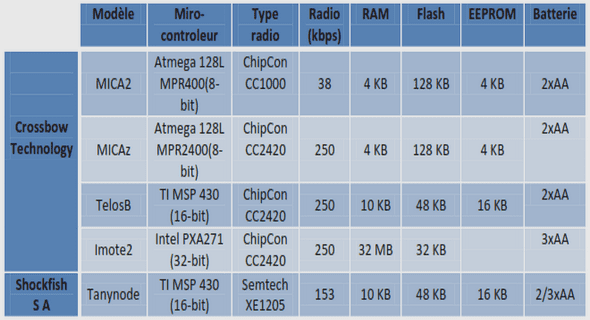
Procédures de test et conditions de passation
Deux procédures de test ont été utilisées dans ce travail : la technique de complétude de phrases pour le pré-test et la technique de l’APS (Auto Présentation Segmentée) pour les tests en temps réel (« on line »). Le pré-test a été réalisé par petits groupes d’étudiants à l’université Sorbonne Nouvelle-Paris : les étudiants étaient informés de l’expérience dans le cadre des enseignements qu’ils suivaient. Les tests se déroulaient en dehors des cours : seuls les volontaires y participaient. Les tests en temps réel avec la technique de l’APS ont été réalisés avec le logiciel E-prime version 2 professionnelle (Psychology Software Tools, Inc.) : il y en a eu trois. Dans cette méthodologie, les items sont affichés sur un écran d’ordinateur, phrase par phrase ou segment par segment (quelquefois mot par mot). Les participants au test avaient reçu la consigne de progresser dans la lecture de l’item à leur rythme en appuyant sur la barre d’espace. Une question de compréhension était posée à la fin de chaque items. Cette question amenait une réponse binaire en oui ou non à laquelle le participant répondait en appuyant sur le chiffre un (1) du clavier ou la chiffre zéro (0). Les items de test étaient précédés de deux items d’entraînement pour familiariser le participant au protocole de lecture. Les temps de lecture de chaque segment étaient enregistrés ainsi que les temps de réponse à la question et la réponse elle-même. Dans nos expérience en temps réel, les participants passaient le test un par un, dans une petite salle mise à notre disposition par l’UMR dirigée par M. Michel Collot puis par Alain Schaffner. Ils étaient recrutés directement par affiches ou par une présentation personnalisée à la fin de leurs cours. A la fin du test, ils recevaient une entrée au Forum des images aux Halles. Les participants étaient interrogés 1) sur les langues qu’ils parlaient et en cas de bilinguisme, sur la langue qu’ils considéraient comme dominante, 2) sur des problèmes de dyslexie éventuels qu’ils auraient rencontrés dans leur scolarité, 3) sur le cursus suivi à l’université Sorbonne Nouvelle. Comme précisé à chaque participant, les réponses à ces questions n’étaient pas nominatives.
Analyses statistiques et modèles utilisés
Les analyses statistiques ont été réalisées avec le logiciel R44. Elles ont portées sur le nombre de reprises au singulier et au pluriel dans le pré-test et sur les temps de lecture pour les tests en temps réel. Nous exposons ci-dessous les étapes suivies lors des analyses statistiques des temps de lecture.
La première étape consistait à trier les temps de lecture
Les taux de bonnes réponses de chaque participant étaient examinés et seules les données des participants ayant au moins deux tiers de réponses correctes étaient conservées. De plus, pour chaque participant, les temps supérieurs de deux écart-type ou inférieurs de deux écart-type par rapport à sa moyenne étaient éliminés. Les analyses utilisaient les fonctions glmer (loi binomiale pour le nombre de reprises plurielles dans le pré-test) et lmer de R (loi normale pour les temps de réponse). On cherchait d’abord des covariations éventuelles entre les temps de lecture et 1) le nombre de caractères du texte (ou segment) correspondant à ce temps de lecture, 2) la fréquence du verbe de la phrase en cours de lecture et 3) la position ordinale de la phrase dans le test en cours. Lorsque l’une de ces variables covariait avec les temps de lecture analysés (ce qui arrivait systématiquement pour la position ordinale de l’item), on faisait une régression des temps de lecture sur la ou les variables covariantes (Clifton et Ferreira, 2012) avec le modèle linéaire mixte de R : les résidus issus de cette régression faisaient l’objet d’une analyse linéaire mixte sur les facteurs du plan d’expérience, avec les variables aléatoires sujets et items (termes d’erreur). Les termes d’erreur pouvaient comporter des effets aléatoires moyens dus aux sujets et aux items ou des effets aléatoires moyens augmentés d’effets aléatoires dus à des incertitudes de modélisation (calculs sur la pente sur la droite de régression). Dans toutes nos analyses, il n’y avait pas de différence entre les résultats obtenus avec les termes d’erreur qui tenaient compte des incertitudes de la modélisation et ceux obtenus avec les termes d’erreurs moyens. Le modèle le plus simple a donc été utilisé (Baayen, 2008). Le résultat de l’analyse avec le modèle linéaire mixte donnant des effets de significativité peu fiables du fait des incertitudes sur les calculs des degrés de liberté, il fallait confirmer l’effet d’un facteur apparaissant comme significatif après cette première analyse. Une deuxième analyse avec le modèle linéaire mixte était effectuée sans ce facteur : puis une comparaison (Anova) entre les résultats de la première et de la deuxième analyse était réalisée : si une différence était détectée (chisquare <0.05), on en déduisait que le facteur supprimé de la deuxième analyse était bien significatif. Dans chaque test, les données ont été analysées pour vérifier que le facteur « groupe expérimental » n’était pas significatif
Elaboration du matériel de test
Les verbes symétriques ne sont pas marqués syntaxiquement et peuvent donc être contrastés avec des verbes mixtes dans les contextes phrastiques identiques comme le montrent les exemples (210a-d) et (211a-b). Les verbes de nos expérimentations ont été sélectionnés à partir de la liste de verbes symétriques établie par A. Borillo (1971)45. Ils devaient répondre à certains critères : avoir une construction transitive indirecte en avec, mais aussi ne pas être pronominaux (se disputer, se concerter ont été écartés, par exemple). Le dictionnaire électronique des verbes français de Dubois et DuboisCharlier (1997), indique que les verbes sélectionnés partagent un schéma verbal de base que nous présentons en annexe 2. La catégorie linguistique des arguments utilisés dans les items de test était celle des noms propres : des prénoms de genre féminin et masculin. Cette catégorie a été choisie parce qu’elle n’interagit pas avec le sémantisme du verbe, permettant au schéma verbal et aux rôles thématiques correspondants d’être testés sans biais. Les prénoms ont été choisis de façon à ce qu’ils désignent un genre sans ambiguïté ; ils ne devaient pas faire plus de deux syllabes pour homogénéiser la longueur des phrases testées. Les différentes conditions expérimentales étaient contrastées dans une structure phrastique qui 1) évitait les collusions entre prédicat et syntagme prépositionnel en insérant un adverbe ou un circonstanciel entre eux, 2) se terminait toujours par un adverbe ou un circonstanciel de façon à éviter une trop grande proximité entre le référent régi et la reprise pronominale qui suivait. La phrase qui supportait les conditions expérimentales a été désignée par le terme de phrase amorce. La phrase qui suivait et dont le traitement était testé était désignée comme la phrase cible. Phrases amorces et phrases cibles étaient calibrées : le nombre de caractères des phrases amorces était compris entre 67 et 72 et le nombre de caractère des phrases cibles était compris entre 52 et 60. Les verbes non symétriques choisis étaient soit des verbes d’action (comme grimper, bosser, chercher, ricaner, contrôler, militer, etc…) sélectionnés pour leur capacité à regrouper les protagonistes dans une action collective, soit des verbes de perception (geler, pleurer, angoisser, trembler, se débrouiller, s’ennuyer, etc…), sélectionnés pour leur caractère individualisant qui ne s’applique qu’à l’individu du fait de particularités qui lui appartiennent en propre (Clifton et Frazier, 2012). Les verbes d’action, associés à des informations de lieu et de temps qui participent à ’élaboration d’une base d’association commune (Eschenbach et al., 1989) suscitent plutôt une interprétation collective de la prédication : la préposition avec est alors équivalente à une structure coordonnante. Dans certaines prédications, cependant, seul le contexte permettait de trancher entre interprétation collective et distributive . Par exemple le verbe transpirer est à priori un distributif mais l’exemple (213) induit une base d’association commune et une interprétation collective. De même l’exemple (214). En fait, le principal critère de classement des prédicats en collectifs ou distributifs, était le sens de la préposition avec (cf. 2.1.2) : chaque fois qu’elle introduisait une nuance de causalité ou de non engagement du référent régi, le prédicat était catégorisé comme distributif. Dans une phrase amorce comme (215), Miguel peut être son professeur ou être un étudiant qui progresse également en portugais à l’heure du déjeuner, auquel cas les rôles thématiques de l’un et de l’autre diffèrent : il y a ambiguïté et de ce fait le prédicat progresser en Portugais avec quelqu’un à l’heure du déjeuner est classé comme un distributif.