Extraction d’information et Entités Nommées
Origine et définitions des Entités Nommées
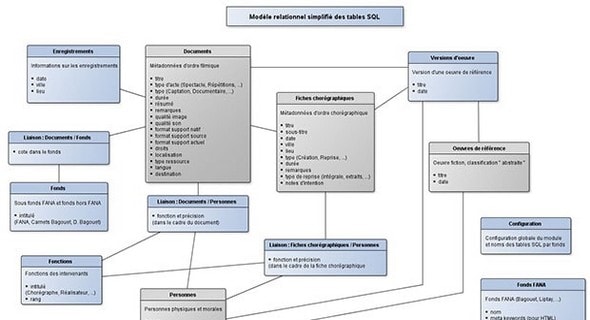
Les cadres de l’extraction d’information L’extraction d’Information a émergé de besoins d’accès au contenu des documents [Poibeau, 2003]. Comme le rappellent R. Gaizauskas et Y. Wilks [Gaizauskas & Wilks, 1998], l’EI doit être distinguée de la Recherche d’Information (ou RI), par les objectifs et les méthodes qu’elles emploient. La RI est traditionnellement une approche relativement pauvre en connaissance, qui utilise les concepts de la Théorie de l’Information [Shannon, 1948] pour retourner un ensemble de documents pertinents vis-à-vis d’une requête ; le texte est conçu comme un sac de mots constituant ses unités d’indexation. À l’inverse, l’EI est typiquement une application de TAL, qui hérite des recherches menées en Intelligence Artificielle sur les systèmes à base de règles, dits symboliques, riche en connaissances ; l’objectif n’est plus de retourner des documents, mais d’extraire des informations structurées à partir de texte, ce qui suppose une analyse des mots en contexte. Les domaines d’application de l’EI peuvent être extrêmement divers. Pour ne citer qu’un exemple, le domaine médical a donné lieu à un large corps de travaux, dont les premiers, d’après N. Sager, remontent à 1969 [Sager, 1982]. Les textes de rapports cliniques par exemple sont rédigés dans un style spécifique et les connaissances qui y sont véhiculées, comme les symptômes, les maladies sont propres au domaine (pour des travaux récents, voir [Grouin et al., 2011]). Nous ne nous intéresserons pas particulièrement à ces sous-langages dans cette thèse, mais à des informations qui relèvent de domaine plus généraux et tels qu’on peut les trouver dans des corpus de presse. Une manière commune de concevoir L’EI est de modéliser le type d’information recherchée sous forme de cadres ou grilles (« templates ») pour lesquels les systèmes remplissent des champs d’information, comme pour une base de données. C’est du moins ainsi qu’ont été proposées les premières campagnes d’évaluation d’EI, MUC (Message Understanding Conference). L’une des premières tâches d’EI était l’extraction d’informations sur les attaques terroristes dans des corpus de presse28 (MUC-3 ; [Sundheim, 1991]). Il s’agissait d’identifier le type d’incident (parmi une liste) rapporté dans un article, ainsi qu’un certain nombre d’informations concernant ce cadre. Le cadre était organisé en fonction des rôles majeurs liés à ce cadre (les champs), l’Incident (« Incident »), son Auteur (« Perpetrator »), la Cible Physique (« Physical Target ») et la Cible Humaine (« Human Target »), comme indiqué dans le tableau (5.1).
Les entités nommées
C’est lors de la sixième campagne MUC [Grishman & Sundheim, 1995] que des sous-tâches de l’EI ont été distinguées. Au lieu de proposer uniquement une grille de scenario-type à remplir comme cela avait été le cas pour les campagnes précédentes, les organisateurs ont défini trois tâches complémentaires : la tâche d’Entités Nommées, la tâche d’Éléments de Cadre, la tâche de Coréférence. Nous décrirons uniquement la première. La tâche d’Entité Nommées a émergé d’un besoin d’identifier des sous-tâches d’EI suffisamment indépendantes du domaine considéré pour être réutilisables. Les EN (ou Enamex pour « Entity name expression ») étaient de trois types (Personne, Lieu, Organisation)29 et la tâche consistait à insérer des balises SGML autour de chaque nom propre relevant d’un des types, comme illustré en (163) (exemple tiré de [ibid. : 6]). 163)Mr. Dooner met with Martin Puris , president and chief executive officer of Ammirati & Puris , about McCann ‘s acquiring the agency with billings of $400 million , but nothing has materialized.