Détermination de propriétés de flot de données pour
améliorer les estimations de temps d’exécution pire-cas
Analyse statique pour le WCET
L’analyse statique consiste à obtenir des propriétés d’un programme sans l’exécuter. Elle nécessite de modéliser sa structure ainsi que le système sur lequel il est exécuté.
Représentation structurelle d’un programme
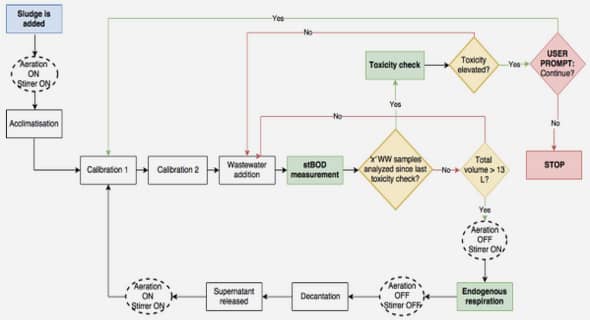
En analyse statique, un programme est communément représenté sous la forme d’un graphe, appelé le Graphe de Flot de Contrôle ou Control Flow Graph (CFG) [5], illustré sur la Figure 2.3. Le CFG est une abstraction, et une surapproximation dans le sens où il représente un surensemble des chemins d’exécution réellement possibles dans le programme. Les conséquences de cette propriété des CFG sur l’évaluation du WCET sont développées dans la section 2.4 et seront un point central de cette thèse. Nous définissons d’abord la notion de bloc de base. Définition 2.1. Un bloc de base (parfois abrégé BB) est une séquence maximale d’instructions issue du programme respectant les deux conditions suivantes : (i) Un branchement (saut d’instruction) ne peut se faire qu’à partir de la dernière instruction (pas de branchement sortant de l’intérieur d’un bloc) ; (ii) Le programme ne peut entrer dans un bloc de base que par la première instruction (pas de branchement entrant à intérieur d’un bloc). Les blocs de base sont ainsi des parties de code composées d’instructions s’exécutant toujours séquentiellement. Le programme est découpé en blocs de base de manière à avoir aussi peu de blocs que possible. Nous pouvons maintenant définir un CFG. Définition 2.2. Le CFG d’un programme est un graphe orienté G = (V, E, , ω), où • L’ensemble des sommets V correspond à l’ensemble des blocs de base du programme ; • L’ensemble des arêtes E ⊆ V 2 correspond à l’ensemble des transitions possibles : ∀v1, v2 ∈ V, (v1 → v2) ∈ E si et seulement s’il existe un chemin d’exécution qui passe dans v2 immédiatement après v1. • et ω sont des blocs de base (virtuels, vides d’instructions) correspondant respectivement à l’entrée et à la sortie du programme. Dans le cas où le programme a plusieurs points d’entrée ou de sortie possibles, ces sommets sont reliés à chacun de ces points. Il est généralement admis qu’un CFG ne comporte qu’une seule composante connexe (c’est-à-dire que tous ses nœuds sont atteignables). Remarque. Lorsqu’un bloc se termine par un branchement conditionnel, et est donc relié à plusieurs arcs sortants, l’arc qui correspond à une exécution séquentielle du programme est dit non pris (la condition du branchement est fausse). Les autres arcs, représentant le cas où le branchement a eu lieu, sont dits pris. Dans les CFG de code source, il n’y a pas d’instruction de branchement explicite. Par notation, l’arc où la condition est fausse est donc annoté par un inverseur : . Nous définissons enfin les notions de chemins et de chemins d’exécution : Définition 2.3. Un chemin dans un CFG G = (V, E, , ω) (ou plus généralement dans un graphe (V, E)) est une séquence d’arêtes e1.e2 . . . en ∈ E ? consécutives, c’est-à-dire telles que ∀i ∈ [1, n − 1], ∃v, v0 , v00 ∈ V, ei = v → v 0 ei+1 = v 0 → v 00 Un chemin d’exécution dans un CFG G = (V, E, , ω) est un chemin e1.e2 . . . en ∈ E ? tel qui commence par l’entrée de G et finit par sa sortie, c’est-à-dire tel que ∃v, v0 ∈ V, e1 = → v en = v 0 → ω Le temps d’exécution pire-cas d’un programme correspond nécessairement à un chemin d’exécution : c’est le Chemin d’Exécution Pire-Cas ou Worst-Case Execution Path (WCEP). La construction de CFG peut poser quelques difficultés, ou résulter en des formes difficiles à analyser, nous poussant à effectuer des transformations conservatives des chemins d’exécution. Ce sujet sera traité plus loin en section 3.1.2, en particulier à propos du problème des boucles irrégulières, des branchements dynamiques ou des schémas d’appels récursifs
Niveau de représentation du code
L’analyse d’un programme pose la question du choix du niveau de code analysé. Plus le code est de haut niveau, plus il est facile d’en extraire la sémantique du programme. Par exemple, il est plus aisé d’obtenir les bornes de boucle sur du code source que sur de l’assembleur ; la structure du programme y est plus évidente. Certaines opérations simples dans du code source (C, par exemple) comme la division par une constante ou des additions flottantes peuvent être traduites à la compilation en code assembleur très difficile à interpréter. Ces obscures transformations peuvent être motivées par un souci d’optimisation (calcul d’une division par une constante sans boucle, par exemple) ou une nécessité due à la pauvreté du jeu d’instructions (absence de calcul flottant natif sur ARM9, par exemple). Propager des informations de flot issues du code source vers le binaire peut se révéler complexe, en particulier en présence d’optimisations [62, 63]. Les effets de ces optimisations ne peuvent pas être ignorés car, si elles améliorent le cas moyen, elles peuvent parfois aussi dégrader le WCET. D’un autre côté, l’analyse sur le code binaire est potentiellement plus précise : elle travaille directement sur la forme du programme qui sera exécutée par le processeur, est capable d’exploiter toute optimisation du compilateur et peut tracer précisément l’exécution du programme dans le matériel. Certaines parties du code n’apparaissent même qu’à la compilation : c’est le cas, par exemple, des fonctions d’émulation. Le code binaire fait également apparaître les chemins issus de l’évaluation en circuit court des expressions logiques [2], comme sur la Figure 2.4 qui représente le CFG d’un programme compilé à partir du code C if(x && y) z = 1; else z = -1;. Cette figure illustre la décomposition de l’évaluation de l’expression logique x && y en deux tests et deux branchements conditionnels, faisant apparaître un chemin d’exécution invisible dans le code source. Les avantages de cette approche motivent le choix de développer l’intégralité des travaux de cette thèse sous la forme d’analyse sur le code binaire. Un inconvénient de ce choix est que l’analyse devient propre à un jeu d’instructions assembleur en particulier. Il est toutefois possible de contourner ce problème en raisonnant par l’intermédiaire une abstraction des jeux d’instructions, comme celle qui sera proposée dans la section 3.1.1.
1 Introduction |