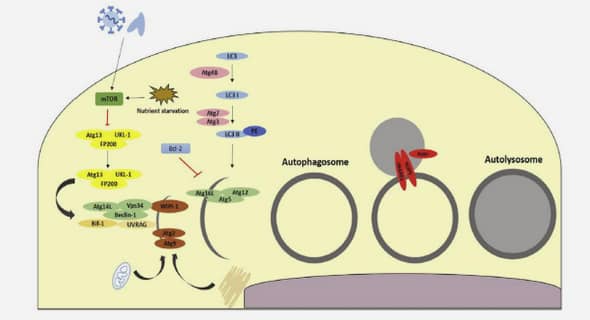
Méthodes statistiques pour l’analyse de données spatiales en écologie
De nombreuses methodes statistiques ont ete developpees pour analyser la distribution spatiale des donnees ecologiques ou pour tenter d’inferer les processus ecologiques sousjacents. On peut distinguer les methodes selon le degre d’information qu’elles fournissent. Certaines methodes sont uniquement descriptives, d’autres permettent de tester des hypoth` eses nulles (parfois plus complexes que l’hypoth`ese de distribution aleatoire ou complete spatial randomness – CSR), et enfin certaines permettent d’ajuster des mod`eles spatiaux. Beaucoup de methodes sont empiriques et ne s’appuient pas sur un mod`ele, qui ne peut ˆetre cree avant d’avoir recolte des donnees suffisantes sur les esp`eces etudiees, leur cycle de vie, leur dynamique, leur demographie et leurs interactions. Ces methodes dependent du type d’echantillonnage des donnees et la plupart sont utilisees pour des etudes exploratoires. On peut distinguer les methodes globales et les methodes locales. Les methodes globales resument l’information spatiale sur toute la zone d’etude (par exemple sous forme d’un indice d’agregation), alors que les methodes locales proposent de quantifier la variation locale (par exemple sous formes d’indices locaux).
Les methodes locales peuvent ˆetre tr`es utiles car elles peuvent mettre en evidence une heterogeneite spatiale de la zone d’etude (le processus ecologique sousjacent varie dans differentes sous-regions de la zone d’etude). Or beaucoup de methodes globales sont basees sur une hypoth`ese de stationnarite du processus, donc d’homogeneite spatiale. Enfin un des objectifs principaux des statistiques spatiales est de mesurer la dependance spatiale. Il y a plusieurs mani`eres de tenir compte de la dependance spatiale selon le type d’echantillonnage et de decoupage de l’espace. Par exemple sur une grille reguli`ere on peut decrire la dependance par des matrices de voisinagea partir de schemas de connexion entre voisins. Par exemple on peut definir un voisinagea 1 niveau par les (4 ou 8) cellules adjacentes. Lorsque les unites d’echantillonnage sont espacees de mani`ere irreguli`ere, on peut utiliser des schemas de connection tels que la triangulation de Delaunay. On peut definir des schemas de connexion de niveau superieur et on peut egalement utiliser des ponderations differentes pour differents niveaux de voisins. Dans le cas de donnees ponctuelles on utilise generalement les distances euclidiennes entre points. Nous presentons bri`evement quelques approches exploratoires puis les approches basees sur des mod`eles, selon que l’on s’interessea la distribution spatiale d’une esp`ece ou au lien spatial entre plusieurs esp`eces.
Les approches exploratoires
E tudier la distribution spatiale d’une espece Souvent la premi`ere question qui se pose lors de l’etude de la distribution spatiale d’une esp`ece (ou pattern) est de savoir s’il y a structuration spatiale par rapporta l’hypoth`ese nulle de distribution spatiale aleatoire (CSR). On caracterise ensuite le pattern spatial non aleatoire suivant qu’il est agrege (interactions positives ou d’attraction entre individus) ou regulier (interactions negatives ou de repulsion entre individus). Donnees ponctuelles (x, y) Pour ce type de donnees la position de chaque individu est connue et les methodes existantes s’appuient sur la theorie des processus ponctuels (Diggle, 2003). Dans ce cas on teste si la distribution est significativement differente d’un processus ponctuel de Poisson (hypoth`ese nulle de CSR). S’il est significativement different on dit que le pattern est structur e spatialement et on le definit comme agrege ou regulier. Les indices K(d) et L(d) de Ripley sont bases sur le calcul du nombre moyen d’individus qui se trouventa une distance d d’un individu choisi au hasard. On calcule ensuite l’evolution de L(d) en fonction de la distance d.
La comparaisona des graphiques calcules pour des pattern aleatoires generes par simulation de Monte Carlo permet de tester la structure spatiale du pattern. Donnees ponctuelles (x, z), (x, y, z) Lorsque l’attribut z corresponda des comptages d’individus dans des quadrats, on peut utiliser des methodes de ratio variance/moyenne, basees sur le fait que des donnees provenant d’un processus de Poisson (hypoth`ese CSR) devraient avoir un ratio de 1 (Dale et al, 2002). D’autres methodes sont prevues pour des echantillonnages exhaustifs de l’espace qui est divise en cellules contigu¨es, telles les methodes de quadrat variance en une dimension (le long d’un transect) et block quadrat variance en deux dimensions. Dans ces methodes, on calcule la variance en se basant sur des couples d’unites d’echantillonnage adjacents au lieu de la totalite comme dans les methodes de ratio variance/moyenne. Enfin beaucoup de methodes s’interessenta quantifier l’autocorrelation spatiale des donnees en fonction de la distance. On parle de donnees autocorrelees ou de dependance spatiale lorsque des unites d’echantillonnage proches ont des valeurs plus similaires que des unites eloignees. Le principe de ces methodes, apparues dans le domaine des geostatistiques (Chil`es & Delfiner, 1999), est proche des methodes de quadrat variance en rempla¸cant les blocs de quadrats par les unites d’echantillonnage (sites). La technique la plus utilisee est basee sur l’etude du variogramme experimental (de l’echantillon), obtenu en calculant la variance moyenne des attributs z pour tous les couples de sites distants de d, pour une gamme de distances d. Le plus souvent on decoupe la distance maximale entre sites en intervalles eta chaque intervalle de distance on associe une variance moyenne.
L’idee generale de ces methodes est que l’autocorrelation diminue (et donc la variance augmente) avec la distance jusqu’`a un maximum est atteint au bout d’une distance d qu’on appelle en geostatistiques la portee. La portee peut ˆetre vue comme l’estimation de la taille moyenne des aggregats et des “trous”. D’autres mesures d’autocorrelation utilisees en ecologie sont l’indice I de Moran et l’indice c de Geary qui permettent de tester l’hypoth`ese de CSR. Ces methodes sont des methodes globales qui supposent l’homogeneite spatiale du processus. Des methodes locales ont egalement ete proposees. Anselin (1995) a adapte les indices de Moran et de Geary pour obtenir un indice local qui permet d’analyser comment l’autocorr elation spatiale varie dans la zone d’etude. Enfin, Perry et al (1999) proposent la methode SADIE (Spatial Analysis by Distance InDicEs) qui permet de detecter des agregats en attribuanta chaque site un indice d’agregation et en proposant un test de l’hypoth`ese nulle de CSR.
Distribution spatiale d’une plante-hˆote, le plantain lanceole, et de son pathog`ene, l’o¨ıdium Ce jeu de donneesa grande echelle s’interessea la repartition d’un champignon, l’o¨ıdium (Podosphaera plantaginis), infectant sa plante hˆote sauvage, le plantain lanceole (Plantago lanceolata). La zone d’etude s’etend sur une surface de 50 × 70 km dans les ˆıles °Aland, en Finlande. Des mesures ont ete effectuees pendant 7 annees consecutives (2001-2008) sur environ 3000 prairies (en general < 1 ha), en fin de saison d’infection (septembre). Pour chaque prairie la surface occupee par le plantain et la presence-absence d’o¨ıdium a ete notee (voir figure 1.3). Des parties de ce jeu de donnees ont ete etudieesa plusieurs reprises par Laine (2004); Laine & Hanski (2006); Soubeyrand et al. (2009), Ces auteurs ont propose une etude de la dynamique spatio-temporelle du pathog`ene, formee d’extinctions et de recolonisations frequentes, soit par une etude de type GLMM (Laine & Hanski, 2006), soit par des mod`eles mecanistes (Soubeyrand et al., 2009). L’etude de Laine & Hanski (2006) montre que les colonisations sont plus frequentesa l’est de °Aland, ce qui pourrait ˆetre reliea la dispersion des spores d’o¨ıdium dans la direction dominante du vent, et que l’occurrence et la persistence du pathog`ene est plus probablea proximite des cˆotes, ce qui sugg`ere des facteurs physiques de l’environnement (humidite, temperature, precipitations, vents).
Nous proposons d’etudier ces donnees en termes d’assemblages des deux especes. L’avantage de la notion d’assemblage d’esp`eces telle que nous l’avons definie (i.e. sans autocorrelation spatiale) est de pouvoir etre directement applicablea ce jeu de donneesa grande echelle, ainsi qu’au premier jeu de donnees de comptages d’especes de puceronsa une echelle bien plus fine (les feuilles). Il serait difficile d’introduire un type de dependance spatiale entre donnees dans la methode de classification basee sur les mod`eles de melange, qui nous permet de definir les assemblages, tel qu’il puisse s’adapter aux deux cas. Une analyse sur une partie de ce jeu de donnees (annees 2001–2006), basee sur une definition des assemblages d’especes par une classificationa l’aide de mod`eles de melange de lois gaussiennes bivariees, est presentee dans le chaptire 4. Pour obtenir des donnees d’abondances d’esp`eces pseudo-continues qui soient plus adapteesa l’hypoth`ese gaussienne, nous proposons d’agreger le jeu de donnees dans l’espace (on utilise une grille reguliere avec des cellules de cˆote 1.5 km) et dans le temps (sur les annees 2001–2006). Nous obtenons 600 sites occupes par le plantain, dont 340 sont infectes par l’o¨ıdium. Ce jeu de donnees nous permet egalement de voir les limites des methodes de classification basees sur les mod`eles de melange de gaussiennes bivariees, qui ne sont pas adaptees pour tous les types de donnees. Ce constat a motive la recherche de classes de distributions plus generiques que les lois gaussiennes multivariees, qui puissent s’adaptera plusieurs types de donnees, dans les parties III et IV. Dans le chapitre 9 nous discutons de la possibilite de prise en compte des donnees brutes, en utilisant des loisa structure hierarchique definies dans la partie III de cette th`ese.
partie I Contexte ecologique et statistique |