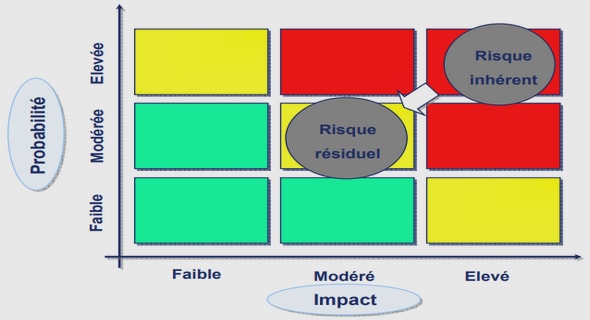
Évaluation de la méthodologie de placement sur GPU
Nous avons détaillé dans le chapitre 3 notre méthodologie de portage d’algorithmes sur accélérateurs de type GPU. Celle-ci permet, à partir d’un algorithme séquentiel, de transformer certains nids de boucles en kernels. Pour cela, nous avons défini trois critères de placement portant sur la structure des nids de boucles, la taille de leur domaine d’itéra- tions ainsi que leurs empreintes mémoire. En complément, nous avons défini un ensemble de transformations de code visant à améliorer le nombre de nids de boucles candidats mais aussi la qualité du placement sur GPU. Afin d’alimenter ce processus de placement, plusieurs analyses statiques sont utilisées. Elles permettent de générer une représentation graphique du code facilitant le déroulement de cette méthodologie. Enfin, les analyses dy- namiques permettent de vérifier que chaque kernel généré engendre bien un gain en terme de temps d’exécution. Dans ce chapitre, nous évaluons cette méthodologie de placement sur GPU. Dans un premier temps, nous introduisons dans la section 4.1 les architectures utilisées. Nous présentons ensuite dans la section 4.2, les deux applications ayant servi à l’évaluation de notre méthodologie. Enfin, nous détaillons les résultats pour ces deux applications dans les sections respectives 4.3 et 4.4. Nous évaluons en particulier les analyses statique et dynamique, les critères de placement ainsi que les transformations de code.
Architectures expérimentales utilisées
Nous avons utilisé deux architectures GPU Nvidia pour les expérimentations. Ce choix est justifié, dans le chapitre 1, par la présence forte de Nvidia dans le secteur industriel. Ce concepteur offre des solutions pour une large gamme d’application telles que l’embarqué ou le calcul scientifique. L’évaluation de notre méthodologie compare les résultats obtenus pour une architecture GPU « classique », sur une plateforme de type workstation (Endicott), avec ceux d’une architecture GPU basse consommation, sur une plateforme embarquable (Jetson TX1).Endicott est une workstation, équipée d’un processeur Intel 64 bits de génération Has- well. Il s’agit d’un Core i7 4770s composé de 4 cœurs physiques et de 8 cœurs logiques grâce à la technologie d’HyperThreading. Sa fréquence de fonctionnement nominale est de 3.1 GHz et peut être augmentée grâce à la technologie Turbo Boost à 3.9 GHz sur des périodes de temps réduites. Sa puissance de calcul maximale pour des opérations flot- tantes simple précision est de 499, 2 GFlops. Son Thermal Design Power (TDP) est de 65 W. Enfin sa bande passante mémoire théorique est de 25, 6 GB.s Cette station de travail est aussi équipée d’un GPU Quadro K2000 développé par Nvidia. Cette carte est basée sur une architecture Kepler [129] GK107. La K2000 intègre deux unités Next Generation Streaming Multiprocessor (SMX) (visibles dans la figure 4.1) de 192 cœurs portant ainsi le total à 384 cœurs Cuda par processeur. La puissance de calcul maximale pour les opérations flottantes simple précision est de 732, 67 GFlops. La K2000 embarque 2 GB de mémoire dédiée dont la bande passante maximale est de 64 GB.spour un bus mémoire de 128 bits. Enfin, le TDP de ce GPU est de 51W.
La Jetson TX1 est une plateforme d’évaluation conçue par Nvidia pour des applications embarquées. Elle intégre un processeur basse consommation Tegra X1 [121] basé sur le SOC T210 de la marque. Ce dernier embarque quatre cœurs ARM A57 cadencés à 1.9 GHz. Afin de réduire la consommation énergétique globale du SOC T210, les cœurs A57 peuvent être désactivés pour utiliser en remplacement quatre cœurs ARM A53 cadencés à 1.3 GHz. La sélection des cœurs A57 ou A53 sera déclenchée, à l’initiative exclusive du processeur, en fonction du taux d’occupation de ces ressources. La puissance de calcul maximale est alors de 60, 8GFlops.processor (SMM) spécifique à cette architecture. Chacun d’entre-eux est composé de 128 cœurs CUDA dont la fréquence de fonctionnement est de 1GHz. Deux unités SMM sont présentes dans le processeur de la Tegra X1 pour un total de 256 cœurs CUDA. La puis- sance de calcul maximale pour la partie GPU est de 512 GFlops pour des opérations flottantes simple précision.