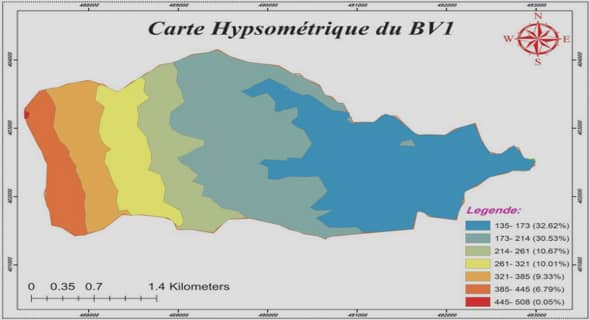
Consolidation de correspondances
La recherche de facteurs répétés de sous-arbres frères telle que présentée dans le chapitre précédent montre en pratique ses limites, même avec l’usage de certains profils d’abstraction. Si certains profils permettent de gérer des cas d’obfuscation comme la réécriture d’expressions (abstraction des petits sous-arbres) ou la modification de structures de contrôle (suppression des nœuds représentant ces structures), d’autres opérations d’éditions conduisent à l’obtention de valeurs de hachage différentes pour un sous-arbre et son clone obfusqué. En particulier, l’ajout ou la suppression de code inutile n’est pas systématiquement décelable lors d’une étape de normalisation de l’arbre de syntaxe. Il en est de même pour certaines opérations de transposition de code. Ces opérations conduisent à l’ajout, la suppression ou le déplacement de sous-arbres de volume plus ou moins important.} seront relevés. Il apparaîtrait plus légitime, pour un évaluateur humain, de consolider ces deux correspon- dances en une seule en mentionnant l’ajout du sous-arbre D si celui-ci est de volume négligeable comparé à celui de l’ensemble de la fratrie.) = (¬cond, sinon, alors) ne permet pas de consolider les sous- arbres alors et sinon en une unique correspondance à cause de la transposition des deux sous-arbres et de la négation de la condition.
Factorisation ou développement de fonctions
Un ensemble d’instructions inter-dépendantes d’une fonction peut être externalisée dans une nouvelle fonction qui sera appelée depuis la fonction source. L’externalisation (ou factorisation) se matérialise sur l’arbre de syntaxe par la migration des instructions de la fonction source vers la fonction externalisée avec l’introduction de paramètres de fonction correspondant aux L’opération réciproque de développement consiste à remplacer l’appel d’une fonction par le corps de ladite fonction. Le corps de la fonction nécessite généralement quelques adaptations au contexte local : changement de noms de variables locales, remplacement des instructions de retour par des affectations, remplacement des identificateurs des paramètres par leur valeur d’argument (cf figure 7.1)… Ces petites modifications ne permettent souvent pas d’obtenir une correspondance exacte entre le corps développé et le corps original : des fossés de non- correspondance sont présents. Il s’agit de regrouper ces correspondances séparées par des fossés en une unique correspondance.L’extension de correspondances sur des arbres de syntaxe est quant à elle un sujet qui été peu exploré. On pourra citer la méthode de propagation de correspondances utilisée par CloneDr [91]. Celle-ci consiste, lorsque deux arbres (ou chaînes d’arbres frères) ont été reportés comme similaires, à tenter de prolonger systématiquement la correspondance à leurs parents. Les sous-arbres ayant pour racine respective chacun des deux parents sont donc comparés en utilisant une méthode d’alignement sur arbres comme celles décrites en section 5.5. Si cette approche permet la détection en tant que clones de deux arbres possédant au moins un sous- arbre identique avec des modifications sur les autres sous-arbres frères, plusieurs niveaux de propagation pourraient être nécessaires pour permettre la mise en valeur de certains clones. D’autre part, le coût de détermination de distance d’édition entre deux arbres peut devenir prohibitif pour de grands sous-arbres.
Cobena [42] a également utilisé des méthodes de propagation à des nœuds parent pour la recherche de paires de sous-arbres correspondants dans des arbres de documents XML. La problématique demeure néanmoins assez différente de la notre car consistant à déterminer un delta entre différentes versions d’un même document XML, chaque sous-arbre ne pouvant cor- respondre au plus qu’avec un seul sous-arbre de l’autre version. Dans le cadre de la recherche de correspondances sur des sous-arbres de syntaxe provenant d’analyse de code source, l’uti- lisation de clones chevauchants n’est pas sans intérêt, une même zone de code pouvant être dupliquée au sein d’un même projet, voire d’une même unité de compilation. Nous proposons dans ce chapitre une heuristique de consolidation de paires de correspon- dances en s’aidant de l’arbre de syntaxe des unités étudiées. Étant donné un arbre de syntaxe requête et une base d’arbres indexés, nous recherchons dans un premier temps les classes d’équi- valence de sous-arbres, selon un profil d’abstraction donné, contenant au moins un exemplaire d’un sous-arbre de l’arbre requête. Nous en déduisons l’ensemble des paires de sous-arbres similaires dont un exemplaire provient de l’arbre requête et l’autre d’un arbre de la base.