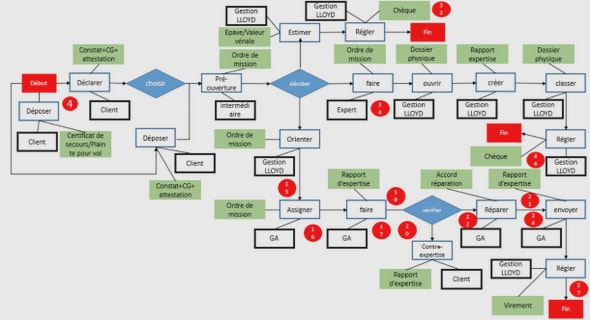
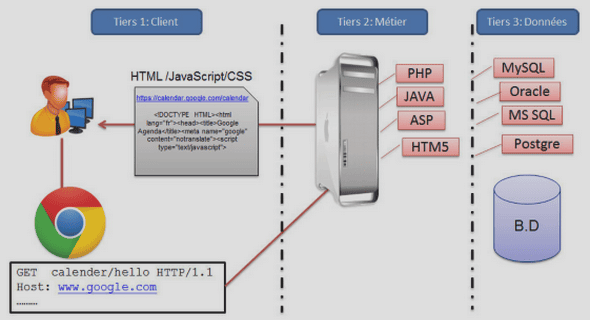
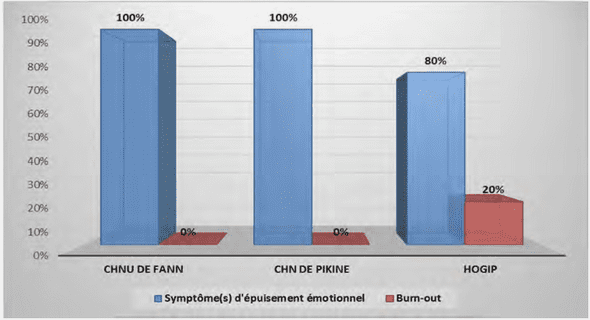
Les méthodes dans la reconnaissance faciale
Les méthodes de reconnaissance faciales peuvent être classées en trois grandes approches.
Une approche globale dans laquelle on analyse le visage (l’image pixellisée du visage) dans son entier, une approche locale basée sur un modèle dans laquelle le système essaie de détecter, regrouper et reconnaître les différents éléments constitutifs du visage tel que le nez, les yeux et la bouche. Enfin, il existe des méthodes hybrides qui combinent les deux approches précédentes.
Méthode globale
Les méthodes globales sont basées sur des techniques d’analyse statistique bien connues. Il n’est pas nécessaire de repérer certains points caractéristiques du visage (comme les centres des yeux, les narines, le centre de la bouche, ….) à part pour normaliser les images. Dans ces méthodes, les images de visage (qui peuvent être vues comme des matrices de valeurs de pixels) sont traitées de manière globale et sont généralement transformées en vecteurs, plus faciles à manipuler.
L’avantage principal des méthodes globales est qu’elles sont relativement rapides à mettre en œuvre et que les calculs de base sont d’une complexité moyenne. En revanche, elles sont très sensibles aux variations d’éclairement, de pose et d’expression faciale.
Ceci se comprend aisément puisque la moindre variation des conditions de l’environnement ambiant entraîne des changements inéluctables dans les valeurs des pixels qui sont traités directement.
Ces méthodes utilisent principalement une analyse de sous-espaces de visages. Cette expression repose sur un fait relativement simple : une classe de « formes » qui nous
intéresse (dans notre cas, les visages) réside dans un sous-espace de l’espace de l’image d’entrée.
Méthode locale
Les méthodes locales, basées sur des modèles, utilisent des connaissances a priori que l’on possède sur la morphologie du visage et s’appuient en général sur des points caractéristiques de celui-ci. Kanade présenta un des premiers algorithmes de ce type en détectant certains points ou traits caractéristiques d’un visage puis en les comparants avec des paramètres extraits d’autres visages. Ces méthodes constituent une autre approche pour prendre en compte la non-linéarité en construisant un espace de caractéristiques local et en utilisant des filtres d’images appropriés, de manière à ce que les distributions des visages soient moins affectées par divers changements.
Toutes ces méthodes ont l’avantage de pouvoir modéliser plus facilement les variations de pose, d’éclairage et d’expression par rapport aux méthodes globales.
Méthodes hybrides
Les méthodes hybrides permettent d’associer les avantages des méthodes globales et locales en combinant la détection de caractéristiques géométriques (ou structurales) avec l’extraction des caractéristiques d’apparence locales. Elles permettent d’augmenter la stabilité de la performance de reconnaissance lors de changements de pose, d’éclairement et d’expressions faciales.
Principales difficultés de la reconnaissance de visage
Pour le cerveau humain, le processus de la reconnaissance de visages est une tâche visuelle de haut niveau. Bien que les êtres humains puissent détecter et identifier des visages dans une scène sans beaucoup de peine, construire un système automatique qui accomplit de telles tâches représente un sérieux défi. C e défi est d’autant plus grand lorsque les conditions d’acquisition des images sont très variables. Il existe deux types de variations associées aux images de visages : inter et intra sujet. La variation inter-sujette est limitée à cause de la ressemblance physique entre les individus. Par contre la variation intra-sujette est plus vaste. Elle peut être attribuée à plusieurs facteurs que nous analysons ci-dessous.
Changement d’illumination
L’apparence d’un visage dans une image varie énormément en fonction de l’illumination de la scène lors de la prise de vue (voir figure 1.05). Les variations d’éclairage rendent la tâche de reconnaissance de visage très difficile. En effet, le changement d’apparence d’un visage du à l’illumination, se révèle parfois plus critique que la différence physique entre les individus, et peut entraîner une mauvaise classification des images d’entrée.
Expressions faciales
Un autre facteur qui affecte l’apparence du visage est l’expression faciale. La déformation du visage qui est due aux expressions faciales est localisée principalement sur la partie inférieure du visage. L’information faciale se situant dans la partie supérieure du visage reste quasi invariable. Elle est généralement suffisante pour effectuer une identification.
Toutefois, étant donné que l’expression faciale modifie l’aspect du visage, elle entraîne forcément une diminution du taux de reconnaissance. L’identification de visage avec expression faciale est un problème difficile qui est toujours d’actualité et qui reste non résolu.
Présence ou absence des composants structurels
La présence des composants structurels telle que la barbe, la moustache, ou bien les lunettes peut modifier énormément les caractéristiques faciales telles que la forme, la couleur, ou la taille du visage. De plus, ces composants peuvent cacher les caractéristiques faciales de base causant ainsi une défaillance du système de reconnaissance. Par exemple, des lunettes opaques ne permettent pas de bien distinguer la forme et la couleur des yeux, et une moustache ou une barbe modifie la forme du visage.
Occultations partielles
Le visage peut être partiellement masqué par des objets dans la scène, ou par le port d’accessoire tels que lunettes, écharpe… Dans le contexte de la biométrie, les systèmes proposés doivent être non intrusifs c’est-à-dire qu’on ne doit pas compter sur une coopération active du sujet. Par conséquent, il est important de savoir reconnaître des visages partiellement occultés.
Conclusion
La biométrie offre beaucoup plus d’avantages que les méthodes existantes d’authentification personnelle telles que les clefs, les numéros d’identificat ion (ID), les mots de passe et les cartes magnétiques. En effet, elle fournit encore plus de sûreté et de convenance ce qui engendre d’énormes avantages économiques et elle comble les grandes failles de sécurité des mots de passe. La reconnaissance du visage est un domaine très actif dans la Vision par Ordinateur et dans la Biométrie. Elle a été étudiée vigoureusement il y a déjà 25 ans et sa finalité est de produire des applications de sécurité, des applications en robotique, d’interface homme-machine, applications pour les appareils photo numériques, jeux et divertissement.
LES TECHNIQUES POUR LA RECONNAISSANCE FACIALE
Introduction
Dans ce chapitre nous présentons les algorithmes utilisés pour la réalisation de la reconnaissance faciale puis nous aborderons l’Oppen CV ainsi que de toutes ses fonctionnalités. Enfin, nous terminerons le chapitre par la présentation de l’Android.
Les algorithmes
Algorithme de Viola et Jones
Une avancée majeure dans le domaine a été réalisée par les chercheurs Paul Viola et Michael Jones en 2001. Ces derniers ont proposé une méthode basée sur l’apparence (Appearance-based methods). La méthode de Viola et Jones est une méthode de détection d’objet dans une imagenumérique, elle fait partie des toutes premières méthodes capables de détecter efficacement et en temps réel des objets dans une image. Inventée à l’origine pour détecter des visages, elle peut également être utilisée pour détecter d’autres types d’objets comme des voituresou des avions. La méthode de Viola et Jones est l’une des méthodes les plus connues et les plus utilisées, en particulier pour la détection de visages et la détection de personnes.
En tant que procédé d’apprentissage supervisé, la méthode de Viola et Jones nécessite de quelques centaines à plusieurs milliers d’exemples de l’objet que l’on souhaite détecter, pour entraîner un classifieur. Une fois son apprentissage réalisé, ce classifieur est utilisé pour détecter la présence éventuelle de l’objet dans une image en parcourant celle-ci de manière exhaustive dans toutes les tailles possibles.
Considérée comme étant l’une des plus importantes méthodes de détection d’objet, la méthode de Viola et Jones est notamment connue pour avoir introduit plusieurs notions de reprises ensuite par de nombreux chercheurs en vision par ordinateur, à l’exemple de la notion d’image intégrale ou de la méthode de classification construite comme une cascade de classifieurs boostés.
Cette méthode bénéficie d’une implémentation sous licence BSD dans OpenCV, la bibliothèque utilisée dans notre application.
Principe
La méthode de Viola et Jones consiste à balayer une image à l’aide d’une fenêtre de détection de taille initiale 24px par 24px (dans l’algorithme original) et de déterminer si un visage y est présent. Lorsque l’image a été parcourue entièrement, la taille de lafenêtre est augmentée et le balayage recommence, jusqu’à ce que la fenêtre fasse la taille de l’image.
L’augmentation de la taille de la fenêtre se fait par un facteur multiplicatif de 1.25. Le balayage, quant à lui, consiste simplement à décaler la fenêtre d’un pixel. Ce décalage peut être changé afin d’accélérer le processus, mais un décalage d’un pixel assure une précision maximale.
Cette méthode est une approche basée sur l’apparence, qui consiste à parcourir l’ensemble de l’image en calculant un certain nombre de caractéristiques dans des zones rectangulaires qui se chevauchent. Elle a la particularité d’utiliser des caractéristiques très simples mais très nombreuses. Il existe d’autres méthodes mais celle de Viola et Jones est la plus performante à l’heure actuelle. Ce qui la différencie des autres est notamment :
– l’utilisation d’images intégrales qui permettent de calculer plus rapidement les caractéristiques.
– la sélection par boosting des caractéristiques.
– la combinaison en cascade de classifieurs boostés, apportant un net gain de temps d’exécution.
Les caractéristiques
Une caractéristique est une représentation synthétique et informative, calculée à partir des valeurs des pixels. Les caractéristiques utilisées ici sont les caractéristiques pseudohaar.
Elles sont calculées par la différence des sommes de pixels de deux ou plusieurs zones rectangulaires adjacentes.
Prenons un exemple :
Voici deux zones rectangulaires adjacentes, la première en blanc, la deuxième en noire.
Les caractéristiques seraient calculées en soustrayant la somme des pixels noirs à la somme des pixels blancs. Les caractéristiques sont calculées à toutes les positions et à toutes les échelles dans une fenêtre de détection de petite taille, typiquement de 24×24 pixels ou de 20×15 pixels. Un très grand nombre de caractéristiques par fenêtre est ainsi généré, Viola et Jones donnant l’exemple d’une fenêtre de taille 24 x 24 qui génère environ 160 000 caractéristiques.
L’image suivante présente des caractéristiques pseudo-haar à seulement deux caractéristiques mais il en existe d’autres, allant de 4 à 14, et avec différentes orientations. Malheureusement, le calcul de ces caractéristiques de manière classique coûte cher en terme de ressources processeur, c’est là qu’interviennent les images intégrales.
Cascade de classifieurs
La méthode de Viola et Jones est basée sur une approche par recherche exhaustive sur l’ensemble de l’image, qui teste la présence de l’objet dans une fenêtre à toutes les positions et à plusieurs échelles. Cette approche est cependant extrêmement coûteuse en calcul. L’une des idées-clés de la méthode pour réduire ce coût réside dans l’organisation de l’algorithme de détection en une cascade de classifieurs. Appliqués séquentiellement, ces classifieurs prennent une décision d’acceptation ; la fenêtre contient l’objet et l’exemple est alors passé au classifieur suivant, ou de rejet ; la fenêtre ne contient pas l’objet et dans ce cas l’exemple est définitivement écarté. L’idée est que l’immense majorité des fenêtres testées étant négatives (c.-à-d. ne contiennent pas l’objet), il est avantageux de pouvoir les rejeter avec le moins possible de calculs. Ici, les classifieurs les plus simples, donc les plus rapides, sont situés au début de la cascade, et rejettent très rapidement la grande majorité des exemples négatifs. Cette structure en cascade peut également s’interpréter comme un arbre de décision dégénéré, puisque chaque nœud ne comporte qu’une seulebranche.
Prétraitement
La phase de prétraitement vient après la phase de détection. Elle permet de préparer l’image du visage de telle sorte qu’elle soit exploitable. On l’appelle aussi phase de normalisation puisqu’elle ramène à un format prédéfini toutes les images extraites de l’image brute. Elle consiste généralement en un centrage du visage dans l’image et une élimination des zones non informatives.
Pour garantir la bonne performance du système de reconnaissance de visages, il est important que toutes les images soient de taille identique, à la même échelle et au même format concernant les couleurs (par exemple, les images couleur sont parfois converties en niveaux de gris). Ceci améliore incontestablement le fonctionnement de l’étape d’extractionde signatures et par conséquent la qualité de cette dernière. La normalisation est constituée de deux processus : géométrique et photométrique. La normalisation géométrique est nécessaire parce que la taille du visage à l’intérieur de l’image acquise peut varier en fonction de la distance entre le module d’acquisition et la personne.
L’étape de normalisation photométrique tente d’éliminer ou de réduire les effets de l’illumination de l’image.
Normalisation Géométrique
En utilisant un algorithme de reconnaissance se basant sur la réduction de l’espace, nous ne pouvons pas négliger un point très important qui est la normalisation géométrique des images de visage. Cette normalisation géométrique consiste à extraire la zone du visage de l’image originale, ensuite une rotation du visage est effectuée afin d’aligner l’axe des yeux avec l’axe horizontal. Enfin, une réduction proportionnelle à la distance entre lescentres des deux yeux est appliquée. On obtient alors une image de visage dont la distance entre les centres des yeux est fixe. Les dimensions de l’image du visage sont calculées à partir de la distance à obtenir entre les centres des deux yeux.
Table des matières
REMERCIEMENTS
TABLE DES MATIERES
NOTATIONS
ABREVIATIONS
INTRODUCTION
CHAPITRE I PRESENTATION DE LA BIOMETRIE ET DE LA RECONNAISSANCE FACIALE
1.1. Introduction
1.2. Définitions
1.3. Les systèmes biométriques
1.4. Les techniques biométriques
1.4.1. L’analyse morphologique (physiologique)
1.4.2. L’analyse comportementale
1.5. Module des systèmes biométriques
1.5.1. Module de capteur biométrique
1.5.2. Module d’extraction des données
1.5.3. Module création d’une signature
1.5.4. Module comparaison
1.5.5. Module base de données
1.6. La Reconnaissance faciale
1.6.1. Système de reconnaissance de visages
1.6.2. Architecture générale
1.6.3. Les méthodes dans la reconnaissance faciale
1.6.4. Principales difficultés de la reconnaissance de visage
1.7. Conclusion
CHAPITRE 2 LES TECHNIQUES POUR LA RECONNAISSANCE FACIALE
2.1. Introduction
2.2. Les algorithmes
2.2.1. Algorithme de Viola et Jones
2.3. La reconnaissance de visage
2.3.1. Sous système de traitement d’images
2.3.2. Sous-système d’identification
2.3.3. Sous-système de base de données
2.4. Méthode de reconnaissance
2.5. L’Open CV
2.5.1. Définition de l’Open CV
2.6. Structure de la librairie Open CV
2.6.1. CV & CVAUX
2.6.2. HIGHGUI
2.6.3. CXCORE
2.7. Le système Android
2.7.1. Open source
2.7.2. Gratuit (ou presque)
2.7.3. Facile à développer
2.7.4. Facile à vendre
2.7.5. Flexible
2.7.6. Complémentaire
2.7.7. La plateforme Android
2.7.8. Utilités et limites
2.8. Conclusion
CHAPITRE 3 MISE EN ŒUVRE DE L’APPLICATION
3.1. Introduction
3.2. Environnement utilisé
3.2.1. Environnement matériel ou le hardware
3.2.2. Environnement immatérielle ou le software
3.3. Méthodologie
3.3.1. Quelques exemples de fonctions dans Open CV qu’on a utilisé
3.4. Applications
3.5. Performances
3.5.1. Performances du système
3.5.2. La qualité de l’image
3.5.3. Les algorithmes d’identification
3.6. Amélioration des performances de l’algorithme
3.7. Présentation de l’application
3.7.1. Tests et résultats
3.7.2. Avantages et inconvénients
3.8. Comparaisons avec un autre système biométrique tel que l’iris
3.8.1. Avantages du système biométrique basé sur l’iris
3.8.2. Inconvénients du système biométrique basé sur l’iris
3.9. Les raisons pour choisir le visage
3.10. Nouvelles technologies améliorant la reconnaissance faciale
3.10.1. L’utilisation de la technologie infrarouge
3.10.2. L’utilisation de la technologie 3D
3.11. Conclusion
CONCLUSION
ANNEXE 1 LE LANGAGE JAVA
ANNEXE 2 EXTRAIT DE CODE
BIBLIOGRAPHIE
FICHE DE RENSEIGNEMENTS
![]()