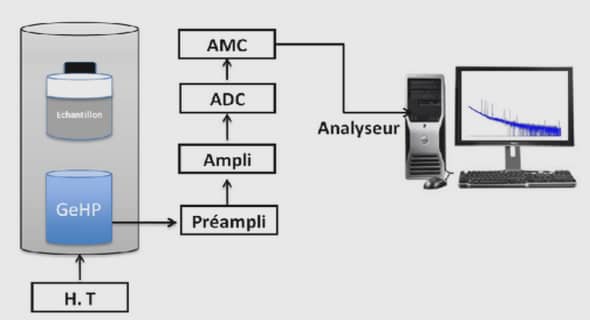
Sélection d’attributs pour le data mining basée
sur l’algorithme RFE-SVM
Etude et compréhension des Réseaux Pair à Pair
Les réseaux Pair à Pair (P2P) sont de nos jours devenus un véritable phénomène d’actualité et sont utilisés par des millions de personnes et de grandes entreprises. Cependant peu de personnes sont familières avec l’environnement du P2P. Par définition un réseau P2P est un système distribué sans aucune organisation hiérarchique ni contrôle centralisé. Pour bien comprendre le Peer To Peer, il faut avant tout comprendre le fonctionnement du réseau client/serveur. Dans un réseau client/serveur, les clients désignent des applications qui sont installées sur une machine pour exploiter les services offerts par le serveur qui est représenté par des machines puissantes. Cependant ce type de réseau présente des limites à savoir une file d’attente très longue et un disfonctionnement du réseau en cas de panne du serveur. Pour faire face à ces problèmes les réseaux P2P ont été crées. A l’inverse du réseau Client/serveur, dans un environnement P2P, le client est aussi serveur à quelques exceptions près (voir la section 1). Concrètement, à travers une architecture P2P, chaque utilisateur peut partager et gérer des ressources comme il l’entend c’est à dire définir des autorisations sur les fichiers et répertoires, élaborer des structures d’accès à l’information, gérer des ressources machines etc. L’’information et la charge sont réparties sur différentes machines. Cependant les systèmes P2P présentent une certaine différence de part leurs fonctionnalités. Pour mieux comprendre le fonctionnement du Peer to Peer nous allons étudier trois différentes classes de réseaux P2P : les réseaux structurés, les réseaux non structurés et les réseaux hybrides. Chapitre1 : Etude et compréhension des systèmes Pair a Pair 5 Aissatou D. GASSAMA – DEA Informatique FST-UCAD I. Réseaux structurés Les réseaux P2P structurés reposent sur le principe de stockage et de nommage partagé avec l’utilisation d’une Table de Hachage Distribuée (DHT) par certains d’entre eux. Une DHT est représentée par la technologie suivante : tous les pairs prennent en charge une partie de l’activité serveur. Chaque pair maintient une petite table de routage composée de NodeIDs (Identifiant d’un nœud) et d’adresses IP de ses pairs voisins. Un routage des messages permet de transmettre chaque requête au pair capable d’y apporter une réponse. Prenons deux exemples d’illustration : Chord et Kademlia. I.1 Chord : Chord [1][3] est un système décentralisé qui utilise une fonction de hachage pour affecter des identifiants aux pairs et aux fichiers (données). SHA-1 est utilisé comme fonction de hachage pour affecter un identifiant unique de m-bits pour chaque pair et un identifiant unique aux clés. L’identifiant d’un pair est choisi en hachant l’adresse IP du pair, alors qu’un identifiant d’un fichier est obtenu en hachant son nom. Les nœuds sont répartis sur un anneau d’identifiant modulo 2m , et les fichiers sont répartis sur ces différents nœuds. L’identifiant K d’un fichier est attribuée au premier pair dont l’identifiant est égal à ou suit K dans l’espace d’identifiants des nœuds. Sur la figure 1.8, nous proposons une illustration du fonctionnement de Chord. L’anneau Chord est composé de dix pairs et stocke cinq données. Le pair d’identifiant tout juste supérieur ou égal à l’identifiant 10 est le pair 14, donc la donnée d’identifiant 10 sera attribuée au NodeID 14. Notons que si un nouveau pair d’identifiant 26, par exemple, joint le réseau, la donnée d’identifiant 24 qui est stocké au niveau du pair 32 sera déplacée vers le nouveau venu qui a l’identifiant le plus proche. Chapitre1 : Etude et compréhension des systèmes Pair a Pair 6 Aissatou D. GASSAMA – DEA Informatique FST-UCAD Figure 1.8 : Architecture de Chord Figure 1.9 : Recherche améliorée La recherche d’une donnée dans Chord : On distingue deux types de recherche : la recherche naïve et la recherche améliorée. 1. La recherche naïve: (voir figure 1.8) Soit i le nœud qui reçoit la requête : recherche(k) Chapitre1 : Etude et compréhension des systèmes Pair a Pair 7 Aissatou D. GASSAMA – DEA Informatique FST-UCAD • Si i possède k, il retourne k • Sinon, il propage la requête à son successeur (pour cela chaque nœud doit stocker l’identifiant de son successeur). Ainsi de suite jusqu’à ce qu’on arrive au nœud d’identifiant suivant k. • Le résultat suit le chemin dans l’ordre inverse . Recherche linéaire en nombre de nœuds. 2. La recherche améliorée : (voir la figure 1.9) Il faut une table de routage pour ce type de recherche. Soit m le nombre de bits de l’espace Identifiant/NodeID, chaque nœud N maintient une table de routage avec un maximum de m entrées, appelée table d’index (finger table). La ieme entrée dans la table sur le pair N contient l’identité du premier nœud S qui suit N par au moins 2i-1 sur le cercle d’identifiant, c’est-à-dire S = successeur (N+2i-1), où 1 ≤ i ≤ m. Le pair S est le ieme index du pair N (n.indexe [i]). Une entrée de la table d’indexe comprend à la fois l’identifiant Chord et l’adresse IP (et le numéro de port) du pair. Sur la Figure 1.9 nous avons la table d’indexe du pair 8, et la première entrée d’indexe pour ce pair pointe sur le pair 14, car celui-ci est le premier pair qui succède à (8 +20 ) modulo 26 = 9. De même, le dernier index du pair 8 pointe sur le pair 42, c’est-à-dire le premier pair qui succède à (8+25 ) modulo 26 = 40. De cette façon, les pairs stockent l’information sur seulement un petit nombre de pairs, et connaissent seulement les pairs qui leur sont proches Aussi, une table d’indexe d’un pair ne contient pas d’informations suffisantes pour déterminer directement le propriétaire d’une donnée d’identifiant k arbitraire. Par exemple, le pair 8 ne peut pas déterminer le successeur de l’identifiant 34 lui-même, Le pair 38 en tant que successeur de cette clé n’est pas présent dans la table d’index du pair 8. Chapitre1 : Etude et compréhension des systèmes Pair a Pair 8 Aissatou D. GASSAMA – DEA Informatique FST-UCAD Algorithme de recherche améliorée o Rechercher localement si la clé existe. o Si oui envoyer la valeur associée. o Sinon rechercher le nœud avec l’identifiant le plus grand inférieur ou égal à la clé recherchée dans la table de routage. o Ensuite transmettre la requête au nœud trouvé qui a un identifiant égal ou qui suit 40 dans l’exemple de la figure 1.9. Le nombre de saut moyen est de (Log2 (N)). Ajout d’un nœud (voir figure 1.10) Lorsqu’un pair joint le système, les pointeurs successeur de certains pairs doivent être changés. Soit m, un nouveau nœud voulant joindre le réseau o m doit contacter un nœud existant k o Il lui demande de rechercher l’adresse IP de son successeur x o k contacte le nœud trouvé x, puis lui demande quel est son prédécesseur, et demande au successeur de x et au prédécesseur de x de l’insérer entre eux sur le cercle. En fin il lui transmet les clés de l’intervalle] pred(x), x]. Il est important que ces pointeurs soient mise à jour à tout moment parce que l’exactitude des recherches n’est pas garantie autrement. Le protocole Chord utilise un protocole de stabilisation s’exécutant périodiquement en arrière-plan pour mettre à jour les pointeurs successeurs et les entrées dans la table d’indexe. L’exactitude du protocole Chord repose sur le fait que chaque pair connait ses successeurs. Lorsque des pairs tombent en panne, il est possible qu’un pair ne connaisse pas son nouveau successeur. Pour éviter cette situation, les pairs maintiennent une liste de successeurs de taille r, qui contient les premiers r successeurs d’un pair. Lorsque le pair successeur ne répond pas, le pair contacte simplement le prochain pair sur sa liste successeur. Chapitre1 : Etude et compréhension des systèmes Pair a Pair 9 Aissatou D. GASSAMA – DEA Informatique FST-UCAD Figure 1.10 : Ajout d’un nœud I.2 Kademlia : Kademlia[2][20] est un protocole P2P qui se base sur une table de hachage distribuée. Les nœuds du réseau Kademlia communiquent entre eux via le protocole UDP (User Datagram Protocol). Chacun de ces nœuds est affilié à un identifiant unique, codé sur 160 bits, appelé nodeID. Ces identifiants sont utilisés par Kademlia pour rechercher des informations indexées. Ces informations (généralement des mots clefs) sont appelées value. Chaque value est associée à un identifiant unique (codé aussi sur 160 bits) appelé key. Le principe d’indexation des informations est relativement simple : chaque nœud est responsable d’une liste d’informations, une liste de couple < key, value >, de telle sorte que les identifiants key soient proche de leur nodeID. Ainsi, la distance d entre deux identifiants x et y est définie par la fonction XOR (ou exclusif) entre ces derniers : d(x, y) = x y. Kademlia peut envoyer une requête à tous les pairs dans un intervalle de temps donné ou envoyer des requêtes asynchrones parallèles. Il utilise un seul algorithme de routage tout au long du processus pour localiser les pairs près d’un ID particulier. Chaque message transmis par un pair inclut son Identifiant, permettant au destinataire d’enregistrer les expéditeurs existants. Les clés des données sont également des identificateurs de 160 bits. Pour localiser les paires {clé, value}, Kademlia repose sur la notion de distance Chapitre1 : Etude et compréhension des systèmes Pair a Pair 10 Aissatou D. GASSAMA – DEA Informatique FST-UCAD entre deux identifiants. Le protocole de routage Kademlia est composé des commandes suivantes:
Introduction |