Produit matrice-vecteur
Travaux et bibliothèques pour l’algèbre linéaire
Il existe un nombre significatif de travaux, de spécifications et de réalisations logicielles pour optimiser les briques de base d’algèbre linéaire. Ces travaux et réalisations ont d’abord ciblé le contexte numérique avec des matrices denses. Plus tard, le spectre a été élargi au contexte exact (entier, rationnel, polynômes) en considérant aussi des matrices creuses. Parmi ces réalisations sur CPU, on peut donner quelques exemples : — L’interface BLAS (Basic Linear Algebra Subprograms) qui présente un ensemble de sousroutines de l’algèbre linéaire pour optimiser les opérations sur les vecteurs, les produits matrice-vecteur et les produits matrice-matrice [LHK+79]. Les BLAS ont été mises en œuvre à travers différentes implémentations de référence, particulièrement pour les langages C et Fortan. — La bibliothèque LinBox qui est une une bibliothèque C++ qui fournit différentes primitives d’algèbre linéaire symbolique, y compris le produit matrice-vecteur sur un corps fini avec des matrices denses, creuses ou structurées [LinBox]. — La bibliothèque FFLAS-FFPACK (Finite Field Linear Algebra Subroutines) est une bibliothèque qui utilise les BLAS pour implémenter des opérations d’algèbre linéaire sur les corps finis [FFLAS]. — La bibliothèque MUMPS (MUltifrontal Massively Parallel sparse direct Solver) qui résout en parallèle des systèmes linéaires dans le contexte numérique, en utilisant les méthodes directes [MUMPSa, MUMPSb]. Il existe un certain nombre de réalisations logicielles spécifiques à l’algèbre linéaire issue des calculs de logarithme discret. On peut mentionner, sans prétendre l’exhaustivité, le module d’algèbre linéaire dans le logiciel CADO-NFS [CADO] et le travail de Giorgi et Vialla qui est en cours d’intégration dans la bibliothèque FFLAS-FFPACK [GV14]. Sur GPU, on mentionne la bibliothèque CUSP qui optimise les calculs des graphes et de l’algèbre linéaire creuse dans le contexte numérique pour les plateformes NVIDIA [CUSP]. Cette bibliothèque propose différents formats de représentation de la matrice creuse et algorithmes de produit matrice-creuse–vecteur, qui nous ont beaucoup inspiré. Ces structures de données et algorithmes sont à disposition de l’utilisateur qui choisit le format et l’algorithme les plus adaptés à son type de matrice. Les objectifs du développement des BLAS et des implémentations logicielles correspondantes sont l’optimisation des routines de l’algèbre linéaire en garantissant une portée généraliste (par rapport au contexte applicatif des systèmes linéaires considérés) et la portabilité (par rapport aux architectures sur lesquelles les calculs sont effectués). Notre approche se distingue du fait qu’elle privilégie l’efficacité pour résoudre un type spécifique de systèmes linéaires sur deux types d’architecture donnés. Toutefois, pour pouvoir positionner notre approche par rapport à l’existant, nous proposons dans la section 5.8 une comparaison des performances de notre implémentation avec certaines des bibliothèques qui fournissent un SpMV sur un corps fini F` , avec ` tenant sur plusieurs mots machine.
Formats de représentation de la matrice creuse
Notations
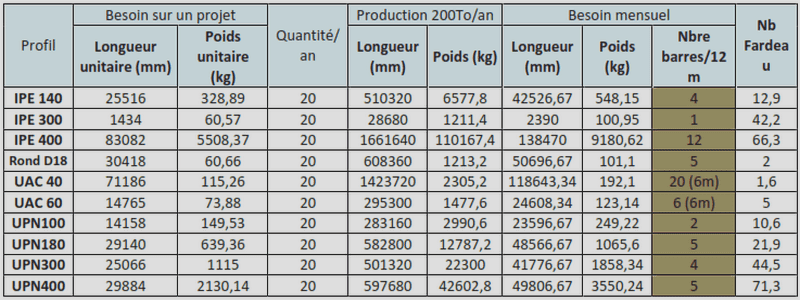
Les entrées sont une matrice creuse A et un vecteur dense u. La sortie est un vecteur dense v tel que v = Au. La matrice A correspond à la matrice complète du système linéaire qu’on cherche à résoudre, si on n’exploite pas de parallélisme sur plusieurs nœuds comme nous l’avons décrit dans le chapitre 4. Dans le cas où on parallélise le calcul sur plusieurs nœuds, la matrice A correspond à la sous-matrice associée au nœud. On note que la densité dans la sous-matrice est la même que pour la matrice totale. N désigne la dimension de A et nNZ le nombre total de ses coefficients non nuls. Les lignes et les colonnes sont indexés de 0 à N − 1 (plutôt que de 1 à N). Cette remarque est aussi valable pour les éléments des vecteurs u et v. 69 Chapitre 5. Produit matrice-vecteur 5.2.1 Coordinate (COO) Le format COO est composé de 3 tableaux row_id, col_id et data de nNZ éléments. Les indices de ligne/colonne ainsi que la valeur sont explicitement stockés pour définir un coefficient non nul de la matrice. Les coefficients non nuls peuvent être dans n’importe quel ordre. Ici, on propose de les ordonner par leur indice de ligne.
Compressed Sparse Row (CSR)
Le format CSR stocke les indices de colonne et les valeurs des coefficients non nuls de A dans 2 tableaux : id et data, chacun de longueur nNZ. Un troisième tableau de pointeurs, ptr, de taille N + 1, indique le début et la fin d’une ligne. Les coefficients non nuls sont ordonnés par leur indice de ligne. Le format CSR élimine le stockage explicite de l’indice de ligne, et de fait réduit la quantité de mémoire nécessaire au stockage de la matrice. Ce format est convenable pour un accès direct à n’importe quelle ligne de la matrice, vu que ptr indique où chaque ligne commence et se termine dans les deux autres tableaux.
ELLPACK (ELL)
Le format ELL étend les tableaux du format CSR à des tableaux N-par-K, où K correspond au nombre maximal de coefficients non nuls par ligne. Pour les lignes qui ont moins de K coefficients non nuls, on procède à un padding (remplissage). Les éléments sont ordonnés par leurs indices de colonne. Comme les lignes ont toutes la même longueur (la longueur correspond au nombre de coefficients non nuls) après le padding, les indices de ligne peuvent être retrouvés à partir de la position de l’élément. Seuls les indices de colonne sont explicitement stockés. Ce format souffre du surcoût dû au padding, lorsque le nombre moyen de coefficients non nuls par ligne est très petit devant K. Une optimisation a été proposée par Vázquez et al. avec le format dit ELLPACK-R (ELL-R) [VGM+09]. Cette variante rajoute un tableau len de longueur N qui indique le nombre de coefficients non nuls dans chaque ligne. Ainsi, les éléments rajoutés par le padding ne sont pas considérés lorsque le produit matrice-vecteur est effectué, mais on continue à avoir le surcoût du padding en mémoire.
Sliced Coordinate (SLCOO)
Le but de ce format est d’améliorer l’utilisation du cache qui limite les performances des autres formats. Ce format s’inspire du logiciel CADO-NFS [CADO] pour l’algèbre linéaire sur CPU et a été introduit pour les GPU par Schmidt et al. dans le contexte de la factorisation d’entiers, où les matrices sont sur F2 [SAD11]. La matrice est divisée en tranches horizontales, où les coefficients non nuls sont ordonnés par leur indice de colonne dans le but de réduire les accès irréguliers au vecteur d’entrée u, par rapport aux accès si les coefficients étaient ordonnés par leur indice de ligne. Comme le format COO, le format SLCOO stocke explicitement les indices de ligne et de colonne et la valeur. Un quatrième tableau ptrSlice indique le début et la fin de chaque tranche. On appelle ce format SLCOO-σ, où le paramètre σ désigne le nombre de lignes de chaque tranche.
Diagonal (DIA)
Ce format s’applique dans le cas où les coefficients non nuls sont sur les diagonales de la matrice. Le format est représenté par deux tableaux : data qui stocke les valeurs et offset qui stocke le décalage de chaque diagonale par rapport à la diagonale principale. L’efficacité d’un format par rapport aux autres, en terme d’efficacité des accès (des schémas d’accès qui sont cache-friendly), dépend de la distribution des coefficients non nuls. La structure que peut avoir la matrice peut privilégier un format. Par exemple, le format DIA a les meilleures performances sur des matrices structurées, où les coefficients non nuls s’alignent sur des diagonales. Une matrice extrêmement creuse sera plutôt adaptée au format COO. Une matrice dont le nombre d’éléments non nuls par ligne ne varie pas beaucoup aura de meilleures performances avec le format ELL. Il est aussi envisageable de combiner deux ou plusieurs formats pour une même matrice en fonction de la densité des parties.