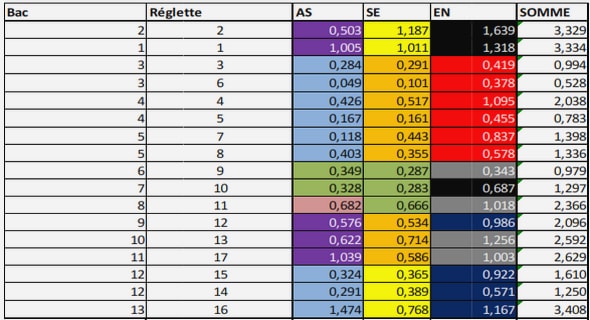
Quel est le point commun entre un nouveau compilateur d’un langage de programmation académique tel que Nit [83], une approche d’observation de modèles sociaux-environnementaux [86] et la reconstruction de génomes par scaffolding en bioinformatique [24] ? À première vue, il n’existe aucune similitude entre ces travaux issus de trois domaines très différents. Cependant, lorsque nous nous intéressons aux protocoles expérimentaux de validation et plus précisément aux données qu’ils utilisent, nous nous apercevons que les trois travaux possèdent au moins deux points communs : leurs données se modélisent sous forme d’un modèle logiciel à haut niveau d’abstraction, aussi appelé méta-modèle et les trois approches souffrent d’un manque sévère de données de tests ; elles sont rares ou indisponibles, ou bien elles sont coûteuses à obtenir et nécessitent respectivement, des programmeurs en grand nombre, des observations sur le terrain dans les forêts de Madagascar et du séquençage d’ADN basé sur une réaction en chaîne par polymérase. Comme les exemples précédents l’illustrent, la problématique de disposer de données structurées en grande quantité est primordiale pour beaucoup de domaines. De manière plus spécifique en génie logiciel, on s’intéresse à cette problématique pour répondre à deux questions majeures : comment savoir si les modèles logiciels conçus capturent bien le domaine qu’ils prétendent modéliser d’une part, et quelles données utiliser pour tester les programmes qui manipulent ces mêmes modèles d’autre part. La difficulté réside dans la structure complexe et la syntaxe propre des modèles ce qui rend ardue la tâche de les écrire à la main, notamment, lorsqu’une grande quantité et des tailles importantes de ces modèles sont nécessaires à une utilisation donnée. La solution présentée dans cette thèse est la génération automatique de ces données, que nous allons, par la suite, désigner par “modèle” ou “instance”. Les données générées sont spécifiées par un modèle abstrait qui est nommé “méta-modèle”. Nous proposons donc d’instancier les méta-modèles pour générer automatiquement des modèles qui respectent les spécifications des méta modèles. Les modèles générés automatiquement seront ensuite utilisés pour répondre à deux objectifs principaux :
1. Aider les experts d’un domaine à valider ou corriger les spécifications de leurs métamodèles à travers des modèles ou des instances générés dont certaines caractéristiques se rapprochent des modèles réels.
2. Tester les programmes qui transforment ces modèles avec des données de tailles, de structures et de caractéristiques diverses et variées.
Ces deux objectifs principaux de la génération automatique de modèles poussent à se poser une question d’une grande importance pour la suite : comment valider une approche de génération de modèles, c’est-à-dire, quels sont les critères de qualité qui permettront de répondre aux deux objectifs précédents ? Nous retenons cinq critères qu’un processus de génération doit assurer :
CONTRIBUTIONS ET RÉALISATIONS
— Validité. Les modèles doivent respecter toutes les spécifications de leur méta modèle et toutes les contraintes qui l’accompagnent. Le langage qui nous servira à écrire ces contraintes est OCL (Object Constraint Language).
— Passage à l’échelle. L’approche doit être capable de générer des instances de grandes tailles pour des méta-modèles de grandes tailles également, dans le but de tester le passage à l’échelle des programmes manipulant ces instances.
— Vraisemblance. Les modèles doivent posséder des caractéristiques aussi proches que possible des instances réelles. Cela permettra à un expert de les utiliser pour valider son méta-modèle.
— Diversité. Les instances générées doivent offrir une large diversité et couvrir de la meilleure manière possible l’espace des solutions.
— Automatisation. Le processus doit être automatique pour être accessible à des experts de domaines aussi variés que ceux cités plus haut. Plusieurs approches de génération de modèles existent [13, 15, 19, 31, 74, 94, 106]. Divers paradigmes informatiques sont utilisés pour répondre à cette problématique. Cependant, l’étude de ces approches a montré qu’aucune d’entre elles ne répond aux cinq critères en même temps. Dans cette thèse, nous proposons une nouvelle approche de génération de modèles qui se conforme à tous les critères de qualité d’un processus de génération de modèles en même temps.
L’approche que nous proposons génère des modèles en se basant sur la programmation par contraintes (CSP). Les éléments d’un méta-modèle donné et ses contraintes sont modélisés en CSP. La résolution de ce dernier par un solveur de contraintes permet de calculer des instances valides. Les contributions principales de la thèse sont :
— Une modélisation efficace d’un méta-modèle en CSP qui offre un bon passage à l’échelle. Une formalisation d’une partie des constructions du langage de contraintes OCL en CSP assure la validité des modèles générés. Ces modélisations en CSP prennent soin d’utiliser au mieux les outils qu’offre la programmation par contraintes (telles les contraintes globales) et de les appliquer efficacement au génie logiciel.
— Une technique pour améliorer le réalisme, la pertinence et la vraisemblance des instances générées. Nous utilisons des métriques spécifiques à un domaine dans le but d’inférer des lois de probabilités usuelles. La simulation de ces dernières et leur intégration au CSP améliorent sensiblement la vraisemblance des solutions.
— Des métriques de distances qui mesurent la similarité entre les modèles deux à deux. Nous avons étudié puis adapté aux modèles logiciels des distances mathématiques ou de graphes. Des techniques de clustering sont ensuite utilisées pour sélectionner les modèles les plus éloignés parmi un ensemble de modèles donné ou généré. Enfin, l’algorithmique génétique permet d’améliorer la diversité de l’ensemble de modèles.
— Un outil de génération de modèles, nommé Grimm, regroupe toutes ces contributions.
Ingénierie Dirigée par les Modèles
Dans la section qui va suivre l’utilisation du terme modèle est omniprésente. Il s’agit du thème central de tout ce qui va être dit. Le modèle sera défini à la section 2.1.2.1. Néanmoins, pour une meilleure compréhension de cette section, nous donnons une brève définition de ce terme. Ainsi, parmi la dizaine de définitions du mot modèle dans le dictionnaire de la langue française, la plus proche de l’idée qu’on se fait du modèle en génie logiciel est : Objet type à partir duquel on reproduit des objets de même sorte à de multiples exemplaires. Quand on consulte le dictionnaire de la langue anglaise, deux définitions retiennent notre attention : A three-dimensional representation of a person or thing or of a proposed structure, typically on a smaller scale than the original. A simplified description, especially a mathematical one, of a system or process, to assist calculations and predictions. La notion de modèle en génie logiciel regroupe toutes ces caractéristiques à la fois. D’abord, il simplifie la reproduction de systèmes à de multiples exemplaires. Ensuite, il est de plus petite taille que le système qu’il décrit, pour qu’il soit plus simple de manipuler le modèle que directement le système lui-même. Enfin, il aide à effectuer des traitements sur le système sans prendre le risque d’altérer l’intégrité de ce dernier.
Historique de la modélisation en informatique
L’augmentation rapide de la taille et de la complexité des logiciels a poussé les informaticiens à la recherche d’outils et langages pour représenter de manière abstraite certains de leurs aspects. Cette représentation a pour but de faciliter la conception, la réalisation et la manipulation de ces systèmes. Depuis les tous premiers qui sont apparus dans années 1960, une multitude de langages de modélisation a été adoptée. Certains de ces langages ne sont plus d’actualité ou alors ont fusionné pour en créer de nouveaux, quant à d’autres, ils sont toujours très utilisés.
Réseaux de Petri
Les réseaux de Petri ont été inventés par Carl Adam Petri [26],[79]. Un réseau de Petri est un outil mathématique utilisé pour la modélisation de systèmes à processus concurrents. Il est représenté par un graphe biparti contenant deux types de noeuds: les places et les transitions. Une place est marquée par un nombre entier (nombre de jetons). Il s’exécute par le franchissement des transitions. Après chaque étape d’exécution, des jetons d’une place sont déplacés dans une place située une transition plus loin.
SADT
SADT (Structured Analysis and Design Technique) est une méthode de conception et de description des systèmes complexes par analyse fonctionnelle descendante. Elle a été développée aux État-Unis par Douglas T. Ross à partir de 1969 [88]. Dans une conception SADT, un système est décomposé en sous-taches de plus en plus spécifiques (Analyse fonctionnelle descendante). Une boite SADT décrit une tâche donnée et possède des entrées (gauche), des sorties (droite), des mécanismes de réalisations (bas) et des flux de contrôles (haut).
1 Introduction |