Définition du système de réputation
La réputation, en général, est une information utilisée pour porter un jugement de valeur sur une chose ou un bien dans son contexte pendant une période limitée.
La première définition des systèmes de réputation : Les systèmes de réputation (Reputation Systems (RSs)) sont l’un des mécanismes établis pour aider les consommateurs à prendre une décision concernant des achats en ligne Gutowska & Sloane (2009).
La deuxième définition des systèmes de réputation : Les systèmes de réputation (RS) sont un système qui collecte, distribue et rassemble les informations en retour (feedback) sur le comportement des participants.
Définition de l’analyse de sentiments
L’analyse du sentiment (Sentiment Analysis (SA)), connue également sous le nom de « extraction d’opinion » (Opinion Mining (OM)), est le domaine d’étude qui analyse les opinions, les évaluations et les sentiments envers des entités telles que les services, les individus, les enjeux, les sujets, et leurs attributs Liu (2012) .
Système de réputation pour les applications du commerce électronique (e commmerce)
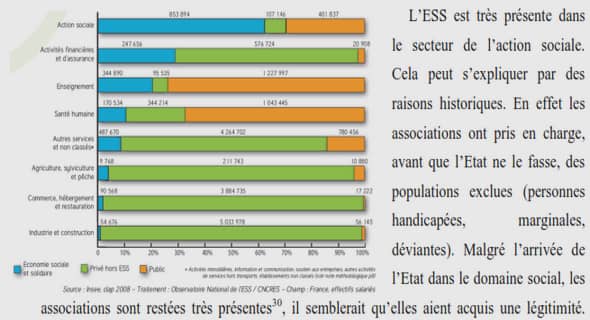
La réputation des places de marché (marketplace) du commerce électronique joue désormais un rôle essentiel dans la décision de lancer une transaction et la tarification des produits ou services sur les places de marché en ligne comme eBay.com. Les informations en retour (« Feedback ») d’eBay calculent la réputation d’un utilisateur comme la somme de ses évaluations à vie. Les profils de réputation sont conçus pour prédire les performances futures et aider les utilisateurs. Les vendeurs ayant une excellente réputation peuvent exiger des prix plus élevés pour leurs produits tandis que les détenteurs de mauvaise réputation attirent moins d’acheteurs Resnick & Zeckhauser (2002). De nombreuses études telles que Jøsang et al. (2006); Liu et al. (2011); Ehsaei (2012) proposent des architectures de systèmes de réputation de confiance (Trust Reputation Systems(TRS)) ainsi que différentes méthodes pour calculer le score de la réputation liée à un produit. D’autre part, peu de travaux de recherche sur les TRS ont pris en compte l’analyse sémantique des informations en retour (« feedback ») et surtout le degré de confiance de l’utilisateur dans le calcul des scores de confiance des produits.
Revues textuelles pour fournir un avis détaillé sur le produit
La plupart des modèles de réputation disponibles dépendent des données numériques disponibles dans différents domaines; un exemple est celui de l’évaluation (rating) dans le commerce électronique. En outre, la plupart des modèles de réputation se concentrent uniquement sur les évaluations globales des produits, sans tenir compte des avis fournis par les clients Xu et al. (2016). D’autre part, la plupart des sites Web permettent aux consommateurs d’ajouter des avis textuels pour donner un opinion détaillée sur le produit Tian et al. (2014a), Tian et al. (2014b). Ces avis sont mis à la disposition des consommateurs, qui dépendent de plus en plus des avis plutôt que des évaluations. Grâce aux modèles de réputation qui pourraient utiliser les méthodes de SA pour extraire les opinions des utilisateurs et utiliser ces données dans le système de réputation. Ces informations peuvent inclure les opinions des consommateurs sur différentes caractéristiques Abdel-Hafez & Xu (2013) Abdel-Hafez et al. (2012). Il existe un grand nombre d’études sur l’exploration de textes (« text mining ») pour analyser les informations en retour ou les avis des clients. L’étude menée par Hu & Liu (2004) et Gupta et al. (2009) intègre l’utilisation du traitement du langage naturel pour extraire des paires de noms et d’adjectifs en phrases par le biais du marquage des parties du discours (Parts-of-speech (POS) tagging) et de l’exploration des règles d’association sur les avis des consommateurs de produits afin de trouver des caractéristiques fréquentes et peu fréquentes pour vérifier les caractéristiques du produit. Une autre étude de Chinsha & Joseph (2014) a réalisé une exploration de texte et de règles linguistiques pour analyser les avis et détecter l’orientation des opinions.
Problèmes liés à l’analyse du sentiment
De nos jours, l’analyse de sentiments est un domaine de recherche très populaire. De nombreux travaux sont réalisés, mais il n’existe pas encore de méthode suffisamment bonne pour classer les sentiments. Pour de nombreux auteurs, la moyenne des résultats est légèrement supérieure à 85%, mais cela ne suffit pas si nous avons besoin de résultats plus précis.
L’objectif principal de l’analyse des sentiments est d’analyser les avis et de tester les scores des sentiments. Cette analyse est divisée en trois niveaux Thomas (2013) : niveau document Yessenalina et al. (2010), niveau phrase Farra et al. (2010), niveau mot/termeEngonopoulos et al. (2011) ou niveau aspect Zhou & Song (2015). Les processus séquentiels sont l’évaluation de l’analyse des sentiments et la détection de la polarité des sentiments.
Plusieurs enjeux doivent être pris en compte lors de la conduite du SA Vinodhini & Chandrasekaran (2012). Deux enjeux majeurs sont abordés. Premièrement, le point de vue (ou l’opinion) observé comme négatif dans une situation peut être considéré comme positif dans une autre situation. Deuxièmement, les gens n’expriment pas toujours leurs opinions de la même manière. La plupart des techniques de traitement de texte courantes utilisent le fait que des modifications mineures entre les deux fragments de texte ne sont pas susceptibles de changer le sens réel Vinodhini & Chandrasekaran (2012).
L’analyse de sentiments des données des médias sociaux a également été appliquée pour évaluer les produits, comme expliqué par les auteurs de Oelke et al. (2009). Chaque auteur propose ses propres méthodes pour évaluer les opinions. Malheureusement, la plupart des outils ou algorithmes d’analyse de sentiments sont encore au stade de la recherche. Jusqu’à présent, il n’existe aucun algorithme qui puisse fournir des résultats 100 % précis pour l’analyse de sentiments. Il y a encore plusieurs débats entre différents chercheurs qui tentent de prouver que leur solution est plus parfaite que les autres.
Détection des faux avis (« Fake Reviews »)
Le problème principal pour identifier empiriquement les faux avis est que nous ne pouvons pas observer directement si un avis est faux. La situation est encore compliquée par l’absence de norme unique pour déterminer ce qui rend un avis « faux ».
Le filtrage et l’identification des faux avis ont une signification substantielle Jindal & Liu (2008). Dans Moraes et al. (2013) les auteurs ont proposé une technique pour catégoriser un avis textuel sur un seul sujet. Le niveau de document classé par sentiments est appliqué pour indiquer qu’un sentiment est négatif ou positif. Les techniques d’apprentissage supervisé comprennent deux phases, la sélection et l’extraction de la catégorisation des avis en utilisant des modèles d’apprentissage tels que le MVC. Extraire la meilleure et la plus précise approche, et simultanément catégoriser le texte des commentaires écrits des clients en opinions négatives ou positives. Il s’agit d’un domaine de recherche majeur qui a attiré l’attention. Bien qu’il soit encore dans une phase d’introduction, il y a eu beaucoup de travail lié à plusieurs langues Liu et al. (2005) Fujii & Ishikawa (2006) Ku et al. (2006). Notre travail a utilisé plusieurs algorithmes d’apprentissage supervisé tels que SVM, NB, KNN-IBK et DT-J48 pour la classification de sentiments des textes afin de détecter les faux avis.
Un problème récemment apparu avec les avis en ligne est que certains avis en ligne sont faux. Bien que la plupart des plateformes en ligne disposent de leurs propres algorithmes de détection des faux avis Diesner et al. (2017), ces algorithmes ont parfois une portée limitée et ne filtrent que 16 % des faux avis publiés Luca & Zervas (2016). Il est donc clairement nécessaire d’améliorer les algorithmes existants et d’élaborer de nouvelles approches. Certaines études ont tenté de le faire (Diesner et al. (2017); Zhang et al. (2016)). À cette fin, plusieurs méthodologies ont été utilisées, dont certaines seront examinées dans la suite de cette thèse.
INTRODUCTION |