Pendant des siècles, la culture judéo-chrétienne a répandu la vision fixiste de la vie au travers de l’« Ancien Testament ». La pensée dominante sur l’origine de la vie, le créationnisme, voulait alors que les êtres vivants soient des créations immuables de Dieu. Bien que l’homme ait pratiqué la sélection des individus dans l’élevage des animaux depuis la préhistoire, ce n’est qu’au xviiie siècle qu’Erasmus Darwin dans « Zoonomie, ou lois de la vie organique » [Dar96], énonce la première théorie de l’évolution, le transformisme. Cette idée est alors formalisée par Jean-Baptiste Lamarck : le lamarckisme accorde aux êtres vivants la capacité d’évoluer et de transmettre leurs évolutions de part une tendance interne à la complexification contrée par les circonstances extérieures.
Au xixe siècle, Charles Darwin s’oppose au lamarkisme dans « De l’origine des espèces par voie de sélection naturelle » [Dar59], en émettant l’idée de la sélection du plus apte parmi des individus naturellement variants. Le darwinisme était néanmoins incapable d’expliquer les mécanismes régissant l’apparition et la transmission des changements d’une génération à l’autre. Il faudra attendre le xxe siècle pour que le généticien Gregor Mendel explique ces mécanismes par la fréquence d’apparition des gènes au sein d’une population. C’est finalement la théorie synthétique de l’évolution biologique ou néodarwinisme, intégrant les théories de Darwin, Mendel et de la génétique des populations qui est aujourd’hui communément admise par les biologistes. Ainsi, l’évolution n’est plus envisagée comme la transformation d’individus mais comme celle de populations. Le principe de base restant inchangé : la sélection naturelle.
Le parallèle entre évolution biologique et informatique n’est pas totalement fortuit. En effet, l’évolution des systèmes informatiques, tout comme l’évolution biologique, se manifeste par une accumulation de petites modifications. De plus, selon Lehman [BL76], un système informatique utilisé dans un environnement réel doit nécessairement évoluer, faute de quoi, il devient de moins en moins utile dans cet environnement et tend à disparaître.
Dans un contexte où les technologies de communication et le multimédia évoluent à grande vitesse, et où une part importante des systèmes informatiques ne remplissent pas leurs cahiers des charges lors de leurs livraisons, il est nécessaire de concevoir des systèmes évolutifs sous peine de les voir rapidement devenir obsolètes. Malheureusement, la poursuite effrénée des nouvelles fonctionnalités est souvent engagée au détriment d’une solution plus adaptable et extensible, et donc plus pérenne.
La réalisation de systèmes évolutifs est depuis longtemps une question centrale en informatique. La diffusion importante de l’informatique auprès du grand public exacerbe cette problématique. Par exemple, on constate qu’une distribution Linux est avant tout choisie pour son système de diffusion et d’installation, et la fréquence de ses mises à jour. Néanmoins, de nombreux développeurs négligent l’importance de cette problématique et se contentent, comme seul moyen d’adapter et d’étendre les systèmes, de diffuser des versions modifiées des logiciels. Les utilisateurs sont alors en charge de l’application des mises à jour, ce qui impose l’arrêt et le redémarrage des systèmes en cours d’exécution. Ce vecteur de propagation des évolutions n’est pas simplement un désagrément pour les utilisateurs, mais trahit l’absence de prise en compte de la problématique de l’évolution des systèmes. En plus d’imposer des contraintes à l’utilisateur, la négligence coupable des développeurs contribue à la prolifération des virus informatiques. En effet, contrairement aux développeurs, les pirates informatiques ont eux bien compris les enjeux posés par l’adaptabilité des systèmes : ils propagent régulièrement des virus exploitant des failles de sécurité connues sachant pertinemment que le délai entre la découverte d’une faille et sa correction éventuelle sur le parc informatique mondial leurs laisse tout loisir d’opérer.
Contrairement à ce que pourrait laisser penser cet état de fait, la conception de systèmes extensibles a fait l’objet d’importantes recherches ayant abouties à des solutions originales. Néanmoins, ces approches sont difficilement applicables aux applications système patrimoniales : la qualité du code de ces systèmes est l’aboutissement de nombreux remaniements et corrections et ces systèmes sont soumis à de fortes contraintes de performance. Leur refactoring implique une dégradation de leur qualité et de leur performance pour un résultat dont l’adaptabilité reste à démontrer. En effet, il est difficile voire impossible d’anticiper quelles seront les évolutions futures, les interfaces permettant l’extensibilité d’un système se révèlent souvent inadaptées si ce n’est inutiles face aux réels besoins d’évolution.
À l’inverse, les travaux sur l’adaptation par la transformation à la volée des applications se confrontent mieux aux contraintes de performance des applications systèmes patrimoniales. En n’imposant pas de refactoring statique, ces approches maintiennent la qualité des systèmes, tout en permettant l’adaptation fine et performante des applications. Ces travaux se limitent néanmoins à des outils de manipulation de code à la volée, dès lors, ils demeurent réservés à une utilisation experte. Par manque de support langage, les adaptations par transformation de programme à la volée sont souvent complexes à concevoir et difficilement réutilisables.
La nécessité de concevoir des applications adaptables n’est plus à démontrer. Nous assistons aujourd’hui à l’émergence toujours plus rapide des nouvelles technologies. Plus que jamais, les créateurs des systèmes informatiques ont besoin de méthodes et d’outils afin de poursuivre la course effrénée à l’intégration de nouvelles fonctionnalités. L’émergence de nouvelles technologies et la diversification des plateformes numériques, téléphones portables, home cinéma, etc font de l’adaptabilité et de l’extensibilité, un enjeu de pérennité pour les systèmes informatiques.
De plus, les systèmes informatiques ont atteint une complexité telle qu’ils sont hautement interdépendants. Parce que les applications et le système d’exploitation sont de plus en plus interdépendants, il est nécessaire d’envisager une solution globale à la problématique de l’évolution des systèmes informatiques.
La paramétrisation est une technique ancienne d’adaptation des logiciels. Elle consiste à modifier les valeurs de variables adaptant le comportement d’un logiciel. Par exemple, il est possible de modifier dynamiquement l’affichage des terminaux UNIX en modifiant les variables row et column. De même, il est possible dans le noyau Linux de modifier les paramètres de la pile IP/TCP. Ces paramètres contrôlent les fanions utilisés sur les paquets de contrôle ou encore les délais de réponse et/ou de retransmission des paquets. La paramétrisation des protocoles réseaux est une méthode utilisée par les administrateurs de systèmes informatiques pour contrer les prises d’empreintes de systèmes d’exploitation [SMJ00]. Cette technique d’adaptation est largement utilisée. Néanmoins, elle est nécessairement anticipée lors de la conception et n’autorise que l’adaptation des fonctionnalités prédéfinies sans permettre l’intégration de nouvelles fonctionnalités.
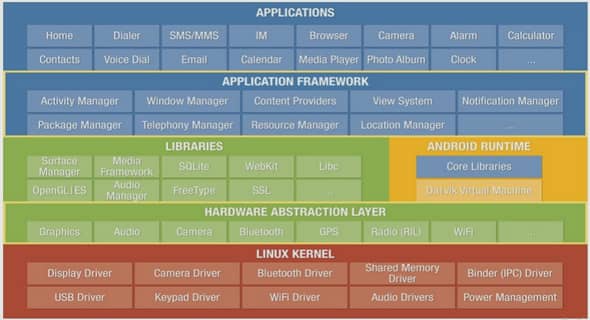
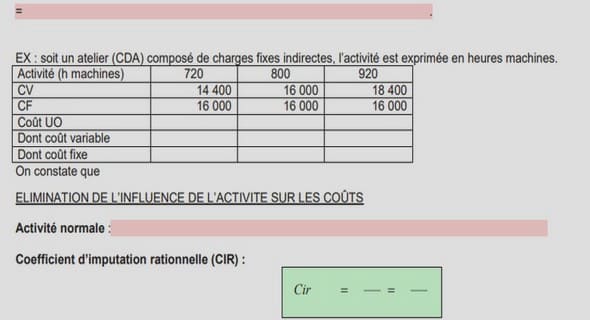
1 Introduction |