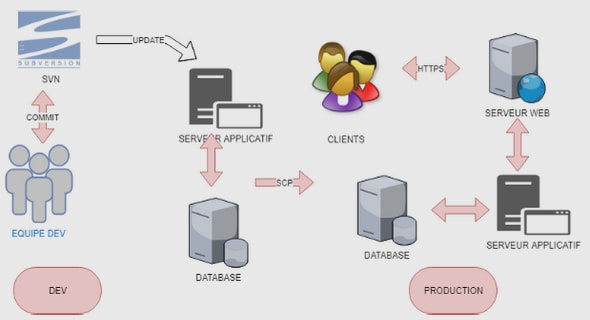
ETUDE ET MISE EN PLACE D’UNE HAUTE DISPONIBILITE EN BASE DE DONNEES ORACLE
Généralité Sur La Haute Disponibilité
Concepts et principes de base de la haute disponibilité La haute disponibilité (HA) consiste à détecter les points de défaillance unique (Single Points of Failure) de système et à les réduire par la mise en place de techniques de redondance et/ou de réplication. Sans la HA, les clients constateraient une discontinuité de service à chaque panne logicielle ou panne matérielle. Classiquement, un administrateur IT intervient pour rechercher la cause et prendre les mesures appropriées (redémarrer processus, restauration, remplacement des pièces défectueuses.), en gros des actions correctives. A l’inverse l’établissement d’une haute disponibilité correspond à une action préventive, mieux en la prise en compte des différents risques de disfonctionnements dans la conception même du système. La haute disponibilité consiste à mettre en place une infrastructure spécialisée, en appliquant des principes et processus afin de limiter au maximum les indisponibilités. Nous allons voir dans ce chapitre ces différents principes et leurs fonctionnements. Avant cela, il est nécessaire d’introduire la terminologie associée.
DEFINITION ET TERMINOLOGIE
Elément : c’est un sous-ensemble matériel et/ou logiciel assurant une fonction spécifique. Il peut s’agir d’un dispositif, composant, sous système, entité, module, unité. Système Informatique : ensemble cohérent et autonome d’éléments matériels, logiciel de base et d’applications, placé éventuellement dans un environnement réseau ; son comportement est décrit dans un document de référence. Il offre des services à l’utilisateur dans un environnement donné. Service : c’est l’ensemble des résultats et des conditions de leur délivrance que le système informatique fournit à l’utilisateur dans un environnement donné. La vie opérationnelle d’un système informatique est perçue, par ses utilisateurs, comme une alternance de trois états : 8 – service rendu : lorsque les résultats fournis et leurs conditions de délivrance sont conformes à ceux du service attendu ; – service dégradé (Degraded Service) lorsque les résultats fournis sont conformes à ceux du service attendu et leurs conditions de délivrance ne sont pas conformes à celles du service attendu ; – service non rendu lorsque les résultats fournis ne sont pas conformes à ceux du service attendu. Défaillance : discordance observée entre le service fournit à l’utilisateur et le service attendu. La défaillance peut être détectée par l’utilisateur (humain ou autre système) du système ou bien par le système lui même. On distingue différents niveaux de défaillance : – la défaillance complète (Complete Failure) ; c’est une discordance sur les résultats du service (par exemple, « plantage » (crash) du système d’exploitation) ; – la défaillance partielle (Partial Failure) ; c’est une discordance sur les conditions de la délivrance des résultats (par exemple, perte de performance, support d’un nombre moindre d’utilisateurs). Les défaillances sont causées par les erreurs. Erreur : c’est la discordance entre une valeur ou une condition, calculée ou observée, et la valeur ou la condition théorique correspondante. Plan de Reprise d’activité : en anglais Disaster Recovery Plan ou DRP permet d’assurer, en cas de crise majeure ou importante d’un centre informatique, la reconstruction de l’infrastructure et la remise en route des applications supportant l’activité de l’organisation. Plan de continuité d’activité (PCA) : Le plan de continuité d’activité quant à lui permet de poursuivre l’activité sans interruption du service. Le PCA est donc défini comme un ensemble de procédures et de dispositifs pouvant être appliqués avant, pendant ou après le déclenchement d’un sinistre.
LES CONCEPTS ET COMPOSANTS
Si l’on regarde en profondeur le paysage informatique d’une entreprise, de nombreux facteurs peuvent influencer la disponibilité des données ou des applications. Tous ces éléments doivent être pris en compte dans un concept de haute disponibilité. Le but de la haute disponibilité revient à assurer la résilience des services exposés et des données qui y sont associées. Cela passe par la mise en place de techniques sur le plan matériel et logique pour pallier leurs éventuels risques de pannes et ceux liés à l’environnement.
LA RESILIENCE MATERIELLE
La disponibilité matérielle est une partie importante du concept de Haute disponibilité. Elle concerne les serveurs, disques durs, switch sans oublier les PC, l’affichage ainsi que les chemins de communication à l’intérieur de l’infrastructure. Une façon simple de réduire le temps d’interruption d’un système d’information est de mettre en place une redondance au niveau des points critiques. Le matériel qui en constitue un, n’y échappe, et assuré sa disponibilité passe par la prise en compte de plusieurs paramètres. Tolérance aux pannes Les systèmes à tolérance de pannes garantissent le meilleur taux de disponibilité matérielle. Chaque composant d’un système à tolérance de panne à une ou plusieurs équivalences. Ceci permet de n’avoir aucun point unique de défaillance dit SPOF (Single Point of Failure). Une vérification du bon fonctionnement de chaque composant doit être fait et un basculement (Fail Over) vers un équivalent si le composant tester fait défaut. De même après que ce dernier remis en état la réintégration devrait se faire sans que l’on est à redémarrer le système (Fail Back). Un système à tolérance de panne est basé sur du matériel et n’inclut aucune protection au niveau application. La tolérance aux pannes matérielles peut parfois nécessiter que les pièces défaillantes soient retirées puis remplacées par de nouvelles pièces pendant que le système reste opérationnel. Un tel système à simple redondance est dit « à tolérance simple » et représente la grande majorité des systèmes tolérants aux pannes. Dans de tels systèmes le taux moyen d’échecs entre les pannes doit être suffisamment élevé pour que les administrateurs aient le temps de réparer l’ancien avant que la sauvegarde ne tombe en panne à son tour. Plus la durée entre les pannes est longue, et plus c’est facile, mais ce n’est pas indispensable dans un système de tolérance aux pannes. 10 La tolérance à la panne pour les serveurs est souvent matérialisée par la mise en place de cluster. Ce dernier est la mise en grappe de plusieurs serveurs physiques pour former un seul et même serveur logique. – Cluster Actif/Passif Dans cette configuration, il y a une véritable notion de maître/esclave entre les nœuds du cluster. En mode actif/passif, un nœud est désigné maître gère la ressource partagé, son contenu est monté, la réplication est effectuée au niveau des blocks sur l’autre nœud. Si le nœud maître tombe, le second prend le relais de la ressource et monte le périphérique. Les données sont toujours présentes et on peut continuer à écrire de façon transparente. Lorsque le serveur anciennement maître du cluster sera de nouveau opérationnel, elle sera désignée comme esclave. Figure 1 : Cluster Actif – Passif – Cluster Actif/Actif Dans cette configuration, le basculement est complètement transparent. Un cluster actif-actif est constitué de serveurs qui fonctionnent ensemble et fournissent un pool de services donné. Si un de ces serveurs s’arrête malencontreusement, les services localisés sur celui-ci sont automatiquement déportés vers les autres serveurs. Il est souvent associé à un système d’équilibrage de charge pour répartir les traitements sur les différents serveurs de la grappe. 11 Figure 2: Cluster Actif – Actif La Fiabilité de l’Infrastructure Informatique La Fiabilité de l’infrastructure décrit toutes les mesures qui permettent le bon fonctionnement du matériel informatique. Cela inclut les centres de données, l’infrastructure électrique, la climatisation, les structures de communications, la protection contre les désastres naturels, la sécurité au niveau de l’accès aux salles… Un exemple basic est d’établir un centre de donnée protégé avec un système de sécurité. Ce centre pouvant être protégé contre les inondations, le feu ou le terrorisme. Cet exemple représente le cœur d’un système d’information moderne. Consolidation du Stockage : La consolidation consiste à redonder tous les composants de ce système de stockage afin d’atteindre la plus haute sécurité : deux unités de contrôle, deux sources d’alimentation et deux connexions réseau. Il devrait également être facile de changer les composants tels que les lecteurs de disque, les ventilateurs ou l’unité d’alimentation. Les chemins de données doivent aussi être redondants, car la mise en miroir sur les réseaux garantit une haute disponibilité. 12 -SAN Le SAN, Storage Area Network, est un réseau hautement disponible dédié au stockage avec des commutateurs ou switches dédiés. Un système de stockage généralement constitué de 2 processeurs de contrôle (Storage Processor – SP) et de baies de disques (Enclosures).Les composants du SAN sont généralement redondés afin d’assurer le maximum de tolérance de pannes : – 2 commutateurs – 2 processeurs de contrôle – 2 alimentations – 2 batteries pour le cache – des grappes de disques en RAID 1, 5, 10 ou 50, … L’accès à un SAN se fait traditionnellement selon le protocole FC, un protocole sans perte (loosless), permettant d’atteindre des débits de 2 à 20GB/s. Pour accéder au SAN, un client devra obligatoirement être équipé d’une carte HBA (Host Bus Adapter) spéciale. Une fois connecté le volume de donnée du SAN est présenté au client comme un nouveau disque dur local (nouvelle lettre qui apparaît dans le système d’exploitation comme lorsque vous ajoutez une clé USB). C’est ce qui différencie concrètement le SAN du NAS : la façon d’accéder aux données. Les fabricants proposent également des configurations basées sur le protocole iSCSI en lieu et place du protocole FC. Le protocole iSCSI est encapsulé dans les trames TCP/IP. Il s’intègre alors tout naturellement au réseau Ethernet existant sans investir massivement dans des switches FC et des cartes HBA très coûteuses. Les clients accèdent au SAN par l’intermédiaire d’un simple pilote iSCSI. Le SAN propose des fonctionnalités ingénieuses : – Il est possible de cloner un volume de plusieurs térabits en un instant : Le SNAPSHOT – Un volume peut être copié localement ou vers un autre SAN – Un volume peut être répliqué en mode synchrone ou en asynchrone vers une autre baie. La possibilité également d ‘écrire simultanément sur 2 volumes distants de plusieurs dizaines de km et en présenter qu’un au client (grâce à la virtualisation de stockage). Le SAN permet la mise en œuvre d’architectures très complexes. Par exemple, une entreprise souhaitant dans le cadre de son plan de reprise d’activité (PRA) que son système d’information soit dupliqué sur un site de secours. De sorte qu’en cas de sinistre le basculement soit transparent pour l’utilisateur final ! 13 Grâce aux technologies portées par les SAN c’est bel et bien possible, bien que très couteux.
TABLE DES FIGURES |