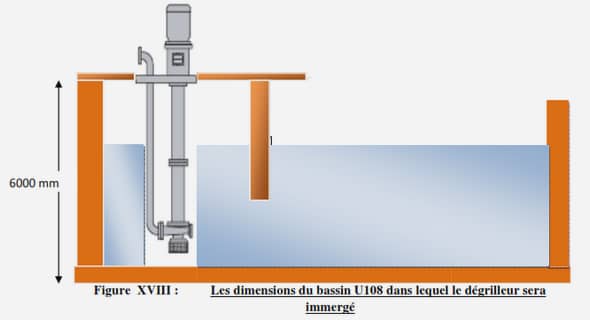
Evaluation des flux à partir de suivis discrets
Calcul des flux et de leurs incertitudes à partir de suivis discrets
Les méthodes de calcul des flux sont un domaine en plein développement grâce aux moyens de calculs toujours plus performants, aux séries de plus en plus longues, donc plus informatives et à l’inventivité des chercheurs. Certaines études de synthèse ou comparatives marquent de réelles avancées telles que : Walling et Webb, 1981, Walling, 1984, Ferguson, 1986, Phillips et al.., 1999, Moatar et Meybeck, 2005. 1.2.1 Catégories de méthodes de calcul Walling et Webb (1977) sont parmi les premiers à s’intéresser aux incertitudes sur l’évaluation des flux de matières, notamment MES, et a avoir proposé une terminologie suite à des tirages Monte-Carlo. Les méthodes de calcul ont été classées différemment selon les auteurs : Walling et Webb (Méthode d’interpolation ou de moyenne et d’extrapolation ou de régression), Tim Cohn, 1995, dans le rapport de l’USGS classe ces méthodes en deux catégories principales : i) les méthodes permettant d’estimer les concentrations en continu, qui consiste à estimer les concentrations manquantes par des relations empiriques en faisant intervenir le débit ; ii) les méthodes permettant une estimation directe notamment en calculant les flux à partir d’un échantillonnage stratifié (Verhoff et al.., 1980 ; Thomas et Lewis, 1995). Cependant c’est en 1999 que Phillips et al.., comparent un panel de 22 méthodes de calculs pour évaluer le flux de MES sur deux rivières britanniques : la rivière Ouse à Skelton (3 315 km²) et la rivière Swale à Catterick Bridge (499.3 km²) dans le cadre du programme River and Coastal Research in the Land Ocean Interaction Study (LOIS) ; (Wilkinson et al., 1997). C’est à l’heure actuelle, l’étude comparant le plus grand nombre de méthodes. Dans ce travail, Phillips et al. ont divisé les 22 méthodes en deux catégories (tableau 1- 2): i) les méthodes d’extrapolations basées sur la reconstitution des concentrations par des régressions logarithmiques concentrations-débits (M1 à M12), ii) les méthodes d’interpolations basées sur des valeurs moyennes de concentration et de débit (M13 à M22). Le détail de ces méthodes est décrit en Annexe1.L’analyse de ces graphiques montre une amélioration de l’imprécision lorsque l’intervalle de mesure diminue (passage d’une fréquence mensuelle à hebdomadaire) (figure 1-2b). Cependant le gain de biais est moindre pour ce cours d’eau sauf pour les méthodes dites « d’interpolation », M14 à M21. Les régressions linéaires logarithmiques entre les concentrations et les débits (Figure 1- 3) sont les modèles les plus communs (Walling, 1974). Log C = bo + b1 log Q + ε où bo et b1 sont les paramètres de régression et ε est en théorie le résidu de distribution normale de moyenne 0 et de variance constante. Cette méthode, également appelée « rating curve », permet une estimation du flux de sédiments sur une période de temps où les débits sont mesurés en continus. Cependant le résultat peut être fortement biaisé. En effet, Walling et Webb (1981, 1988) montrent que de telles méthodes peuvent produire une sous-estimation de l’ordre de -83% à -23%. Ce biais est dû à l’application d’une transformation logarithmique sans considérer la variance non expliquée par la régression. Ce problème est maintenant connu et de nombreux facteurs de corrections ont été proposé (Jansson, 1985 ; Ferguson, 1986,1987 ; Cohn et al.., 1989 ; Singh et Durgunoglu, 1989). Gilroy et al., (1990) ont comparé les performances de trois facteurs de corrections fréquemment utilisés. Ils ont montré que ces facteurs de correction réduisent le biais. Ces méthodes classiques sont encore largement utilisées pour l’évaluation des flux bien qu’elles ne soient pas entièrement satisfaisantes et qu’elles produisent des estimations imprécises, surtout dans le cas de données de concentrations éparses ou lorsque le jeu de données ne représente pas une gamme représentative de concentration et de débit (Cooper et Watts, 2002 ; Moatar et Meybeck, 2005 ; Salles et al.., 2008) ou encore lorsque la relation n’est pas linéaire (exemple des nutriments) ; (Cohn et al.., 1992 ; Horowitz, 2003). Une alternative à la régression simple est proposée par Cohn et al., (1992) qui suggèrent l’utilisation d’un modèle multivarié. Les concentrations sont estimées à partir d’une régression basée sur sept paramètres : constante, ajustement quadratique au logarithme des débits (deux paramètres), ajustement quadratique avec le temps (deux paramètres), une fonction sinusoidale pour enlever les effets de la saisonnalité (deux paramètres). ( ) ( ) [ ( )] ( ) β [ ] ( ) β ( ) ( ) π β π ε β β β β + + + = + + + + T T T T C Q Q Q Q T T ln / ² sin 2 cos où Q est le débit, T est le temps en année, Q et T sont les valeurs moyennes des séries, les β sont les paramètres du modèle à estimer à partir des données et ε est le résidu de la régression supposé normalement distribué de moyenne 0 et de variance constante. Dans le cas où les relations C-Q ne sont pas linéaires, cette méthode peut être intéressante. Les méthodes basées sur les moyennes, aussi appelé méthodes d’interpolation ou d’intégration, relient les moyennes des concentrations disponibles et du débit sur un intervalle de temps. Plusieurs procédures de ce type existent (Walling et Webb, 1981, 1988), en utilisant soit les débits journaliers (Qj) soit les débits mesurés les jours d’échantillonnage des concentrations (Qi) (figure 1-4).Plus récemment Quilbé et al., (2006) propose une classification plus complète des méthodes standard utilisées pour estimer la charge de sédiments en ajoutant deux catégories à celles définies par Phillips et al. (1999) : les estimateurs de planification et les méthodes de rapport d’estimation. Les estimateurs par planification sont les méthodes les plus simples. Le flux d’une période donnée est estimé comme le produit d’un volume d’écoulement estimé sur la période et d’une valeur représentative de concentrations sur cette même période. Comme il n’y a pas besoin de données spécifiques au site, soient pour les écoulements ou les concentrations, il est souvent utilisé comme une première estimation de la charge de polluants (Schwartz et Naiman, 1999). En raison de leur simplicité, ces estimateurs sont largement utilisés, spécialement quand la corrélation concentration-débit (C-Q) est faible. Néanmoins plusieurs auteurs (Walling et Webb, 1981, Ferguson, 1987) ont montré que ces estimateurs peuvent être biaisés et imprécis.Les méthodes basées sur les moyennes génèrent un biais sur l’estimation du flux si l’échantillonnage ne couvre pas une gamme représentative de la variabilité des débits et des concentrations (Ferguson, 1987 ; Dolan et al., 1981) La méthode empirique de rapport d’estimation, dérivée des méthodes basées sur les moyennes, a été développée par Beale (1962) et plus tard modifié par Preston et al., (1989) pour réduire ce biais. Elle sera détaillée par la suite dans la section 2.1.4.1. Ces méthodes pondèrent les concentrations avec le débit correspondant à l’échantillonnage. Beale (1962) développe ainsi un rapport d’estimation qui réduit le biais en prenant en compte la covariance entre les flux et les débits. Cet estimateur réduit le biais pour les grands bassins versants, notamment pour les MES. Il donne des estimations précises sur les flux de nitrate et de phosphore pour des bassins inférieurs à 20 km² en Angleterre (Littlewood, 1995) et en Finlande (Rekolainen et al., 1991) et est adapté au cas où peu de données de concentrations sont disponibles par rapport aux données de débits. Dolan et al., (1981) ainsi que Rekolainen et al., (1991) ont trouvé que ces estimateurs sont plus précis que les méthodes basées sur les moyennes. Il est à noter que toutes les méthodes décrites ci-dessus peuvent être utilisées sur les débits stratifiés quand un grand nombre de données est disponible. Lemke (1991) a utilisé les modèles de fonction de transfert pour estimer les concentrations de sédiments en suspension sur deux bassins versants dans l’Iowa (USA). Les concentrations dépendent dans ce cas des débits du jour même mais également des jours précédents. Les résultats du modèle indiquent que les formes et l’estimation des paramètres peuvent être reliées à la taille du bassin versant, au type d’occupation du sol ainsi qu’aux caractéristiques physiques du bassin. Cette méthode génère un modèle complexe avec de nombreux paramètres à estimer même s’il n’emploie qu’une seule variable. Littlewood (1995) a appliqué ces modèles de fonctions de transfert aux flux de nitrates pour deux petits bassins versants anglais. Clarke (1990) a proposé une autre approche qui suppose que les concentrations en sédiments et les débits suivent une loi de distribution log-normale. Des approches plus sophistiquées ont été développées ou sont en cours de développement comme les approches déterministes non linéaires (Sivakumar et Wallender, 2004) ou les modèles de réseaux de neurones (Kisi, 2005). Quelques auteurs ont commencé à utiliser les réseaux de neurones pour tenter d’estimer les flux sédimentaires à l’exutoire d’un bassin versant (Cigizoglu, 2004 ; Alp et Cigizoglu, 2006). Ces méthodes ont déjà fait leur preuve pour la représentation d’autres paramètres comme la température ou le pH (Moatar, 1997 ; Moatar et al., 1999). En utilisant des données hydrométéorologiques (essentiellement pluie et débit), Alp et Cigizoglu (2006) sont parvenus à des résultats tout à fait encourageants, en reconstituant avec une bonne précision les flux sédimentaires journaliers. Plus récemment, Mailhot et al. (2008) ont développé une nouvelle méthode pour estimer le flux annuel de sédiments à partir de la distribution statistique des concentrations. La concentration est considérée comme une variable aléatoire qui peut être représenté par une distribution statistique dont les paramètres sont fonctions des débits et du jour calendaire. Le modèle est donc défini à travers un modèle explicatif utilisant une loi de distribution (par exemple Log-normale, Gamma, Weibull), un modèle de moyenne et un modèle de coefficient de variation des concentrations et dont la moyenne et la variance s’exprime en fonction de covariables (par exemple le débit et le jour julien). Cette méthode sera utilisée dans cette thèse et sera décrite au chapitre 2.
Incertitudes associées aux méthodes de calculs
Dans la littérature, l’évaluation des flux porte souvent sur un seul constituant : Le phosphore par Jordan et al., (2005,2007), Moosman et al. (2005), le nitrate (Birgand et al., 2009), Le constituant le plus étudié est la matière en suspension (MES). Walling et Webb (1981) ont travaillé sur l’estimation des MES sur la rivière Creedy au Devon (Royaume-Uni), Walling (1977) a étudié les limites de la méthode de régression sur les MES pour trois rivières du Devon (Rivière Creedy, Dart et Exe mais également Morehead et al. (2003), de Vries et Klavers (1994), Kao et al. (2005), Holtschlag (2001) Tramblay et al. (2007). Chacune de ces études portent sur un nombre de bassins versants limité (1 à 9) et souvent de petites tailles. Horowitz (2001) commençait à étudier l’estimation des flux de plusieurs paramètres (SPM et éléments traces, phosphore) sur des grands bassins Nord américains (Mississipi, Colorado, Columbia, Rio Grande). Le tableau 1- 3 fait un inventaire de la bibliographie et donne un ordre de grandeur des incertitudes signalées par les différents auteurs. Les gammes de variations des incertitudes diffèrent selon les paramètres. Elles peuvent aller, selon les études, de -80 à 360% pour les MES, de -2 à 20% pour les nitrates et sont très faibles pour les chlorures. Différents auteurs ont également évalué les incertitudes des flux déterminés pour des durées de plusieurs années. D’après Littlewood (1995), les flux de nitrate déterminés sur 2 et 14 ans avec la méthode des concentrations moyennes pondérées par les débits sont plus précis que les flux annuels (déterminé sur un an). Même constatation pour Horowitz (2003), qui sur la base de la méthode de régression C-Q, observe une diminution des erreurs de -10% à 3% sur le flux de MES pour des durée de 1 et 5 ans. Cet auteur observe également une diminution de la dispersion des erreurs en augmentant la fréquence d’échantillonnage quelle que soit la durée du calcul des flux.