CONCEPTION ET REALISATION D’UN SYSTEME DE GESTION DE DOSSIERS MEDICAUX
Dossier Médical Informatisé et apprentissage automatique pour la prise de décision
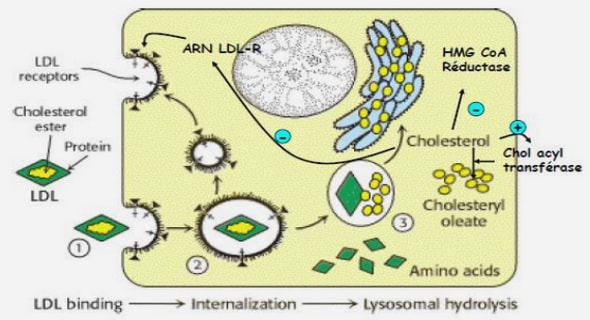
Dossier Médical Informatisé
Un dossier médical peut être définit comme un ensemble d’informations concernant la santé du patient détenues par le professionnel, qui sont formalisées et ont contribué à l’élaboration et au suivi du diagnostic et du traitement ou d’une action de prévention, ou ont fait l’objet d’échanges écrits entre professionnels de santé[2]. Les dossiers médicaux pratiqués depuis la fin du 18iem siècle, ont des limites, ils sont souvent mal structurés, difficiles à lire, parfois introuvables. L’éparpillement des informations, empilées chronologiquement, peut retarder l’identification et la résolution des problèmes cliniques. Des traitements qui ont échoué ou donné des effets indésirables peuvent être represcrits. Les difficultés de classement des examens complémentaires peuvent conduire à répéter des examens inutilement. Pour éviter ces inconvénients, il est nécessaire de reporter les mêmes données sur différents supports. La moindre tentative d’évaluation ou de recherche dans les hˆopitaux ou cliniques à partir des dossiers demande des heures de recherche manuelle fastidieuse. Les dossiers papier posent des problèmes de classement, de dégradation des supports et d’archivage. Avec tout ce qui est souligné, l’informatisation du dossier médical devient le remède clef à la fois pour la bonne pratique et pour l’archivage permanente. La principale force du dossier informatique est probablement que les informations sont libérées des contraintes liées à une organisation spatiale (support physique, format préétabli) ou temporelle (succession des rencontres). Les informations du dossier informatique peuvent être disponibles à plusieurs endroits quasi simultanément, accessibles à partir de terminaux. Le dossier informatique peut présenter les informations dans n’importe quel ordre et format voulus. L’ordinateur peut produire de nombreux comptes rendus, résumés, index, à partir de la totalité des données en12 registrées : synthèse des données les plus importantes du dossier, liste des problèmes actifs, liste des médicaments, des résultats biologiques anormaux, données spécifiques pour une maladie chronique. Le dossier informatique peut contribuer à modifier les pratiques et à mettre en œuvre des recommandations à travers : — des aides à la décision immédiates, basées sur des arbres décisionnels ; — des ordonnances préétablies conformes à des protocoles validés ; — une rétroaction par l’apport régulier d’information sur les performances.
Apprentissage automatique pour la prise de décision
Pour la conception d’un système d’aide à la décision, il est nécessaire de faire une étude approfondie sur les différentes méthodologie d’approche pouvant largement couvrir les besoins de ce dernier.
Apprentissage automatique
L’apprentissage automatique (machine learning) ou apprentissage statistique, champ d’étude de l’intelligence artificielle, concerne la conception, l’analyse, le développement et l’implémentation de méthodes permettant à une machine (au sens large) d’évoluer par un processus systématique, et ainsi de remplir des tˆaches difficiles ou problématiques par des moyens algorithmiques plus classiques. Cependant elle est catégorisée en deux grands champs : NB : Dans cette partie, toutes les représentations et utilisation de données par les algorithmes se font à partir de vecteurs ou de matrices.
Apprentissage non supervisé
L’apprentissage non supervisé est la conception et l’utilisation d’un algorithme d’intelligence artificielle (IA) utilisant des informations qui ne sont ni classées ni labellisées et permettant à l’algorithme d’agir sur cette information sans guidage. Dans l’apprentissage non supervisé, un système d’IA peut regrouper des informations non triées en fonction des similitudes et des différences, même si aucune catégorie n’est fournie. Exemple : K-Means K-means clustering est un type d’apprentissage non supervisé, qui est utilisé avec des données non étiquetées. Le but de cet algorithme est de trouver des groupes dans les données, avec le nombre de groupes représentés par la variable K. L’algorithme fonctionne itérativement pour affecter chaque point de données à l’un des K groupes en fonction des caractéristiques fournies. Les points de données sont regroupés en fonction de la similarité des entités. Les résultats de l’algorithme de clustering Kmeans sont : — Les centro¨ıdes des groupes K, qui peuvent être utilisés pour étiqueter de nouvelles données ; — Etiquettes pour les données d’apprentissage (chaque point de données est affecté à un seul cluster). Plutˆot que de définir des groupes avant de regarder les données, le regroupement vous permet de trouver et d’analyser les groupes qui se sont formés organiquement. Dans la plupart des cas le nombre de K cluster est choisi selon les besoins de l’utilisateur et pour chaque K cluster, son assignement doit être aléatoire (pour éviter que deux clusters fusionnent ou ne se séparent jamais). La figure 1.1 montre sur un graphe un échantillon de données non catégorisées, non labellisées ; puis génération aléatoire des K clusters après plusieurs itérations, chaque K cluster regroupe les données avoisinantes en formant des groupes. Exemple de doFigure 1.1 – Fonctionnement K-Means maine d’application : suivant des profils d’utilisateurs d’un réseau social, K-Means peut regrouper les utilisateurs en différents type d’utilisateurs. Ce type d’apprentissage n’est pas favorable pour la conception d’un système de recommandation médical, car son principe de fonctionnement repose sur l’utilisation de données non libellées, non catégorisées pour à la fin en sortie des patterns ou des données groupées.
Apprentissage supervisé
L’apprentissage supervisé, dans le contexte de l’intelligence artificielle (IA) et de l’apprentissage automatique, est un type de système dans lequel les données d’entrée et de sortie désirées sont fournies. Les données d’entrées et de sortie sont étiquetées pour la classification afin de fournir une base d’apprentissage pour le traitement futur des données. Les données d’apprentissage pour l’apprentissage supervisé comprennent un ensemble d’exemples avec des sujets d’entrée appariés et la sortie désirée (que l’on appelle également le signal de supervision). Dans l’apprentissage supervisé pour le traitement d’images, par exemple, un système d’IA pourrait être fourni avec des images étiquetées de véhicules dans des catégories telles que les voitures et les camions. Après une quantité suffisante d’observation, le système devrait être capable de distinguer et de catégoriser les images non étiquetées, à quel moment la formation peut être considérée comme complète. Plusieurs types spécifiques d’apprentissage supervisé sont représentés existent : la classification, la régression et la détection d’anomalies. Classification Lorsque les données sont utilisées pour prédire une catégorie, l’apprentissage supervisé est également appelé classification. C’est le cas lors de l’affectation d’une image en tant que photo d’un « berling » ou d’un « camion ». Quand il n’y a que deux choix, on appelle cela la classification à deux classes ou binomiale . Lorsqu’il existe plusieurs catégories, comme lors de la prévision du gagnant du Champions’ League, ce problème est connu sous le nom de classification à classes multiples. Régression Lorsque l’on prédit une valeur, comme le cours de la Bourse, l’apprentissage surveillé est appelé régression. Détection des anomalies Parfois, l’objectif est d’identifier les points de données qui sont simplement inhabituels. Dans le cas de la détection des fraudes par exemple, toute dépense très étrange par carte de crédit est suspecte. Les variations possibles sont si nombreuses et les exemples de formation si rares, qu’il n’est pas possible de savoir à quoi ressemble une activité frauduleuse. L’approche de la détection des anomalies consiste simplement à apprendre à quoi ressemble l’activité normale (à l’aide d’un historique de transactions non-frauduleuses) et d’identifier tout ce qui est très différent. Dans le cadre de la conception de notre système, les algorithmes de classification à classes multiples sont plus aptes pour aider un médecin à faire son diagnostic. Parmi ces algorithmes, faisons l’étude de : Réseau de neurones Les réseaux neuronaux sont des algorithmes d’apprentissage inspirés du cerveau couvrant les problèmes de classes multiples, à deux classes et de régression. Un réseau de neurones est divisé en trois grandes couches : input, hidden, output. Le premier niveau (input) re¸coit l’information d’entrée brute – analogue aux nerfs optiques dans le traitement visuel humain. Chaque niveau successif (hidden) re¸coit la sortie du niveau qui le précède, plutˆot que de l’entrée brute – de la même manière que les neurones plus éloignés du nerf optique re¸coivent des signaux de ceux qui sont plus proches de lui. Le dernier niveau (output) produit la sortie du système. Chaque nœud de traitement a sa propre petite sphère de connaissance, y compris ce qu’il a vu et toutes les règles qu’il a été initialement programmé ou développé pour lui même. Les niveaux sont fortement interconnectés, ce qui signifie que chaque nœud du niveau n sera connecté à plusieurs nœuds du niveau n-1 – ses entrées – et au niveau n + 1, qui fournit une entrée pour ces nœuds. Il peut y avoir un ou plusieurs nœuds dans la couche de sortie, à partir de laquelle la réponse qu’elle produit peut être lue. Les réseaux de neurones sont remarquables pour être adaptatifs, ce qui signifie qu’ils se modifient eux-mêmes à mesure qu’ils apprennent de la formation initiale et que les séries suivantes fournissent plus d’informations. Principe et Formules Pour illustrer le fonctionnement d’un réseau de neurone, travaillons avec la figure 1.3 Voilà un réseau de neurones, qui est composé de quatre layers (couches ou neurones). Le premier est le layer des inputs, le deuxième et le troisième constitue le layer hidden et le dernier quatrième constitue le output. Principe Pour expliquer le principe, prenons l’exemple de l’orientation d’un élève de troisième. Ici l’application devrait pouvoir orienter un élève en série S, L ou G .
1.1 Dossier Médical Informatisé |