Solution pour confiner les erreurs
Le partitionnement de système est l’une des méthodes déployées globalement comme solution pour tolérer les fautes (Rosenblum et collab., 1996; Avizienis, 1997; Kopetz, 1997). Les composants d’un système peuvent être groupés en zones d’isolation des erreurs où de nouveaux services peuvent être implémentés (Rosenblum et collab., 1996). Un design pattern a été développé pour offrir un modèle de protection où un système isole l’erreur en la redirigeant vers une unité d’atténuation (Hanmer, 2007). Le flux d’erreurs est ainsi empêché de circuler entre les composants, et ce à l’aide d’une structure de confinement. Lencapsulation est une méthode fréquemment utilisée pour confiner les erreurs (Venema, 1992; Voas, 1998; White, 2000; Anderson, Feng, Riddle et Romanovsky, 2003). Contenu à l’intérieur d’un autre composant, le composant est modifié en «l’enveloppant ». De fait, il ne devient accessible que par l’interface du wrapper, limitant ainsi son comportement.
Pareillement, un design pattern a été conçu pour transformer un composant en un wrapper de protection (Saridakis, 2003). Le modèle proposé est complémentaire au pattern Adaptateur (Gamma, Helm, Johnson et Vlissides, 1994). Le pattern Décorateur (Gamma, Helm, Johnson et Vlissides, 1994) est également proposé comme solution où de nouvelles fonctionnalités de tolérance aux fautes sont greffées sur le composant (Edwards, Sitaraman, Weide et Hollingsworth, 2004). Linterception est un autre processus de tolérance aux fautes où les interactions sur un composant sont observées et contrôlées à l’aide d’un autre composant. Ils permettent d’implanter de nouvelles fonctionnalités au composant de manière transparente et sans altération du code source. La solution a d’abord été concrétisée sous forme de réRecteur, où un système peut ainsi raisonner et manipuler une représentation de son propre comportement (Maes, 1987; Fabre, Nicomette, Perennou, Stroud et Zhixue, 1995; Fraser, Badger et Feldman, 1999; Salles, Rodriguez, Fabre et Arlat, 1999; Popov, Riddle, Romanovsky et Strigini, 2001). La propriété réRexive permet d’intercepter des opérations telles que la création d’objets, l’accès aux attributs et les invocations de méthodes, permettant à la fois de détecter les erreurs et de les confiner. La réRexion a ensuite laissé place à 1’« aspectisation» de la tolérance aux fautes, c’est -à-dire l’utilisation de la programmation orientée aspect (Shah et Hill, 2003).
Limitations
Ces approches, pour la plupart, ont été développées dans l’objectif de fournir une sûreté de fonctionnement aux composants COTS, mais également aux micronoyaux COTS, aux systèmes en temps réel (Fabre, Salles, Moreno et Arlat, 1999; Salles, Rodriguez, Fabre et Arlat, 1999 ; Arlat, Fabre, Rodriguez et Salles, 2002; Rodriguez, Fabre et Arlat, 2002) et aux noyaux de systèmes d’exploitation (Fraser, Badger et Feldman, 1999). Pour la plupart, il s’agit de solutions développées pour une situation particulière. Il nous semble difficile de généraliser, voire d’abstraire ces solutions en des solutions généralisables sans d’abord devoir les réévaluer sous un autre contexte : dans un logiciel orienté objet, par exemple. Par conséquent, nous avons tenté de concevoir des solutions qui peuvent être implantées dans les logiciels du paradigme prévalant. Habituellement, l’implantation de tolérance aux fautes nécessite la modification du code source (ajout de fonctionnalités, de classes, de variables, modification d’instances d’objet). L’implantation d’une solution peut être envisagée de façon à minimiser les impacts sur le code, c’est-à-dire en n’effectuant qu’un minimum de modifications afin d’éviter l’apparition de nouvelles dépendances. L’opération ne devrait ni être invasive ni modifier le comportement du logiciel. L’externalisation des solutions contribue à une diminution de l’apparition de nouvelles dépendances intercomposantes. Dans ce document, nous avons tenté de proposer des solutions dont l’implantation ne nécessite qu’un minimum de modifications du code source existant. Les solutions sont basées sur l’encapsulation et sur l’interception de composant. Trois solutions sont soumises à l’évaluation. Évaluées conjointement, leurs différences et ressemblances sont mises au jour. Une solution peut alors être envisagée pour doter un logiciel d’une robustesse supplémentaire. °
FONDAMENTAUX
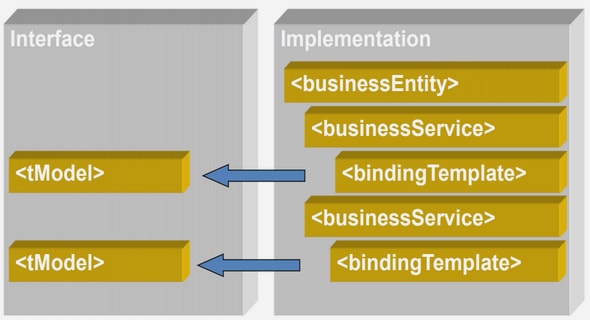
Un dispositif de tolérance aux fautes se présente d’abord sous forme d’unité de confinement d’erreurs. Le terme même d’«unité» ne peut être tenu pour acquis vu la pluralité d’appellations utilisées pour le désigner : wrapper (Venema, 1992; Voas, 1998), opaque wrapper (Black et Singh, 2019), sandbox (Gama, 2OU), protector (Popov, Riddle, Romanovsky et Strigini, 2001), error containment barrier (Hanmer, 2007) ou error-containment region (Kopetz, 1997). Ces termes sont employés pour signifier la même notion, soit celle d’une couche interceptrice. Si wrapper a maintes fois été utilisé depuis son introduction il y a une trentaine d’années (Venema, 1992), c’est qu’il désigne aussi le nom d’un design pattern proposé dans l’ouvrage Design Patterns (Gamma, Helm, Johnson et Vlissides, 1994). En élaborant une structure composée du composant à protéger et deux mécanismes de tolérance aux fautes, un tel dispositif agit comme une barrière entre le composant et son environnement. Le dispositif n’est toutefois pas toujours conçu comme une couche englobante ou comme une enveloppe. Une distinction entre la technique (l’encapsulation à titre d’exemple) et sa concrétisation (l’unité) est nécessaire.
Puisque le mécanisme de confinement correspond à la forme même du dispositif et que ce mécanisme peut être implémenté de différentes manières, le terme «solution » est utilisé comme terme représentant du processus de tolérance aux fautes à l’oeuvre, mais différentes de leur implantation (envelopper, englober, etc.). Une distinction fondamentale peut être posée entre la cause d’une erreur et le phénomène lié à sa manifestation : la faute et l’absence de service (défaillance). On propose dans cette section de définir la singularité de la faute et de ses phénomènes. Les fautes sont ensuite catégorisées dans le but de cerner celles sur lesquelles les solutions agissent. Comme les fautes sont la synthèse d’un événement (cause, origine) et d’un environnement spécifique, les dépendances et interactions intercomposantes sont à prendre en considération. Nous expliquons en quoi l’architecture des logiciels, leur structure plus généralement, facilite la propagation des erreurs. Finalement, les deux mécanismes de tolérance aux fautes implantés dans les solutions sont expliqués: la détection et le confinement d’erreurs.
Pathologie des fautes
Von Neumann et Turing etaIent bien au fait que des erreurs survenaient inévitablement dans les systèmes informatiques. Turing avait déjà posé une distinction entre les types d’erreurs: «Les erreurs de fonctionnement sont dues à une défaillance mécanique ou électrique qui fait que la machine se comporte différemment de ce pour quoi elle a été conçue. [ … ] Par définition [les machines] sont incapables d’erreurs de fonctionnement. En ce sens, on peut vraiment dire que « les machines ne peuvent jamais commettre d’erreur »» (Turing, 1950, p. 449). Lauteur continue en évoquant la possibilité de l’apparition d’autres types d’erreurs: «Les erreurs de conclusion ne peuvent survenir que si un sens est associé aux signaux de sortie de la machine» (Turing, 1950, p. 449). À la manière des machines, les logiciels ne s’exécutent pas toujours comme prévu. Les fautes ont tendance à y demeurer malgré les efforts visant à éviter leur introduction lors de leur conception, de leur implémentation ou lors de leur développement. Ni les tests ni même le débogage ne permettent de détecter toutes les fautes dans leur conception, ainsi la formule de Dijkstra : «Tester un programme démontre la présence de bogues, et non leur absence. » On rencontrerait pas moins de 3,3 erreurs en moyenne par 1000 lignes de code non commentées, et ce, même dans les logiciels de qualité (Myers, 1986).
En raison de leur nature immatérielle et mathématique, les logiciels ne peuvent ni se dégrader avec le temps ni dysfonctionner, mais peuvent «mal fonctionner (malfunction) » (Floridi, Fresco et Primiero, 2015). «Une faute dans la conception d’un ordinateur, par exemple, ne devrait pas être classée comme un dysfonctionnement opérationnel, mais elle compte quand même pour une erreur de calcul» (Fresco et Primiero, 2013, p. 254). Une faute correspond à une erreur dans un composant ou à une erreur dans la conception d’un logiciel (Lee et Anderson, 1990). Les défaillances sont causées par des fautes de conception (Randell, 1975; Lyu, 1996). Comme elles sont liées à des facteurs humains, elles sont imprévisibles donc difficiles à prévenir puisque leur manifestation est inattendue. Une faute de composant (nommée «erreur de fonctionnement » par Turing) est une erreur dans l’état interne d’un composant. Au contraire, une faute de conception (<< erreurs de conclusion») est une erreur dans la conception d’un programme, celui-ci déviant des spécifications fonctionnelles. Ces dernières nécessitent l’application de mécanismes de tolérance aux fautes (Spitzer, FerreU et Ferrell, 2015) et en particulier des méthodes plus efficaces que celles utilisées pour faire face aux fautes de composant (Lee et Anderson, 1990). Les erreurs qui se manifestent dans un logiciel « ne peuvent survenir que si une signification est attachée aux [ … ] sortie[s] (Turing, 1950, p. 449» ). Ainsi, une erreur de calcul advient lorsque m calcule une fonction f qui doit, selon une entrée i, donner 01 et que m donne 02 ;e 01 pour la même entrée (Pïccinini, 2007). Selon leur rapport de finalité, les logiciels sont censés s’exécuter de la manière dont ils ont été conçus. Leur utilisation repose sur un principe d’utilité: ils sont utilisés pour exécuter certaines tâches avec précision. On dira d’un
Remerciements |