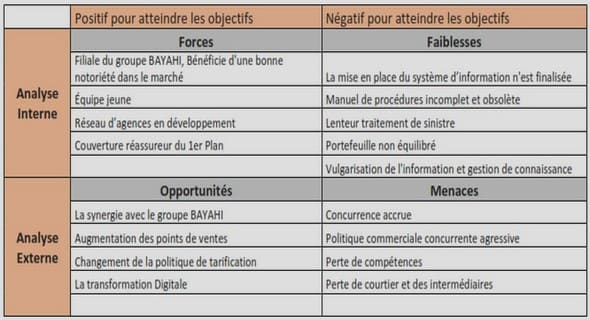
Nuées dynamiques
L’algorithme des nuées dynamiques est une généralisation de l’algorithme des kmeans, où chaque classe est représentée non pas par son barycentre (qui peut être extérieur à la classe) , mais par un noyau, qui peut être un sous-ensemble de points de la classe, un axe principal ou un plan principal, etc. Ce noyau s’avère parfois plus représentatif de la classe. La présentation qu’en donne Michel Volle (Volle M. , 1978) convient parfaitement pour expliquer les principes de la méthode et introduire les concepts qui lui sont propres. Supposons un ensemble de données st sur lequel sont définies une distance d(x, y) entre éléments et une distance D (X , Y ) entre classes. Prenons au hasard k sousensembles de p points chacun dans st ; nous appellerons chacun de ces sous-ensembles un « noyau ». Ces noyaux nous permettent de définir une partition de st en k classes, chaque classe comprenant les éléments qui sont plus proches d’un des noyaux que de tous les autres noyaux. A partir de cette partition , on définit une nouvelle famille de noyaux en associant à chaque classe de la partition l’ensemble de p points qui en est le plus proche. Puis on recommence : à cette nouvelle famille de noyaux va être associée une nouvelle partition, etc.
Il est facile de démontrer que le procédé converge sous certaines conditions : on finit par aboutir à une partition et à une famille de noyaux optimaux. Ainsi la méthode des nuées dynamiques permet de construire par itération, à partir d’une famille absolument quelconque de noyaux, une partit ion en k classes. Mais cett e construction contient une part d’arbitraire: la partition obtenue dépend du choix initial des noyaux. Pour compenser dans une certaine mesure cet arbitraire, on applique la méthode plusieurs fois de suite, en partant à chaque fois d’une famille différente de noyaux tirée au hasard. On obt ient ainsi plusieurs par titions en k classes. Si l’on considère deux éléments quelconques, ils peuvent avoir été classés ensemble dans certaines de ces partitions, et classés séparément dans d’autres. On appelle forme forte un ensemble d’éléments qui auront été classés ensemble dans toutes les classifications. Ces formes fortes déterminent une part ition de E qui peut fort bien contenir plus de k classes. Les formes fortes qui ne comprennent qu’un élément ne présentent pas d’intérêt , car elles concernent des éléments qui semblent « inclassables ». Par contre, les formes fortes qui comprennent beaucoup d’éléments sont intéressantes : pour qu’un groupe d’éléments ait résisté aux aléas dus aux choix des différentes familles de noyaux, il fallait qu’il fût bien homogène.
Présentation du package NbClust
Le package bClust de R est développé afin d’aider l’utilisateur à déterminer le bon nombre de classes dans un jeu de données. Trente indices de validation sont proposés dans sa version actuelle, ainsi que des méthodes hiérarchiques (CAH) et non hiérarchiques (K-means) de classification. L’avantage de ce package est qu’il permet d’appliquer simultanément plusieurs indices et de déterminer la meilleure partition parmi toutes les partitions obtenues en combinant, nombre de classes minimal et maximal, les distances (distance euclidienne, distance maximale, distance Manhattan, distance de Canberra, distance binaire ou distance de Minkowski) et les méthodes d’agrégation (Ward.Dl, Ward.D2, Saut minimum, Saut maximum, Saut moyen, McQuitty, Médiane ou Centroide). bClust propose ainsi le nombre pertinent de classes pour chacune des trente (30) critères utilisés, soit par le nombre minimal ou maximal de l’indice, soit par comparaison de l’indice par rapport à la valeur critique, soit aussi par des méthodes graphiques. Ces dernières concernent l’indice de Hubert et celui de Dindex. Ainsi, le nombre optimal de classes pour ces deux indices est déterminé par le pic le plus significatif en observant la courbe représentant les dérivées secondes des indices. Le choix optimal du nombre de classes sera guidé par les résultats fournis par les trente (30) indices. Autrement dit , NbClust propose d’utiliser la règle du vote majoritaire. La liste des trente (30) indices utilisés, avec leurs caractéristiques et références, est présentée à la table 1.2 ( Charrad et al., 2014
Méthode neuronale : Cartes auto-organisatrices (SOM) Ce chapitre présente une nouvelle famille de classification automatique de données basée sur les réseaux de neurones ar tificiels. La méthode basée sur les cartes autoorganisatrices a été ut ilisée avec succès notamment dans la reconnaissance des formes et le t raitement des images. Désignée en anglais par Self-Organizing Maps (SOM) , cette méthode fût inventée par Kohonen (Kohonen, 1984). C’est un réseau de neurones art ificiels soumis à un apprent issage non supervisé pour projeter des données de haute dimensionnalité sur un espace de faible dimension dans le but d’en faire des tâches de discrétisation, de quant ification vectorielle ou de classification. Outre leur capacité de classification, elles permettent de renseigner sur la proximité des classes en préservant la topologie des données. Dans ce qui suit, nous allons plus nous inspirer de la thèse de doctorat de Chantal Hajjar [19] pour expliquer le principe des cartes auto-organisatrices en détaillant ses algorithmes d’apprent issage. Nous allons également parler de l’évaluation de la performance de la carte, du choix de ses paramètres d’apprent issage, de ses critères de convergence et enfin de son rôle dans la classification de données. Étant donné que, dans ce mémoire, notre étude porte sur l’apprent issage non supervisé, nous ne présentons pas les aut res types d’apprent issage dont, notamment, l’apprent issage supervisé ou encore par correction des erreurs et l’apprent issage par renforcement (Haykin, 1994).
Apprentissage séquentiel
En désignant par K le nombre total des neurones de la carte, le vecteur référent du neurone k est donné par Wk avec k E 1, … , K. Chaque itération t de l’apprentissage séquentiel comprend deux étapes. La première étape consiste à choisir au hasard une observation x(t) de l’ensemble 0, et à la présenter au réseau dans le but de déterminer son neurone vainqueur. Le neurone vainqueur d’une observation est le neurone dont le vecteur référent en est le plus proche au sens d’une distance donnée (ex: distance euclidienne). Si c est le neurone vainqueur du vecteur x(t) , c est déterminé comme suit: d(wc(t), x(t)) = min d(wk(t), x(t)) Dans la deuxième étape, le neurone vainqueur est activé. Son vecteur référent est mis à jour pour se rapprocher du vecteur d’entrée présenté au réseau. Cette mise à jour ne concerne pas seulement le neurone vainqueur, mais également les neurones qui lui sont voisins et qui voient alors leurs vecteurs référents s’ajuster vers ce vecteur d’ent rée (voir figure 3.2). L’amplitude de cet ajustement est déterminée par la valeur d’un pas d’apprent issage a(t) et la valeur d’une fonction de voisinage h(t) .
Le paramètre a(t) règle la vitesse de l’apprent issage. Il est initialisé avec une grande valeur au début puis décroît avec les itérations en vue de ralentir au fur et à mesure le processus d’apprent issage. La fonction h(t) définit l’appartenance au voisinage. Elle dépend à la fois de l’emplacement des neurones sur la carte et d’un certain rayon de voisinage. Dans les premières itérations, le rayon de voisinage est assez large pour mettre à jour un grand nombre de neurones voisins du neurone vainqueur, mais ce rayon se rétrécit progressivement pour ne contenir que le neurone vainqueur avec ses voisins immédiats, ou bien même le neurone vainqueur seulement. La règle de mise à jour des vecteurs référents est la suivante : k E 1, … ,K où c est le neurone vainqueur du vecteur d’entrée x(t) présenté au réseau à l’itération t et hkc(t) est la fonction de voisinage qui définit la proximité entre les neurones k et c. Il décrit comment les neurones dans la proximité du vainqueur c sont entraînés dans le mouvement de correction. On ut ilise en général : – où ê et k sont respectivement l’emplacement du neurone c et du neurone k sur la carte. (J est le coefficient de voisinage à l’itération t du processus d’apprent issage. Son rôle est de déterminer un rayon de voisinage autour du neurone vainqueur.
Résumé |