reconnues par 3 règles, par contre la classe 2(V) a était reconnue par une règle seulement, Si QRS large alors ESV.