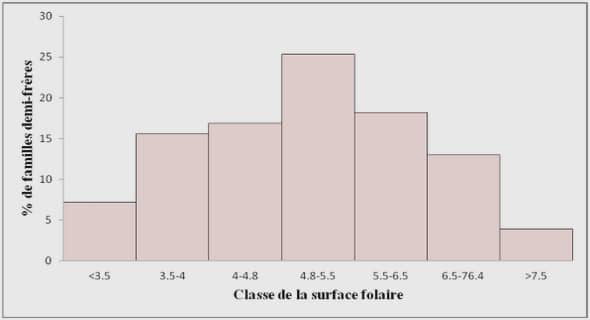
Distance dépendante de la classe
Introduction
La question évoquée dans cette thèse « comment décrire et prédire d’une manière simultanée ? » conduit à un nouvel aspect de l’apprentissage. Ce dernier est appelé « le clustering prédictif » (voir Algorithme 2 du Chapitre 2). Les algorithmes appartenant à ce type d’apprentissage peuvent être catégorisés en fonction des besoins de l’utilisateur. La première catégorie regroupe l’ensemble des algorithmes de clustering « modifiés » permettant de prédire correctement la classe des nouvelles instances sous contrainte d’avoir un nombre minimal de clusters dans la phase d’apprentissage (voir la partie gauche de la figure 3.1). Cette catégorie met l’accent sur l’axe de prédiction tout en « ignorant » l’axe de description. La deuxième catégorie regroupe l’ensemble des algorithmes permettant tout d’abord de découvrir la structure interne complète de la variable cible, puis munie de cette structure prédire correctement la classe des nouvelles instances (voir la partie droite de la figure 3.1). Contrairement aux algorithmes de la première catégorie, ces algorithmes cherchent à réaliser un compromis entre la description et la prédiction sans privilégier un axe par rapport à l’autre. Les algorithmes classiques de clustering visent à subdiviser l’ensemble des instances en un certain nombre de groupes (ou clusters) de telle sorte que les instances au sein de chaque cluster doivent être similaires entre elles et dissimilaires des instances des autres clusters. Pour l’algorithme des K-moyennes, cette notion de similarité/dissimilarité est représentée par une distance ou une métrique. Deux instances sont considérées comme similaires si et seulement si elles sont proches en termes de distance (la distance la plus utilisée est la distance Euclidienne). En revanche, dans le cadre des K-moyennes prédictives, la similarité entre deux instances n’est pas uniquement liée à leur proximité en termes de distance mais elle est également liée à leur ressemblance en termes de leur classe d’appartenance : deux instances sont similaires si et seulement si elles sont proches en termes de distance et appartiennent à la même classe. De ce fait, l’utilisation d’une distance ne prenant pas en compte l’information de la classe reste insuffisante : deux instances proches en termes de distance vont être considérées comme similaires indifféremment à leur classe d’appartenance et donc la probabilité que l’algorithme les regroupe ensemble sera élevée. À titre d’exemple, les instances appartenant aux deux groupes A et B de la figure 3.1. Pour permettre à l’algorithme de K-moyennes classique de prendre en considération l’information donnée par la variable cible et ainsi améliorer sa performance prédictive, deux voies peuvent être exploitées. La première voie consiste à modifier la fonction du coût de l’algorithme des K-moyennes afin de proposer une nouvelle fonction objectif capable d’établir une certaine relation entre la similarité classique pour les instances et leur classe d’appartenance. À titre d’exemple, Peralta et al. ont défini dans [85] une nouvelle fonction objectif qui s’écrit sous forme 48 Chapitre 3. Distance dépendante de la classe d’une combinaison convexe entre la fonction objectif usuelle de l’algorithme de K-moyennes et sa version supervisée. Cependant, cette fonction nécessite un paramètre utilisateur pour équilibrer les deux scores ce qui requière une phase d’ajustement (validation croisée pour trouver la bonne valeur du paramètre). La deuxième voie consiste à incorporer l’information donnée par la variable cible dans les données sans modifier la fonction du coût de l’algorithme des K-moyennes classique. Dans ce chapitre, on s’intéresse exclusivement à l’étude de la deuxième voie. La démarche suivie pour incorporer l’information donnée par la variable cible dans les données doit impérativement respecter le point crucial qu’un algorithme des K-moyennes prédictives doit posséder, à savoir, l’interprétabilité des résultats (voir la section 2.6.1 du chapitre 2). L’intérêt de cette démarche est d’une part de rendre la tâche d’interprétation des résultats plus aisée pour l’algorithme des K-moyennes standard. D’autre part, elle permet de modifier indirectement la fonction du coût de l’algorithme des K-moyennes standard dans le but de l’aider à atteindre l’objectif des K-moyennes prédictives. Pour atteindre cet objectif, la méthode recherchée doit être capable de générer une distance, dite supervisée, permettant d’établir une certaine relation entre la similarité classique entre les instances et leur classe d’appartenance. Dans ce chapitre, on suppose qu’une estimation des distributions uni-variées conditionnelles aux classes P(X |C) pourrait aider l’algorithme des K-moyennes standard à atteindre l’objectif mentionné ci-dessus. Parmi les méthodes permettant cette estimation probabiliste, on choisit de s’orienter vers les méthodes les plus interprétables, à savoir : les méthodes supervisées de discrétisation pour les variables continues et les méthodes supervisées de groupage en modalités pour les variables catégorielles. Ces méthodes cherchent à trouver la partition des valeurs ou des modalités qui donne le maximum d’informations sur la répartition des J classes connaissant les intervalles de discrétisation ou les groupes de modalités. A titre d’exemple, la figure 3.2 présente la discrétisation supervisée des deux variables continues (Variable 1 et Variable 2) pour un jeu de données caractérisé par la présence de deux classes. Pour cet exemple illustratif, la variable 1 est divisée en 3 intervalles tandis que la variable 2 est divisée en 4 intervalles.
Distance dépendante de la classe
L’incapacité de l’algorithme des K-moyennes standard à atteindre l’objectif des algorithmes du clustering prédictif s’illustre essentiellement dans le cas de la non corrélation entre les classes et les clusters. C’est le cas où au moins l’une des régions denses est caractérisée par la présence d’au moins deux classes. La figure 3.5 présente un exemple illustratif de la présence d’une région dense ({A∪B}) contenant deux classes. En effet, l’algorithme des K-moyennes standard considère deux instances proches en termes de distance comme similaires indifféremment de leur classe d’appartenance. Dans le cadre du clustering prédictif, ceci peut générer une détérioration au niveau de la performance prédictif du modèle.Pour surmonter ce problème, l’incorporation de l’information donnée par la variable cible dans les données s’avère nécessaire. Cette incorporation pourrait aider l’algorithme des K-moyennes standard à prendre en considération l’appartenance des instances aux classes. Dans ce chapitre, on suppose que l’estimation des distributions uni-variées conditionnelles aux classes (P(X |C)) pourrait aider cet algorithme à atteindre l’objectif souhaité.
Estimation des densités conditionnelles aux classes
Comme signalé dans la section 2.6.1 du chapitre 2, les algorithmes du clustering prédictif sont des algorithmes qui fournissent des résultats facilement interprétables par l’utilisateur. De ce fait, lors de la recherche de la méthode permettant d’insérer l’information donnée par la classe cible dans les données, la contrainte d’interprétabilité doit impérativement être respectée. Parmi les méthodes les plus « interprétables » permettant une estimation des densités conditionnellement aux classes, on trouve les méthodes de discrétisation supervisées pour les variables continues et le groupage en modalités pour les variables catégorielles. Pour les variables continues, la discrétisation supervisée consiste à diviser le domaine de chaque variable en un nombre fini d’intervalles identifiés chacun par un code Il , l ∈ {1, . . . , t}. Elle vise à trouver la partition des valeurs qui donne le maximum d’informations sur la répartition des J classes connaissant l’intervalle de discrétisation Il , l ∈ {1, . . . , t}. Cette partition optimale est décrite par la table de contingence comme illustrée dans le tableau 3.1
Dans la littérature, il existe une variété de méthodes de discrétisation ou de groupage en modalités selon la nature des variables descriptives. Les méthodes les plus répandues sont notamment MODL, ChiSplit, BalancedGain et l’arbre de décision C4.5 ou CART . Le choix de la méthode qu’on va utiliser sera conditionnée par certains points, à savoir : la robustesse, la rapidité, la précision et finalement la minimisation des connaissances a priori (i.e., pas (ou très peu) de paramètres utilisateur). Parmi les méthodes de discrétisation et de groupages en modalités qui respectent l’ensemble de ces points, on trouve la méthode MODL, proposé par Boullé dans . Il est important de noter que ce choix n’est pas une obligation. D’autres méthodes peuvent également être utilisées à condition qu’elles respectent les points cités ci-dessus. L’approche MODL considère la discrétisation comme un problème de sélection de modèle. Ainsi, une discrétisation est considérée comme un modèle paramétré par le nombre d’intervalles, leurs bornes et les effectifs des classes cibles sur chaque intervalle. La famille de modèles considérée est l’ensemble des discrétisations possibles. Cette famille est dotée d’une distribution a priori hiérarchique et uniforme à chaque niveau. Pour plus de détails sur cette approche voir. Après cette étape dite étape de préparation supervisée des données, chaque variable est représentée par une table de contingence. Pour pouvoir exploiter les connaissances utiles existant dans ces tables, la recherche d’une méthode de recodage s’avère nécessaire. Cette méthode doit être capable de générer une distance dépendante de la classe permettant d’établir une certaine relation entre la similarité usuelle et le comportement des instances vis-à-vis de la classe cible. Une façon permettant une exploitation aisée des tables de contingence est de considérer l’appartenance des valeurs de chaque instance aux intervalles de discrétisation ou aux groupes de modalité selon la nature des variables descriptives. Cette approche est appelée dans ce qui suit Binarization (BIN-BIN).
Binarization (BIN-BIN)
Distance de Hamming
L’approche la plus intuitive permettant d’exploiter les informations données par les tables de contingences est la considération de l’appartenance des valeurs de chaque instance aux intervalles de discrétisation ou aux groupes de modalités (à titre d’exemple, voir la figure 3.3). Il s’agit ici de transformer chaque variable en t variables booléennes ; où t est le nombre d’intervalles (ou groupes de modalités) généré par la méthode de discrétisation (ou de groupage en modalités). Cette opération de transformation est basée sur un recodage disjonctif complet : la variable synthétique prend 1 comme valeur si la valeur de la variable d’origine appartient à l’intervalle en question et elle prend zéro comme valeur dans le cas contraire. À titre d’exemple, la variable 1 du jeu de données présenté dans la figure 3.6 est transformée en 3 (nombre d’intervalles : ]−∞, a],]a, b] et ]b, +∞]) variables booléennes ({1, 0, 0}, {0, 1, 0} et {0, 0, 1}) avec {1, 0, 0} signifie que la valeur de la variable d’origine appartient au premier intervalle.