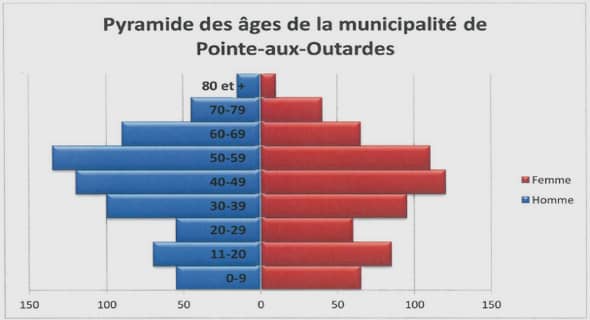
Apprentissage discriminant sur des graphes pour la caractérisation des paysages propices à l’étalement urbain
Méthodes de fouilles de motifs pour caractériser les graphes
La fouille de données consiste à chercher des caractéristiques fréquentes dans le jeu de données, ces caractéristiques pouvant être utilisées a posteriori pour discriminer les données. Si les données sont sous forme de graphes, on peut, par exemple, chercher les sous-graphes fréquents. Dans le domaine de la fouille de graphes, il existe quelques travaux qui se sont intéressés à la prise en compte d’une information spatiale. Apriori-based Graph Mining (AGM) [19] est une adaptation de l’algorithme Apriori pour la fouille de graphes. Apriori est un algorithme de fouille de données qui extrait des règles d’associations fréquentes. AGM permet d’extraire des sous-graphes fréquents et des règles d’associations entre ceuxci (par exemple, la présence d’un motif implique la présence d’un autre). Il s’est révélé efficace (relire l’article pour plus de précision) sur une étude de composés moléculaires. (reciter l’article ? ou ne le citer qu’à la fin de ce paragraphe ?) La géométrie étant une information de nature spatiale, on peut citer les travaux portant sur les graphes géométriques (les nœuds ont des coordonnées, donc des configurations géométriques sont présentes) tels que ceux de M. Kuramochi et G. Karypis [20], et H.Arimura, T. Uno et S. Shimozono [4]. 2 M. Kuramochi et G. Karypis ont développé un algorithme, gFSG, également inspiré d’Apriori qui recherche les sous-graphes géométriques fréquents, autorisant les transformations simples (translations, rotations, changements d’échelle) et en admettant une tolérance sur la mesure de similarité. Il peut être utilisé avec de très grandes bases de données de graphes représentant notamment des données spatiales. H.Arimura, T. Uno et S. Shimozono ont conçu un algorithme ne devant retenir que les sous-graphes géométriques de taille maximale, gFSG présentant pour eux le risque de trouver trop de sous-graphes. J. Huan et al. [18] ont une approche plus orientée théorie de l’information. Ils définissent une information mutuelle entre deux graphes qui leur permet d’introduire la notion de sous-graphe k-cohérent : tout sous-graphe de taille k dont l’information mutuelle avec le graphe d’origine est supérieur à un seuil strictement positif. Le but devient alors d’extraire tous les sous-graphes kcohérents. À l’aide de SVM (Support Vector Machines, cf. 2.2) pour classifier des familles de protéines, leur approche donne de bons résultats.
Méthodes à noyaux spécifiques aux graphes
Les SVM (Support Vector Machines, machines à vecteurs de support ou séparateurs à vastes marges) consistent à séparer des données (pourvues d’attributs numériques) en deux classes selon un hyperplan, en maximisant la distance de cet hyperplan aux exemples et en autorisant quelques erreurs. Souvent, les données ne sont pas linéairement séparables, donc on construit une fonction φ(.) qui projette les données dans un espace de dimension plus grande, appelé l’espace de redescription, dans lequel la séparation linéaire pourra avoir lieu. La recherche de l’hyperplan séparateur nécessite des calculs de produits scalaires. Or, dans l’espace de redescription, à cause de la plus grande dimension (potentiellement infinie), les calculs sont alourdis. Mais il existe des fonctions K(., .) bilinéaires symétriques semi-définies positives telles que leur application à deux éléments de l’espace d’origine valent le produit scalaire de leurs correspondants dans l’espace de redescription. K(., .) est une fonction noyau. Formellement : ∀x, y K(x, y) = hφ(x)|φ(y)i L’utilisation de noyaux permet donc de séparer des vecteurs dans l’espace de redescription sans avoir à les représenter explicitement dans cet espace. Une fonction noyau peut suffire pour séparer en deux classes des données, peu importe la représentation initiale des données, et en particulier si ces données sont des graphes. Pour des raisons d’efficacité du calcul des fonctions noyaux, les noyaux de graphes décrivent les graphes au travers de sous-structures présentes dans le graphe. La distance induite par le noyau entre deux graphes est donc une approximation. 3 K. M. Borgwardt et al. [8] exposent des noyaux adaptés aux graphes utilisant, par exemple, des marches aléatoires (suites aléatoires de sommets reliés par des arêtes). kgraph(G1, G2) = X walk1∈G1 X walk2∈G2 kwalk(walk1, walk2) où kwalk(walk1, walk2) vaut le produit des fonctions noyaux sur chaque couple de sommets. L’étude de K. M. Borgwardt et al. portait sur des protéines (sous forme de graphes) donc le noyau utilisé se trouve modifié en une combinaison de plusieurs noyaux portant sur les attributs spécifiques aux graphes (types d’arêtes, de nœuds). Un autre point de vue, valable surtout dès que les graphes deviennent grands, est d’étudier la distribution de “petits” motifs au sein des graphes. C’est l’idée des noyaux sur les graphlets (cite), sous-graphes de k sommets (k ∈ {3, 4, 5}). L’énumération de ces sousgraphes étant un problème complexe, N. Shervashidze et al. [28] procèdent à un échantillonnage des sous-graphes et appliquent dessus leur fonction noyau. Cette technique se révèle souvent efficace, mais ne tient pas compte d’éventuelles spécificités spatiales des données (pas d’intervention dans les calculs d’étiquettes sur les arêtes) et les résultats produits pour séparer les classes ne sont pas interprétables.
Arbres de décision
Les arbres de décision sont des classifieurs discriminants facilement interprétables par l’être humain : le principe est de faire suivre une série de tests, hiérarchiquement ordonnés par un arbre, à l’objet considéré en empruntant le chemin (partant de la racine) correspondant aux résultats de ces tests pour finalement arriver à une feuille qui donne sa classe (ici, un test correspond à la présence d’un sous-graphe). L’apprentissage d’arbre de décision consiste à diviser récursivement, et le plus efficacement possible, les exemples de l’ensemble d’apprentissage par des tests jusqu’à n’avoir plus que des sous-ensembles d’exemples tous (ou presque) de la même classe. Dans toutes les méthodes, trois opérateurs sont majeurs : – décider si un nœud est terminal (i.e. s’il peut être étiqueté comme une feuille de l’arbre). – si un nœud n’est pas terminal, lui associer un test – si un nœud est terminal, lui associer une classe La sélection du test associé à un nœud est une étape essentielle. Dans le cas général des données structurées sous forme de liste d’attributs, cela correspond à trouver un attribut de partage. On utilise alors une fonction d’évaluation qui favorise les attributs discriminants. Cette fonction mesure le gain 4 Figure 2 – Exemple d’arbre de décision classique déterminant le type de fleur en fonction des dimensions d’un pétale en information des attributs en utilisant en général des critères statistiques comme l’entropie. GBI (Graph-Based Induction) est une technique d’apprentissage efficace qui extrait des motifs (sous-graphes) fréquents sur des graphes de manière gloutonne. Il est possible de construire en suivant cette approche des arbres de décision pour graphes ([14], [25]). GBI et ses améliorations (B-GBI 1 , Cl-GBI 2 ) servent à trouver, de manière itérative, des motifs fréquents dans des graphes dont les nœuds sont étiquetés. Cl-GBI permet que ces motifs fréquents puissent se recouvrir. Notons que Cl-GBI est aussi bien adapté aux graphes orientés que non orientés, et certaines relations spatiales, comme l’adjacence, ne sont pas orientées, alors que d’autres, comme l’inclusion, le sont. Un arbre de décision discriminant selon les motifs présents dans les graphes se construit récursivement en utilisant ce principe. On calcule par Cl-GBI les motifs fréquents des graphes à disposition, on détermine quel motif est le plus discriminant, on sépare l’ensemble de graphes en deux selon que ce motif est présent ou non, on calcule récursivement l’arbre associé à chacune de ces parties, on obtient les sous-arbres correspondant aux fils du nœud courant (motif présent/absent). La recherche de motifs est une boucle sur ces trois étapes pour Ne itérations (paramètre à fixer selon le temps de calcul, la taille des motifs acceptés. . .) : 1. Extraire toutes les paires de nœuds reliés pas une arête dans les graphes en comptant les occurrences. À partir de la deuxième itération, au 1. Beam-wise Graph-Based Induction 2. Chunkingless Graph-Based Induction 5 moins l’un des nœuds de ces paires doit être un nouveau pseudo nœud créé au point 2 de l’itération précédente. 2. Considérer les b paires les plus fréquentes parmi celles qui viennent d’être extraites et, à partir de la deuxième itération, des paires extraites aux itérations précédentes mais non sélectionnées à cette étape. Enregistrer le motif correspondant comme un nouveau pseudo nœud. 3. Donner une étiquette à chaque nouveau pseudo nœud. Figure 3 – Arbre de décision sur des motifs fréquents [25] Pour utiliser cet arbre de décision sur un nouveau graphe, pour chaque motif successif rencontré sur l’arbre, on procède comme suit : on utilise une version modifiée du processus de recherche (on se restreint aux sous-motifs du motif discriminant) sur le graphe pour vérifier s’il contient ou non le motif, avec des paramètre b et Ne suffisamment élevés pour avoir peu de chance de manquer quelque chose. Dans le cas de graphes géographiques, où les nœuds sont étiquetés selon ce qu’ils représentent, et où les arêtes sont également potentiellement étiquetées selon la signification de la liaison, Cl-GBI peut être utilisé avec les avantages et les inconvénients qui vont avec le fait que ce soit un algorithme glouton et que le temps de calcul est paramétrable.
Programmation Logique Inductive
La PLI [24] est une technique d’apprentissage supervisé qui permet d’induire des hypothèses, ou règles, à partir d’exemples. Ces exemples sont étiquetés positifs ou négatifs selon qu’ils représentent ou non des observations du concept à inférer. La PLI permet en particulier de dépasser certaines limites des formalismes de représentation des connaissances dans les systèmes d’apprentissage en utilisant la logique du premier ordre. Cette modélisation permet de rendre compte plus naturellement des relations entre objets. La PLI met en œuvre l’induction en logique des prédicats qui est utilisée comme langage de représentation des exemples (faits Prolog) et des hypothèses (clauses de Horn). L’inférence de nouvelles règles correspond à une 6 recherche de clauses dans un espace organisé selon une relation de généralité. Les algorithmes de recherche descendante, comme Foil, partent d’une clause générale vers des clauses plus spécifiques en utilisant des opérations comme l’ajout de littéraux à la clause de départ ou l’application de substitution pour transformer des variables en constantes ou pour unifier plusieurs variables. Les clauses ainsi générées sont ensuite testées sur les exemples de façon à généraliser le maximum d’exemples positifs et peu ou pas d’exemples négatifs. En PLI, la taille de l’espace de recherche rend nécessaire l’utilisation d’heuristiques afin de guider le parcours de l’espace au cours de la recherche. Un type d’heuristique très utilisé concerne les fonctions d’évaluation, qui mesure en quelque sorte l’utilité de chaque clause examinée. L’utilité d’une hypothèse peut s’exprimer par la quantité d’information apportée, par la compression de la base de connaissance réalisée ou par son pouvoir de discrimination comme l’heuristique Gain de Foil (First-Order Inductive Learner) .
1 Problématique |