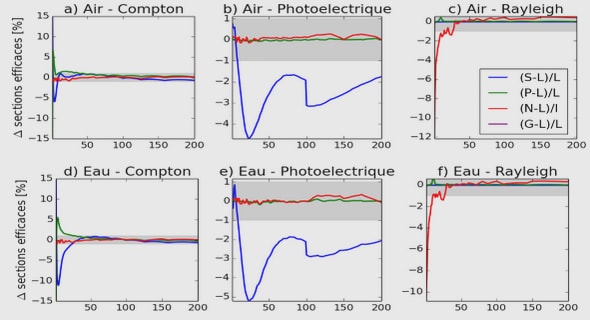
Une radio numérique
Applications de l’indexation audio pour la radio
On peut ainsi lister nombre d’applications qui profiteraient directement à un média radio comme RTL :
- Reconnaissance des titres musicaux : l’identification des titres musicaux est un atout essentiel pour une radio puisqu’elle permet de maintenir l’auditeur informé de ce qu’il écoute en lui fournissant les informations de titre, artiste et album, en plus de fournir la pige 3 nécessaire pour les organismes de contrôle de droits d’auteur (SACEM …). On fait généralement appel pour cela à des techniques d’identification audio qui se concentrent sur la construction d’une empreinte compacte pour chaque titre musical et sa recherche parmi une très vaste collection d’empreintes indexées.
- Recherche de la voix chantée dans un titre musical : il n’est pas rare que le présentateur d’une émission musicale ou de variété parle sur le début d’une chanson, grapillant ainsi quelques précieuses secondes de parole sur une introduction trop longue, ou assurant simplement la transition entre deux titres. Les présentateurs s’interrompent par convention lorsque l’artiste commence à chanter. À cette fin, il est actuellement nécessaire d’annoter manuellement les chansons afin de permettre au présentateur de savoir précisemment jusqu’à quand il peut parler ou à partir de quand, sur la fin d’une chanson. La détection automatique de voix chantée dans une chanson permettrait ainsi d’automatiser ce processus.
- Reconnaissance et suivi de locuteurs : la reconnaissance de locuteurs permet de fournir à l’auditeur des informations (biographie…) sur le journaliste ou la personne interviewée. Le suivi de locuteur permet de plus d’indiquer en temps réel qui a la parole. L’application d’une telle technique sur les archives permettrait en outre une recherche par locuteur, ce qui se révèlerait un outil très utile pour le travail des journalistes ou pour la constitution des meilleurs moments de certaines émissions (par exemple les fameuses « Grosses têtes »).
- Transcription de la parole : les bulletins d’informations sont généralement fournis aux journalistes à l’antenne sous forme écrite. Le texte est par la suite corrigé manuellement afin de prendre en compte les modifications éventuelles apportées par le présentateur en direct. La transcription automatique permettrait de simplifier ce processus et de le généraliser à l’ensemble des programmes d’antenne. La forme textuelle représente un avantage énorme sur l’archive audio puisqu’elle permet l’application des outils de recherche textuelle beaucoup plus puissants et moins gourmands que l’indexation audio.
- Détection de rires, d’applaudissements ou de foule : les rires et les applaudissements du public ou des invités peuvent être interprétés comme des indices de moments forts de certaines émissions. De même, lors d’une retransmission sportive, la clameur de la foule est généralement révélatrice d’un événement clé du match. La détection de ce type d’événement peut ainsi aider à la constitution du résumé ou des meilleurs moments d’une émission.
- Recherche de sons-clés (jingles…) : la recherche de sons-clés caractéristiques et récurrents, comme les jingles, les habillages sonores ou les publicités, permet de structurer les archives et ainsi de faciliter son exploration. On remarque que les quatre premières applications énumérées se basent sur une hypothèse forte sur le contenu acoustique analysé. Ainsi les deux premières concernent des plages de musique tandis que les deux suivantes ne s’appliquent que sur des extraits de voix parlée. Le premier outil indispensable à RTL pour l’implémentation de ces traitements plus complexes consiste donc en l’annotation automatique des plages de parole et de musique dans un flux audio. De plus, une fois la musique détectée, la détection de voix chantée constitue une application dont le principe est très similaire. En effet, chacune de ces tâches implique la reconnaissance d’une catégorie acoustique identifiable sans ambiguïté par un être humain. Les tâches de recherche de sons-clés et de reconnaissance de titre se basent par contre sur un formalisme différent et dépassent le cadre de cette thèse. De même la reconnaissance de locuteur et la transcription automatique sont des sujets de recherche à part entière qui impliquent, l’un la connaissance d’une vaste collection de locuteurs dont la multiplicité a un impact radical sur l’approche suivie, l’autre des notions sur le langage et la sémantique qui dépassent largement le cadre purement audio de cette étude. Le problème de la classification audio, et particulièrement la classification parole/musique et la détection de chant, constituent donc les sujets couverts par cette thèse, et présentés dans ce document.
« Qu’est-ce que la musique ? »
Alors que j’expliquais, durant une école d’été, mes travaux de jeune doctorant sur la classification parole/musique à un chercheur expérimenté, celui-ci me posa avec amusement la question suivante, qui me laissa sans réponse : « Mais qu’est-ce que la musique ? » En effet définir la musique de manière formelle est problématique. Même si l’on dépasse les querelles sur la musicalité de tel ou tel genre (un éternel débat entre générations), on conviendra que celleci est généralement le produit d’un consensus culturel basé sur de nombreuses notions cognitives complexes difficilement formalisables. On trouve les définitions suivantes, respectivement dans le Dictionnaire de l’Académie Française et le Robert : Art de composer une mélodie selon une harmonie et un rythme ; théorie, science des sons considérés sous le rapport de la mélodie, de l’harmonie, du rythme. Art de combiner des sons d’après des règles (variables selon les lieux et les époques), d’organiser une durée avec des éléments sonores ; productions de cet art (sons ou œuvres). On remarque que dans les deux cas, la musique est caractérisée par son mode de production, à savoir l’acte de composition, qui consiste en un agencement de sons dans le temps. On trouvera pour la parole des définitions qui renvoient au mode de production, ou qui sont même cycliques (« Élément(s) de langage parlé » dans le Robert), liant inévitablement le phénomène sonore à sa source. Travaillant sur la reconnaissance de ces sources dans un signal audio, je revenais parfois sur cette question, me disant que ne pas y apporter une piste de réponse constituait une lacune. Pourtant j’ai trouvé dans mon incapacité à apporter une réponse formelle la justification de la démarche scientifique employée. Si toute personne est en effet capable d’identifier un son de production musicale ou vocale, c’est bien parce que cette action, comme la plupart des processus cognitifs, échappe à la nécessité d’une définition formelle et repose en réalité sur l’apprentissage empirique de très nombreux exemples associés à une ou plusieurs catégories, qui nous permet de reconnaître celles-ci en présence d’exemples inconnus. Le cerveau est fondamentalement une machine associative, avant d’être une machine logique. L’apprentissage statistique, qui constitue l’outil prédominant dans le domaine de l’indexation audio, repose précisément sur ce principe, et revient à poser la question plus empirique : « Est-ce de la musique ? » Cette dernière constitue un problème fondamentalement différent, reposant sur la classification. On peut retrouver dans les deux questions posées la dualité classique entre approches « top-down » et « bottom-up » 4 , la première partant d’une définition englobant tous les exemples d’une catégorie et permettant de les reconnaître, la seconde construisant la définition de la catégorie à partir d’une collection d’exemples représentatifs. Ce que nous appelons « classification audio » consiste en l’application de ce principe de catégorisation d’exemples parmi un ensemble prédéfini de classes, sur un signal audio.
Classification par Machines à Vecteurs de Support
Le domaine de l’apprentissage statistique est aujourd’hui riche et l’expérimentateur dispose de nombreuses méthodes de classification, généralement formalisées par les statisticiens. Parmi celles-ci, les Machines à Vecteurs de Support (SVM, Support Vector Machines) sont une approche récente (datant de la décennie passée) qui modernise le cadre classique de la séparation linéaire en introduisant une non-linéarité dans la surface de décision. La régularité de cette surface de décision est contrôlée par un principe de Minimisation du Risque Structurel qui garantit les bonnes propriétés de généralisation du classifieur. Les excellentes propriétés des SVM nous ont conduit à restreindre notre étude de la classification audio à cette méthode. Une étude préliminaire de l’état de l’art dans le domaine de la classification audio, au chapitre 2, suivie d’une présentation détaillée de la théorie des SVM, dans la partie I, nous permettrons d’étayer notre propos et de justifier ce choix. L’introduction des SVM dans le domaine de la classification audio est relativement récent (le premier article que nous avons trouvé ne remonte qu’à 2001), et on compte aujourd’hui encore relativement peu d’articles tirant parti de cette méthode pour la tâche en question, par rapport aux autres méthodes plus connues de la communauté. De plus, les SVM restent souvent exploités comme une « boîte noire » de classification que l’expérimentateur n’exploite pas toujours de manière optimale, en partie en raison des nombreuses toolbox publiques lui apportant une interface simple pour employer cette technique sans avoir a en maîtriser les détails théoriques. Nous verrons que le point central dans la mise en place d’une machine à vecteurs de support est le choix d’une fonction noyau, qui réalise implicitement une transformation sur les données, qui les place dans un espace de dimension supérieure, où la séparation linéaire classique est appliquée. Afin de maximiser la séparabilité des données dans l’espace transformé, la transformation doit donc être directement déterminée par la structure des données dans l’espace d’origine. Un soin particulier doit ainsi être porté à la fois sur le choix de cette transformation et sur la caractérisation des données audio, qui détermine leur répartition dans l’espace d’origine. Les contraintes propres aux machines à vecteurs de support déterminent donc un certain nombre de problématiques qui constitueront les axes de recherches de cette étude.