La segmentation automatique du discours peut représenter un intérêt pour l’identification des textes libres. En effet, un texte libre peut être considéré comme un sujet indépendant du reste de la commande vocale. La segmentation du discours consiste en la division automatique d’un flux textuel ou de parole en blocs homogènes reliés à un sujet ([3]). Étant donné une séquence de mots, l’objectif est d’identifier les frontières où il y a un changement de sujet. La segmentation du discours est utilisée dans des applications variées du NLU, comme l’extraction et la recherche d’informations ou la génération de résumés.
La prosodie peut jouer un grand rôle dans la segmentation du discours lorsqu’un flux de parole est concerné. La plupart des modèles théoriques de l’intonation supposent un ou plusieurs niveaux de phrases intonationnelles (segment de discours qui se produit avec un seul contour prosodique), sous lesquels la variation des caractéristiques de tonalité est interprétée. Intuitivement, les phrases intonationnelles d’un énoncé divisent celui-ci en fragments d’information significatifs. Une variation induite à une phrase intonationnelle peut modifier le sens dont les auditeurs seront susceptibles d’attribuer à un énoncé individuel d’une phrase. Enfin, il est démontré que les propriétés prosodiques d’une phrase intonationnelle sont corrélées avec les positions structurelles du discours ([20], [73]).
Hirschberg et Nakatani [21] effectuent l’identification des frontières des phrases intonationnelles à partir d’un ensemble restreint de caractéristiques prosodiques. Ils utilisent un arbre de décision de type CART comme technique d’apprentissage. La procédure de segmentation est entraînée et testée sur un corpus de texte lu. Toutefois, un corpus d’oral spontané produit par des non professionnels est également utilisé, ce qui se rapproche de l’étude de ce mémoire. Les enregistrements d’oral spontané sont transcrits manuellement, incluant les faux départs et autres erreurs de prononciation. Les transcriptions prosodiques de ces enregistrements sont également effectuées manuellement grâce au standard ToBI. Ces transcriptions fournissent aux auteurs une décomposition des extraits de parole en phrases intonationnelles. Plusieurs mesures prosodiques sont utilisées comme mesures prédictives. Ces mesures permettent d’identifier si une trame de 10 msec d’un signal acoustique survient à l’intérieur ou à la frontière entre deux phrases intonationnelles. Cela correspond donc à un classement binaire. Dans leur expérimentation, quatre types d’information prosodique sont utilisés pour chaque trame : un estimé de F0, un indicateur binaire estimant la probabilité de voisement (pvoice), la moyenne de la racine carrée de l’énergie (rms) et la valeur normalisée de la corrélation croisée du pic (ac-peak) afin d’obtenir une autre estimation de F0. Pour ce mémoire, les informations prosodiques ont été extraites automatiquement à partir de Praat ([8]).
Hirschberg et Nakatani développent en plusieurs étapes les modèles permettant ce classement binaire à partir du corpus d’entraînement. Premièrement, un ensemble de caractéristiques prosodiques est identifié, permettant d’obtenir les meilleures performances sur une trame. Cet ensemble se base seulement sur cette trame avec au plus une autre trame en contexte. Ensuite, des modèles pour cet ensemble des meilleures caractéristiques sont entraînés sur chaque locuteur et chaque style du corpus. Ces modèles sont alors testés sur toutes les autres partitions. Cela engendre des modèles modélisant au mieux les autres données du corpus d’entraînement. Dans la seconde étape, les partitions des données d’entraînement sont utilisées pour le modèle du locuteur/style prédisant le mieux les autres données. Cette étape permet de sélectionner un ensemble distinct de caractéristiques contextuelles multi trames, correspondant à une fenêtre variant entre 2 et 27 trames. Ces fenêtres de trames sont alignées sur la trame courante de différentes façons (alignement à gauche, au centre et à droite). La largeur de fenêtre, obtenant les meilleures performances, est retenue à cette étape. À la troisième étape, la meilleure combinaison des caractéristiques est identifiée. Ces caractéristiques sont basées sur les fenêtres à trames simples et multiples. Finalement, ce modèle composé est testé dans une expérimentation, afin d’inférer des structures de discours à partir des caractéristiques prosodiques. Il est ensuite testé dans une autre expérimentation utilisant les frontières prédites de phrases pour des applications de navigation audio.
Le modèle composé final est déterminé suite à l’entraînement. Celui-ci considère les modèles à trames simples et multiples offrant les meilleures performances. Il inclut deux caractéristiques à trames multiples et une caractéristique à trames simples : 15 trames d’une fenêtre centrée de la moyenne normalisée de rms, 19 trames d’une fenêtre alignée à gauche de la moyenne normalisée de F0, et ac-peak de la trame courante seule. Ayant recours à la validation croisée lors de l’entraînement, les performances de l’approche CART varient entre 80% et 93%. L’ajout de caractéristiques à trames multiples améliore la précision de classement de 2% à 5%. Ces caractéristiques représentent l’information du contexte de la trame courante. Cependant, aucune caractéristique basée sur une fenêtre alignée à droite n’est utile dans ce modèle composé final. L’expérimentation entière suggère que l’identification de phrases intonationnelles par des moyens purement automatique est possible. Cela semble prometteur pour l’identification automatique des textes libres.
D’autres auteurs s’intéressent à la combinaison de la prosodie et des mots pour la segmentation automatique du discours. Shriberg et al. [68] utilisent l’arbre de décision CART et un HMM pour combiner les indices prosodiques avec le modèle de langage. Selon leurs résultats, le modèle prosodique est équivalent ou supérieur au modèle de langage. De plus, ce modèle prosodique requiert moins de données d’entraînement. Un point intéressant est que ce modèle ne nécessite pas d’annotations manuelles de la prosodie. Comme pour les études discutées précédemment, les performances du système s’améliorent en combinant l’information prosodique et lexicale. Pour cette section du chapitre, l’intérêt se porte seulement sur leur modèle prosodique.
Leur travail comporte trois tâches : la segmentation de phrases sur le corpus Broadcast News, la segmentation de phrases sur le corpus Switchboard et la segmentation de sujet sur le corpus Broadcast News. L’intérêt de cette section se situe davantage sur la segmentation de sujets. Comme pour ce mémoire, le corpus Broadcast News contient principalement des monologues. Cependant, ce corpus est constitué de textes lus contrairement au corpus Switchboard qui est constitué d’oral spontané. Toutefois, Switchboard est constitué de dialogues et contient souvent des chevauchements de locuteurs. Pour ce mémoire, les commandes vocales étaient toujours initiées par un seul locuteur. Les caractéristiques de pauses et de hauteur sont hautement informatives pour la segmentation de Broadcast News. Pour Switchboard, les durées et les indices basés sur les mots sont dominants. Par conséquent, une attention doit tout de même être portée sur la segmentation de phrases.
Ainsi, les auteurs constatent que les caractéristiques de durée et celles extraites du modèle du langage sont particulièrement utiles pour la segmentation de la conversation naturelle. D’autres indices prosodiques inclus les pauses, les changements dans l’intervalle de la hauteur et de l’amplitude, la déclinaison globale de la hauteur, la mélodie et la distribution de la tonalité aux frontières, et la variation du débit de parole. Par exemple, les frontières de phrases et de paragraphes ou les frontières de sujets sont souvent marquées. Ce marquage se caractérise par une combinaison d’une longue pause, précédée d’une frontière finale de faible tonalité, suivi d’une réinitialisation de l’intervalle de la hauteur, parmi d’autres caractéristiques ([44], [10], [11]).
Pour toutes les tâches abordées, les auteurs utilisent des caractéristiques prosodiques très locales. Les auteurs font ce choix pour des raisons pratiques. Ce choix a également été considéré pour ce mémoire. Pour chaque frontière entre deux mots, précisément le type de frontière d’intérêt, les auteurs s’intéressent aux caractéristiques prosodiques du mot précédant et suivant immédiatement la frontière. Alternativement, une fenêtre de 20 trames est utilisée précédant et suivant cette frontière. Dans le cas des frontières contenant une pause, la fenêtre s’étend vers l’arrière du début de cette pause ainsi que vers l’avant de sa fin. Une région peut-être plus efficace, non considérée par les auteurs, serait d’étendre la fenêtre vers l’arrière et vers l’avant jusqu’à ce qu’une syllabe accentuée soit atteinte. Cette idée est particulièrement intéressante pour les locuteurs anglophones, dont s’intéresse également et exclusivement ce mémoire. Contrairement à la langue française, la langue anglaise est considérée comme une langue d’accentuation variable. Toutefois, pour des raisons pratiques, cette idée n’a pas été considérée pour ce mémoire.
Les caractéristiques extraites concernent la durée des pauses et des phonèmes ainsi que les informations sur la hauteur et sur la qualité de la voix. Les pauses sont extraites sur la frontière entre deux mots. Les autres caractéristiques sont extraites principalement à partir du mot (ou de la fenêtre) précédent la frontière (ce qui rappelle les résultats de Hirschberg et Nakatani [21] avec leur modèle composé final discuté précédemment). Les travaux antérieurs démontrent que les caractéristiques précédant les frontières détiennent plus d’information pour ces tâches par rapport au flux de parole suivant les frontières [64]. Il est intéressant de constater que les auteurs décident de ne pas s’intéresser aux caractéristiques basées sur l’énergie ou l’amplitude. En effet, ces caractéristiques sont moins fiables et largement redondantes face à celles des durées et des hauteurs. Ces deux observations ont orienté l’étude de ce mémoire.
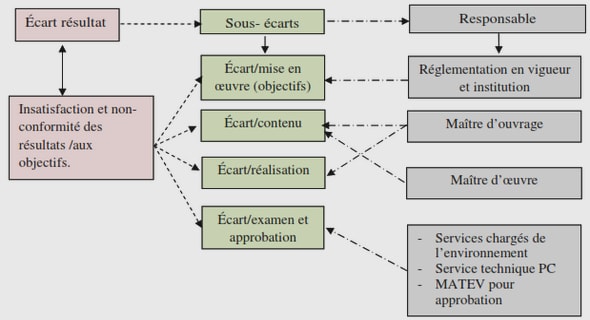
INTRODUCTION |