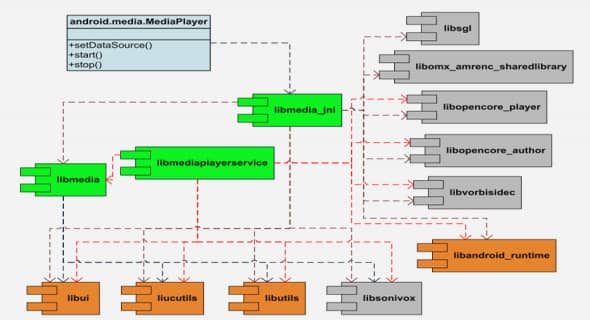
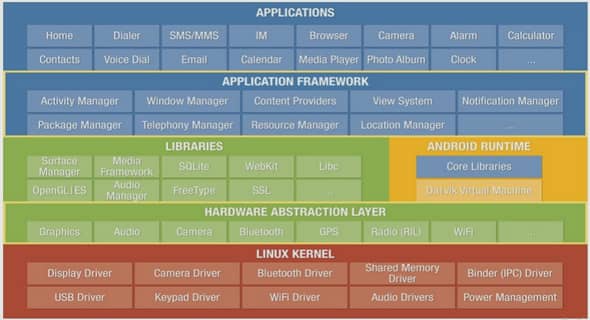
Background
The concept of « algorithmic skeleton » was introduced by Cole [Col91] [Col04] and elaborated by Skillicorn [ST98] [McC10]. While speci_c to computation con_guration, this concept is similar to the concept of design pattern [MSM04]. Therefore, we use the term « skeleton » and « parallel pattern » interchangeably to indicate a recurrent execution con_guration which speci_es a speci_c pattern of computation, coordination and data access. A set of characteristics workloads was identi_ed in the View from Berkeley [ABD+09] as « motifs » or « dwarves ». These « motifs » consist of a set of di_erent types of execution patterns [McC10] which exposed a set of common sequential and parallel patterns. While the di_erent types of patterns were presented separately, in most applications, a variety of patterns are composed linearly or hierarchically to describe a structured algorithm [BMA+02] [TSS+03] [SG02]. In the early 1970s,it was noted that composing control _ow of serial program using a small set of control _ow patterns (sequence, selection, iteration and recursion) could make them easier to understand.
This structured programming approach resulted into the elimination of « goto » from most programs despite a lot of controversy [Dij79]. In the last decades, structured control _ow has been so widely accepted that « goto » is either deprecated or disappeared from most modern languages [McC10] [MRR12]. Analogously, structured parallel programming with parallel pattern is a promising approach which can hide the low level threading and synchronization details while displaying an understandable structured representation of parallel programs. Threads are similar to « goto » in their lack of _exibility and structure [Lee06]. Similarly to « goto », use of concurrent threads with random access to data make program di_cult to decompose into di_erent parts which form a structured program where di_erent parts are clearly isolated and do not interfere with each others. Functional programming can be seen as an alternative. However most modern mainstream programming languages are not functional. Moreover, many algorithms such as graph problems can be di_cult to express using pure functional languages. However, functional programming can be considered as a speci_c case of structured parallel programming where only a subset of the parallel patterns is used. Collective languages is another class of languages which allows explicit expression of parallel operations over large collections of data. Collective languages can be implemented using either functional or imperative languages. Mainstream languages are often used to implement collective operations as libraries which o_er a set of built-in operations. For example, NESL [BHC+93] [Ble96] is a collective functional language while FORTRAN 2003 is an imperative language which o_er a set of built-in collective operations. Ct and RapidMind [MWHL06] are imperative languages which are based on collective operations. Structured parallel programming with patterns can be implemented by designing new languages, by extending existing mainstream languages, by designing code generators [Her03] or by using the traditional mainstream languages to provide libraries of parallel patterns.
A Skeleton Frameworks Classi_cation Before presenting the skeleton frameworks, a functional classi_cation of them can be useful to distinguish the common approaches used for implementing algorithmic skeletons. Skeleton frameworks can be classi_ed according to the used programming paradigms such as in [GVL10] where four approaches are clearly identi_ed: Coordination, Functional, Object-Oriented, Imperative. The later classi_cation is mainly based on the language of implementation of skeleton frameworks which is a judicious criterion of classi_cation. In order to make this language aspect of the classi_cation even clearer, we propose the following classi_cations:
• New Languages : This class of frameworks advocates the introduction of new high-level coordination languages that allows programmer to describe the program structure through algorithmic skeletons. The coordination language is then translated into a host language or the execution language responsible of interacting with execution infrastructure. The Structured Coordination Language (SCL) [DT95], the Pisa Parallel Programming Language (P3L) [BK96], the llc language [DGRDS03] and Single Assignment C language (SCL) [Gre05] are examples of programming models that introduces new coordination languages to describe algorithmic skeletons at high level. Source-to-source compilers are often used to translate the skeletal description into host language that can be compiled into executable code using traditional compilers. This approach su_ers from a major disadvantage which is the need to learn new language and the use of dedicated compiler and tools that may requires long development time to reach the maturity and performance of traditional compilers.
• Language Extension : Instead of introducing new skeletal languages, this approach relies on syntax extension of existing languages to widen their capabilities with a parallel programming extension. Eden [LOmPnm05] and the Higher-Order Divide-and-Conquer language (HDC) [HL00] follow this approach by extending the Haskell language with parallel extension to allow skeletal programming. HDC translates the target program into C program with the MPI environment while Eden uses the Glasgow Haskell Compiler. Similarly to the previous approach, language extension-based approach exposes the need to learn the syntax extensions and relies on intermediate compilers or translators to generate the host language code that can be compiled into executable machine code.
• Traditional Language : In order to avoid introducing new languages or extending existing one, this approach tries to exploit traditional language to expose a friendly programming interface that aims to easing skeleton description and composition. Such skeleton framework are often designed as libraries for popular language. Depending on the target language, the programming interface can be designed using object-oriented paradigms or imperative paradigms.
• Object-Oriented : In Object-oriented languages, skeletons are often encapsulated into classes and exploit the abstraction of the object paradigms. C++ and Java are the most used host language since they are very popular. We note that auxiliary libraries and environment such as POSIX Threads and MPI may be used to support the execution infrastructure. The Munster Skeleton library (Museli) [CPK09], the Skeleton in Tokyo SkeTO [MIEH06] and the Malaga-La Lagune-Barcelona (Mallba) library [AAB+02] are examples of C++/MPI skeletons that implement respectively task-parallel, data-parallel and resolution skeletons. The Java Skeleton (JaSkel) [FSP06], Calcium [CL07], muskel [ADD07], Lithium [ADT03] and Skandium [LP10] provide a set of skeletons as Java classes.
Skeleton Frameworks Description
In this paragraph, skeleton frameworks are brie_y presented then their individual features are described: ASSIST: ASSIST is a programming environment for parallel and distributed programs. It is based on a structured coordination language that use the parallel skeleton model. ASSIST represents parallel programs as a graph of software modules [Van02]. The graph itself is a software module that speci_es the interactions between a set of modules composing the application. The interacting modules can be parallel or sequential. Sequential modules can be written in C, C++ or Fortran while parallel modules are programmed using a dedicated ASSIST parallel module named « » [GVL10]. In order to decouple the compiler and run time layer from the actual grid infrastructure, ASSIST exposes a Grid Abstract Machine (GAM) layer. Programming in ASSIST can be peculiar since skeletons are not pre-de_ned, and the programmer is responsible of specifying them by specializing the generic parmod construct. Calcium and Skandium : Calcium [CL07] provides a set of task and data parallel skeletons in a Java library. Skeletons are nestable and are instantiated using parametric objects. Calcium supports skeleton execution on di_erent shared and distributed infrastructures such as symmetric multiprocessing platforms and cluster platforms. Calcium provides a performance tuning model which helps programmer to locate bugs and performance bottlenecks in his code. Additionally, Calcium provides a transparent algorithmic skeleton _le access model for data intensive applications [CL08]. More recent researches of this group has centered on a complete re-implementation of Calcium named Skandium.
The new implementation is focused on easing parallel programming on multicore architectures [LP10] [GVL10]. OSL : The Orléans Skeleton Library (OSL) is a C++ skeleton library which is based on the Bulk Synchronous Parallel (BSP) model of parallel computation. OSL provides a collection of data parallel skeletons. OSL is implemented on top of MPI and uses meta-programming techniques to o_er a good e_ciency. OSL aims to provide an easy-to-use library which allows simple reasoning about parallel performances based on a simple and portable cost model [JL09]. Eden : Eden [LOmPnm05] extends the Haskell functional language by providing support of parallel shared and distributed memory environment. In Eden, parallel programs are organized as set of processes explicitly de_ned by the programmer. These processes communicates with each other implicitly [BLMP97] through unidirectional single-writer-single-reader channels. The programmer is responsible of de_ning data dependencies of each process. Eden de_nes a process model that allows process granularity control, data distribution control and communication topology de_nition. The concept of the implementation skeleton that describe the parallel implementation of a skeleton independently from the underlying architecture has been introduced by Eden [KLPR01]. Eden supports task and data parallelism through a set of skeletons that are de_ned on top the process abstraction layer.
Contents |