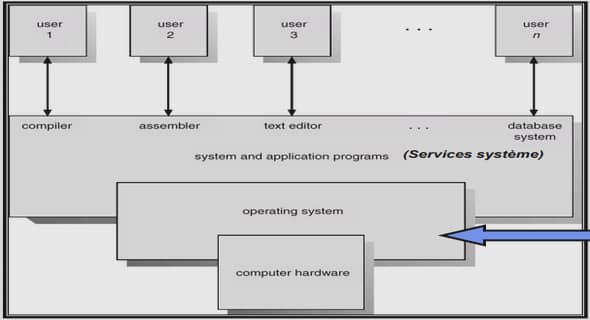
Systèmes embarqués par rapport aux systèmes à usage général
Un système embarqué est habituellement classé comme un système qui a un ensemble de fonctions prédéfinies et spécifiques à exécuter et dans lequel les ressources sont contraintes. Prenons par exemple, une montre-bracelet numérique. Il s’agit d’un système embarqué qui a plusieurs fonctions apparentées: indication du temps, peut-être plusieurs fonctions de chronomètre, et une alarme. Il a également plusieurs contraintes de ressources. Le processeur qui fait fonctionner la montre ne peut pas être très grand, sinon personne ne la porterait. La consommation d’énergie doit être minimale; Seule une petite batterie peut être contenue dans cette montre, et cette batterie devrait durer presque aussi longtemps que la montre elle-même. Et enfin, elle doit indiquer l’heure avec précision, de façon cohérente, car personne ne veut une montre qui soit inexacte. Chaque conception embarquée satisfait à son propre ensemble de fonctions et de contraintes. Selon , on estime à 50 000 le nombre de nouveaux modèles embarqués par an. Cela diffère des systèmes à usage général, tels que l’ordinateur de bureau. Le processeur qui fait fonctionner cet ordinateur est appelé un processeur « à usage général » car il a été conçu pour effectuer de nombreuses tâches différentes, par opposition à un système embarqué, qui a été construit pour effectuer quelques tâches spécifiques soit de manière optimale ou dans des conditions d’exécution très stricts. Les points suivants résument les principaux aspects propres aux systèmes et aux applications embarqués.
L’adaptabilité : une exigence clés pour les systèmes embarqués modernes
L’industrie des systèmes embarqués est confrontée à un grand nombre de défis, à différents niveaux de conception: de tels systèmes on exige des performances accrues tout en préservant une consommation d’énergie aussi faible que possible. Par ailleurs, ils doivent pouvoir réutiliser le code logiciel existant et en même temps tirer parti de la logique supplémentaire disponible dans la puce, représentée par plusieurs processeurs travaillant ensemble. Afin de répondre efficacement à de tel exigences, le concept d’adaptabilité apparaît comme une solution a la fois inévitable et de choix.
Dans ce qui suit, nous brossons un rapide tableau des principaux défis que les concepteurs de systèmes embarqués doivent gérer de nos jours et à l’avenir. En matière de contraintes et d’exigences, les systèmes embarqués doivent :
Satisfaire des contraintes de temps réel provenant des applications, qui peuvent être aussi bien des contraintes de temps réel souple (par exemple dans le cadre d’applications multimédia) que des contraintes de temps réel strict (par exemple dans le cadre de protocoles de communication). S’adapter ; à la nature périssable de certaines ressources (énergie) par le fonctionnement ; aux limites du matériel (surchauffe) ; aux capacités de stockage limitées. Ils doivent également intégrer l’instabilité des systèmes de communication utilisés (déconnexion, bande passante).
Offrir une puissance de traitement suffisante pour satisfaire les contraintes de temps d’exécution des applications. Les processeurs utilisés dans les systèmes embarqués sont 2 à 3 fois moins puissants qu’un processeur d’un ordinateur PC. Revenir au moindre coût surtout lorsque le système est produit en grande série.
Être doté d’une grande sûreté de fonctionnement surtout pour les situations de défaillance qui mettent en péril des vies humaines où des investissements considérables (explosion de la fusée américaine Discovery).
Ce type de systèmes sont dits « critiques » et ne doivent jamais faillir c.à.d. qu’ils doivent toujours donner des résultats corrects, pertinents et dans les délais attendus par les utilisateurs que ce soient des machines et/ou des humains. Avoir un poids efficient (un juste poids nécessaire au fonctionnement).
Ingénierie des domaines et ingénierie des applications
L’ingénierie des LPLs est séparée en deux phases complémentaires. L’ingénierie du domaine est concernée par le développement pour la réutilisation alors que l’ingénierie d’application est vise au développement par la réutilisation. L’idée derrière cette approche de l’ingénierie LPL est que les investissements requis pour développer les artefacts réutilisables pendant l’ingénierie du domaine, sont compensés par les avantages de la dérivation des produits individuels lors de l’ingénierie d’application. Une raison fondamentale pour la recherche et l’investissement dans les technologies sophistiquées pour les LPLs est d’obtenir le maximum de bénéfice de cet investissement initial, autrement dit, pour réduire au minimum la proportion des coûts d’ingénierie d’applications .
Ingénierie du domaine. Le processus de développement d’un ensemble de produits connexes (c.-à-d. Un LPL) au lieu d’un seul est appelé ingénierie de domaine. Une LPL doit remplir non seulement les exigences d’un seul client, mais les exigences de plusieurs clients dans un domaine, y compris les clients actuels et potentiels. Par conséquent, l’ensemble du domaine et ses besoins potentiels sont analysés, par exemple, pour identifier les différences entre les produits, les artefacts réutilisables et pour planifier leur développement, etc. L’ingénierie de domaine est le développement de la réutilisation: Les artefacts (exigences, composants, cas de test, etc.) Communs et réutilisables sont factorisés afin que leur réutilisation soit facilitée. Il est généralement composé de quatre activités: analyse de domaine, conception de domaine, le codage de domaine et le test de domaine. Dans l’analyse du domaine, les points communs et les différences entre les variantes potentielles sont identifiés et décrites, par exemple en termes de caractéristiques (fonctionnalités ou encore features). Dans ce contexte, une caractéristique est une abstraction de domaine de première classe, généralement un incrément visible dans la fonctionnalité de l’utilisateur final. Ensuite, les développeurs conçoivent et mettent en œuvre la LPL tel que différentes variantes peuvent être construites à partir de parties communes et variables. Ingénierie d’application. C’est le développement par la réutilisation (aussi appelé Développement de produits). Les produits concrets sont dérivés à l’aide de composants communs et réutilisables. Les artefacts développés dans l’ingénierie du domaine. Il se compose de quatre activités, parallèles aux activités d’ingénierie du domaine: l’ingénierie des exigences applicatives, conception de l’application, codage de l’application et test de l’application. Ce processus est basé sur l’ingénierie du domaine et consiste à développer un produit final, par la réutilisation des artefacts réutilisables et à adapter le produit final à des exigences spécifiques. Idéalement, les exigences du client peuvent être mappées à des éléments (par exemple, des caractéristiques) identifiés lors de l’ingénierie du domaine, de sorte que la variante peut être construite à partir de parties communes et variables existantes par de la mise en œuvre de la LPL. Le processus de construction de produits à partir des artefacts du domaine est appelé dérivation de produits. Selon la forme de l’implémentation, il peut y avoir différents processus d’ingénierie des applications, de l’effort de développement manuel à des technologies sophistiquées, y compris la configuration et la génération de variantes automatisée.
Les outils de modélisations des caractéristiques
Les premiers outils de modélisation des modèles de caractéristiques sont apparus dés 2004. La plupart de ces outils prennent en charge la création de modèles de caractéristiques mais également un support au processus de configuration et de configuration partielle dans une démarche de configuration par étapes . L’outil. FMP a été la le point de départ d’un tel effort. FMP fournit des vues arborescentes pour créer des modèles de caractéristiques, les configurer ou les configurer partiellement. LPLOT est un autre exemple d’outil basé sur le Web offrant un éditeur de modèle de caractéristiques sous la forme d’une arborescence, un éditeur de configuration avec la fonction de propagation de décisions et l’analyse automatisée du modèles ainsi qu’une bibliothèque des modèles type . FAMA est un Framework Java qui met l’accent sur la comparaison des différents solveurs pour l’analyse automatisée des modèles de fonction . Deux outils commerciaux intègrent la modélisation des caractéristiques et le processus de configuration ; pur :: variantes (pures :: variantes 2006, Beuche 2008) et Gears (BigLever – Gears 2006) et fournissent des extensions à plusieurs IDEs tels que Eclipse et Netbeans. FeatureIDE est un Framework basé sur Eclipse pour le développement de logiciels bases sur les modèles de fonctionnalités . L’objectif principal de FeatureIDE est découvrir l’ensemble du processus de développement et d’intégrer des outils pour la mise en œuvre de LPL dans un environnement de développement intégré.
L’informatique autonome
En octobre 2001, IBM a publié un manifeste (IBM, 2001) décrivant une nouvelle vision de l’informatique autonome. Le but est de faire face à la complexité des systèmes logiciels en rendant les systèmes autonomes. Cependant, L’un des points soulevé fut que les systèmes doivent devenir encore plus complexes pour y parvenir. La complexité, doit donc être intégrée dans l’infrastructure du système, qui peut à son tour être automatisée. La similarité de l’approche décrite avec le système nerveux autonome du corps, qui le soulage du contrôle de base de notre conscience, a donné naissance au terme d’informatique (ou calcul) autonome (Autonomic Computing).
Inspiré par la biologie, l’informatique autonome a évolué comme une discipline pour créer des systèmes logiciels et des applications qui s’autogèrent dans le but de surmonter la complexité et l’incapacité à maintenir efficacement les systèmes actuels et à venir. À cette fin, les efforts au niveau de l’automatisation couvrent tous les domaines de l’informatique et démontrent déjà leur faisabilité et leur valeur.
En 2001, IBM a proposé le concept de l’informatique autonome. En fait, les systèmes informatiques complexes sont comparés au corps humain, un système complexe, mais doté d’un système nerveux autonome qui s’occupe de la plupart des fonctions corporelles, soulageant ainsi notre pensé consciente de la tâche de coordonner toutes nos fonctions corporelles. IBM a suggéré que les systèmes informatiques complexes doivent être autonomes, c’est-à-dire devrait être capable de prendre en charge indépendamment les tâches de maintenance et d’optimisation régulières, réduisant ainsi la charge de travail des administrateurs système. IBM a également définit les quatre propriétés d’un système autogéré: auto-configuration, auto-optimisation, auto-guérison et autoprotection. Comme l’a déclaré Alan Ganek qui est l’un des responsables de l’informatique Autonome chez IBM: «L’informatique autonome est la capacité des systèmes à mieux s’autogérer. Le terme autonomique vient du système nerveux autonome, qui contrôle de nombreux organes et muscles dans le corps humain. Habituellement, nous ne sommes pas conscients de son fonctionnement, car il fonctionne d’une manière involontaire, réflexive. Par exemple, nous ne remarquons pas lorsque notre cœur bat plus vite ou nos vaisseaux sanguins changent de taille en réponse à la température, la posture, la nourriture, ou d’autres changements auxquels nous sommes exposés. »
Table des matières
Introduction générale
Chapitre 1. Les Systèmes Embarqués et l’adaptabilité logicielle
1.1 Introduction
1.2 Systèmes embarqués par rapport aux systèmes à usage général
1.3 L’adaptabilité : une exigence clés pour les systèmes embarqués modernes
1.3.1 L’écart de Performance
1.3.2 Les Contraintes de temps
1.3.3 Les contraintes sur la consommation d’énergie
1.3.4 Les contraintes de Mémoire
1.3.5 Réutilisation de code binaire existant
1.3.6 Rendement et coûts de fabrication
1.3.7 La communication
1.3.8 Tolérance aux pannes
1.3.9 Hétérogénéité et évolutivité de plates-formes matérielles
1.4 Conclusion
Chapitre 2. Ingénierie des lignes de produits logiciels
2.1 Introduction
2.2 Les lignes de produits logiciels
2.2.1 Personnalisation et réutilisation à grande échelle
2.2.2 Avantages escomptés
2.2.3 Stratégies extractives, réactives et proactives
2.2.4 Ingénierie des domaines et ingénierie des applications
2.2.5 Espace du problème et espace de la solution
2.3 Gestion de la variabilité
2.3.1 Variabilité
2.3.2 Modélisation de la variabilité
2.3.3 L‘implémentation de la variabilité
2.4 Les modèles de caractéristiques (features models)
2.4.1 Sémantique des modèles de caractéristiques
2.4.2 Formalisme
2.4.3 Quelques remarques importantes
2.5 Propriétés des modèles de caractéristiques
2.6 Opérations de raisonnement
2.7 Algorithmes et Automatisation
2.7.1 Les modèles de caractéristiques non propositionnels
2.8 Utilisation des modèles de caractéristiques
2.8.1 Caractéristique et variabilité
2.9 Les outils de modélisations des caractéristiques
2.10 Conclusion
Chapitre 3. Informatique autonomes et lignes de produits logiciels dynamiques
3.1 Introduction
3.2 L’informatique autonome
3.2.1 Définition
3.2.2 Propriétés du calcul autonome
3.2.3 La boucle autonome MAPE-K
3.3 Les lignes de produits logiciels dynamiques
3.4 Les approches existantes à la prise de décision dans les systèmes adaptables
3.4.1 Critères de comparaison
3.5 Conclusion
Chapitre 4. Les relations de dépendances transitives
4.1 Introduction
4.2 La variabilité revisitée
4.2.1 Résolution partielle de la variabilité liée
4.3 Les relations de dépendances entre caractéristiques
4.3.1 Des points de variation liés aux dépendances entre caractéristiques
4.3.2 Les deux dimensions de la relation de dépendance
4.3.3 Déterminisme et indéterminisme des relations de dépendance
4.3.4 Les dépendances directes entre caractéristiques
4.3.5 Les dépendances transitives entre caractéristiques
4.3.6 Les ensembles de dépendances transitives
4.3.7 L’opérateur de sélection transitive de caractéristiques
4.3.8 L’opérateur de sélection transitive pseudo-aléatoire de caractéristiques
4.4 Validation
4.4.1 Structures de données
4.4.2 Calcul des dépendances
4.5 Implémentation des opérations d’analyse des modèles de caractéristiques basées sur les dépendances transitives
4.6 Conclusion
Chapitre 5. Une approche évolutionnaire pour la prise de décision
5.1 Introduction
5.2 Aperçu de l’approche
5.3 Un nouvel algorithme génétique pour la prise de décision dans les systèmes logiciels embarqués adaptables
5.3.1 Formulation mathématique
5.3.2 L’algorithme génétique basé sur les dépendances transitives
5.3.3 Évaluation de l’algorithme
5.4 Conclusion
Chapitre 6. Adaptation de l’approche évolutionnaire au problème de l’auto-guérison
Introduction
6.1 Aperçu de l’approche
6.2 Une approche évolutionnaire pour l’auto-guérison
6.2.1 Reformulation du problème de la prise de décision pour l’auto-guérison
6.2.2 Ajustement de l’algorithme génétique basé sur les dépendances transitives pour le problème de l‘auto-guérison
6.3 Anticipation de la défaillance des composants dans le calcul des configurations alternatives
6.3.1 Une machine d’états finie pour la planification efficace de l’auto-guérison
6.3.2 Construction de la machine d’états finie pour la planification de l’auto-guérison
6.3.3 L’algorithme de planification de l’auto-guerison
6.4 Résumé du chapitre
Chapitre 7. Conclusion et perspectives
7.1 Contributions
7.2 Perspectives
Chapitre 8. Références bibliographique