Knowledge-based authentication mechanisms rely upon users’ ability to recall secret information. It is possible to distinguish two different kinds of knowledge-based techniques: explicit and implicit schemes. On the first hand, explicit ones need the user to set and learn a piece of knowledge. On the other hand, implicit ones exploit the user memory thanks to either, or both, personal information they already know, or about their everyday life preferences (e.g. music they like or food they enjoy).
STRENGTH EVALUATION OF KNOWLEDGE-BASED
AUTHENTICATION SCHEMES
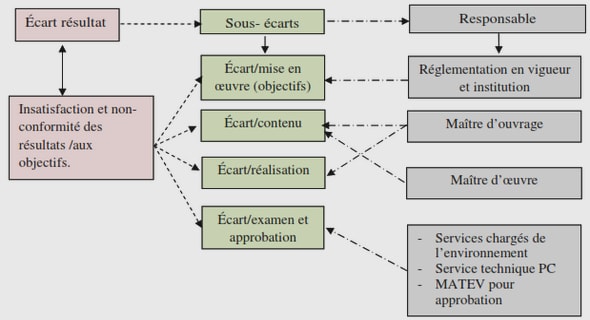
The strength of a knowledge-based authentication scheme is theoretically measurable through the evaluation of the entropy of the password space. The entropy of a password represents the measurement of how unpredictable a password is and the password space is the total number of distinct possibilities the authentication system can support. Hence, the evaluation of the entropy of the password space provides a metric of how strong an authentication system is. The size 𝑆 of the password space for a system having 𝑁 possible entries is given by the equation (2.1). The length of the input to retain is expressed by 𝑘. Finally, the entropy 𝐻 can be computed by using the equation (2.2), and the result is expressed in bits. 𝑆= 𝑁𝑘. (2.1) / 𝐻 = 𝑙𝑜𝑔2(𝑆). (2.2)
Real use cases reveal that such an evaluation still not represents an accurate measure of the strength of a knowledge-based authentication mechanism. Indeed, since users have the possibility to choose their own secret input, they often refer to a familiar pattern rather select it randomly. As an example, Yampolskiy (2006) has pointed out that 47.5% of the users chose a family-oriented information as secret input such as a child’s name or date of birth. Therefore, a lower subset of the 𝑁 possibilities is truly used, since the length of passwords are generally less than 8 characters (Yan 2004) .
EXPLICIT SCHEMES
Personal Identification Numbers (PINs)
Example of use case scenario: commonly, users have to choose an array of 4- digits that they will need to remember. Then, each time the mobile device has to be unlocked, the system prompts an input field where the user needs to fill these digits in the correct order to be authorized to access the whole content of the device.
Personal Identification Numbers (PINs) are a simple way to restrain access to an entity due to their composition—from 4 to 16 digits. They appear with the growth of ATMs (Automated Teller Machines), and they are mostly used in the banking system. Regarding a mobile device context, PINs currently remain the most dominant authentication method to protect the access of these devices since they are employed by 2/3 of the mobile device users (Clarke and Furnell 2005). PINs can be applied to both the device and the user’s Subscriber Identity Module (SIM)—a removable token that contains required cryptographic keys for network access. Both of the two leading mobile device operating systems (i.e. Android and iOS) provide this authentication mechanism.
However, PINs present several issues considering memorability or human habits that may compromise the security offers by the system. In that sense, Clarke and Furnell (2005) have assessed that 1/3 of mobile devices users who keep their phone locked through a 4-digits PIN method, consider such protection as an inconvenience in everyday life. As a result, users do need to retain a code that has a familiar signification, such as their date of birth (Yampolskiy 2006). Furthermore, Clarke and Furnell (2005) also enhance the weakness of this authentication scheme. Indeed, 36% of the respondents have reported using the same PIN-code for multiple services. Thus, it becomes easier for an attacker to determine the correct 4-digits PIN in order to have free access to several other services where the code is employed. The lack of security brought by users can also be underlined through another study that reports that 26% of PIN users shared their own code with someone else (Clarke et al. 2002).
CHAPTER I – INTRODUCTION |