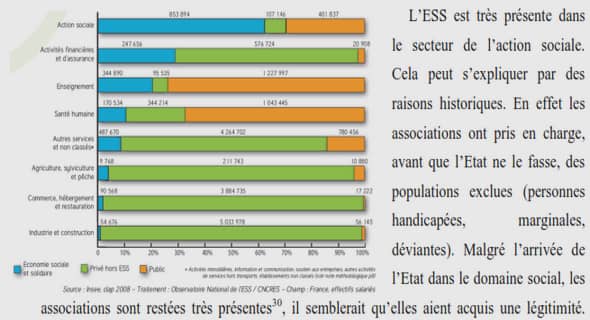
Télécharger le fichier original (Mémoire de fin d’études)
Création d’un réseau de neurones
Dans ce chapitre nous allons créer un réseau de neurones à propagation de l’information vers l’avant, plus précisément un perceptron multicouche. Nous allons utiliser le langage de programmation java [23].
Le Java est un langage de programmation orienté objet développé par Sun Microsystems, qui fut officiellement présenté en 1995. Non seulement c’est un langage de programmation, mais il est aussi un environnement d’exécution.Pourquoi avons-nous choisi ce langage ? Pour répondre à cette question, voyons quelques avantages du Java par rapport aux autres langages de programmations comme le C/C++.
Au niveau de la portabilité (compatibilité entre les systèmes d’exploitation et les ar-chitectures matérielles), le C/C++ est très faible [42]. Nous avons une obligation de recompiler le code sur chaque architecture sur laquelle le programme devra tourner. Par contre, le Java, grâce à sa JVM (Machine Virtuelle Java), permet d’avoir un très haut niveau d’abstraction par rapport à la machine. Nous n’aurons pas besoin de nous occuper de la compatibilité matérielle. De plus, avec Java nous n’aurons pas besoin de manipuler les pointeurs qui, en C/C++, peuvent être fatals s’ils sont mal utilisés [42]. Le java nous offre aussi une gestion automatique de mémoire grâce au « Garbage Collector » et une librairie de codes (API) très riche. Dans notre programme, nous utilisons par exemple le JFreeChart et le javacsv, qui sont des API tierces[23].
Bref, Java est en constante amélioration. Chaque nouvelle version apporte son lot de nouveautés au niveau de l’API et apporte de nettes améliorations au niveau des perfor-mances et de la stabilité. Il nous permet de développer plus rapidement et d’être plus reproductif.
Grâce à ses avantages cités ci-dessus, le Java nous facilite beaucoup le développement de notre PMC. Plusieurs auteurs ont aussi choisi le langage java pour développer les réseaux de neurones, on peut citer comme référence les travaux de Jeff Heaton [22].
Les neurones
Nous définissons un neurone comme un objet et chaque neurone peut avoir sa liste des poids d’entrée et sa liste des poids de sortie. Chaque poids doit être initialisé à une petite valeur aléatoire. Pour initialiser ces poids nous utiliserons une fonction qu’on appelle initNeurone dans la classe Neurone. Nous avons aussi besoin de deux conteneurs pour stocker les anciens deltas associés aux poids synaptiques du neurone.
Figure 2.1 – Diagramme UML pour la classe Neurone
L’architecture du réseau
Nous allons considérer un réseau de neurones comme un objet. Nous savons que dans un réseau à propagation de l’information vers l’ avant les neurones sont arrangés en couches : une couche d’entrée, des couches cachées et une couche de sortie. Pour ce faire nous allons créer une classe abstraite appelée Couche et les différentes couches des classes qui héritent de cette classe.
Notre classe couche
Une couche est composée de neurones, alors dans notre classe nous avons besoin d’une liste qu’on stockera les neurones sur la couche et le nombre de neurones sur la couche.
• La couche d’entrée
La couche d’entrée est une couche, donc elle hérite de la classe mère. Pour initialiser chaque poids des neurones sur la couche, nous utilisons la fonction initCouche en faisant appel à la fonction initNeurone de la classe neurone. Dans cette classe, nous créons un neurone supplémentaire pour définir le biais.
• Les couches cachées
Les couches cachées sont les couches de connexion entre les neurones de la couche d’entrée et ceux de la couche de sortie. Le nombre de couches cachées peut être supérieur à un, alors il y a aussi la connexion entre les couches cachées. Nous devons donc initialiser chaque poids suivant ces trois types de connexions. Nous devons aussi tenir compte des biais pour chaque couche cachée.
• La couche de sortie
La couche de sortie ne contient que l’initialisation et la liste des neurones sur la couche.
Nous avons le diagramme suivant :
Figure 2.2 – Diagramme UML pour les classes Couches
Le réseau
Notre classe Réseaux est divisée en deux parties, l’initialisation et la phase d’appren-tissage du réseau.
Initialisation du réseau
On initialise un réseau en définissant son nombre de neurones sur chaque couche et son nombre de couches cachées. Ainsi on définit un réseau de la façon suivante : Réseau(nombre de neurones sur la couche d’entrée,nombre de couches cachées, nombre de neurones sur la couche cachée,nombre de neurones sur la couche de sortie). L’initialisation du réseau consiste aussi à initialiser les poids entre les différentes connexions dans le réseau.
La phase d’apprentissage dans la classe réseau
La phase d’apprentissage du réseau consiste à appeler l’algorithme de backpropagation qu’on définira plus tard (cf. 2.3.2).
Ces deux fonctions forment la classe réseau. Mais pour faire fonctionner le réseau avec l’algorithme de backpropagation, on a besoin de quelques variables supplémentaires comme la matrice d’entrée, la matrice de sortie, le pas d’apprentissage, le momentum et le nombre maximal d’époques. A chaque époque, on fait une mise à jour de tous les poids du réseau.
Apprentissage du réseau
L’apprentissage du réseau
Pour apprendre le réseau avec l’algorithme de rétro-propagation, nous allons créer une classe abstraite qu’on nommera Apprentissage qui contient les fonctions d’activations et leurs dérivées. Nous utilisons dans notre réseau la fonction sigmoïde comme fonction d’activation des neurones des couches cachées et la fonction linéaire pour les neurones de la couche de sortie.
Les erreurs
Nous allons utiliser deux types d’erreurs pour vérifier la validité des résultats estimés et pour voir le comportement du réseau.
Back propagation
L’algorithme de rétro-propagation des erreurs se divise en deux étapes. La première étape consiste à la propagation de l’information vers l’avant et la deuxième étape c’est la rétro-propagation des erreurs. A chaque prototype, on fait propager les informations et rétro-propager l’erreur.
La propagation vers l’avant
Nous avons besoin de trois variables :
— sortieEstimee : désigne la sortie du réseau
— sortieDesiree : Valeur attendue
— SomErreur : qui définit la somme des fonctions de coût de chaque prototype
• Entre la couche d’entrée et la couche cachée
Les sorties de la couche cachée sont données par (1.21) mais on doit exclure le biais parce qu’il n’a pas d’entrée.
• Entre la couche cachée et la couche de sortie
Pour calculer la sortie du réseau, nous utilisons l’équation (1.13) mais en ne tenant pas compte du biais. Calculons tout d’abord (1.14) puis appliquons la fonction d’activation. (1.15)
La rétro-propagation des erreurs
La rétro-propagation des erreurs consiste à calculer les deltas (1.20) et (1.28) dans la section (cf. 1.6.1) et de mettre à jour les poids synaptiques utilisant les équations (1.19) et (1.29).
La régularisation
Pour pouvoir calculer le second terme de régularisation dans notre fonction de coût (1.31), nous avons besoin d’une fonction que nous appelonsRégularisation.
Pour exploiter ces trois fonctions dans notre classe backpropagation, nous avons créé une autre fonction que nous appelons apprendre. La fonction sert non seulement de pro-pager les entrées et rétro-propager les erreurs pour chaque prototype mais aussi de tester si le réseau subit un overfitting.
Notre classe Backpropagation est donc composée par les quatre fonctions : apprendre, propager, régularisation et backpropagation.
Nous pouvons résumer l’apprentissage de notre réseau avec le diagramme suivant : Figure 2.4 – Diagramme UML pour les classes Apprentissage et Backpropagation
En résumant, vus en tant qu’objet, les réseaux de neurones sont devenus simple à pro-grammer. Notre perceptron est donc composé de deux paquets de classes. Le premier défini l’architecture du réseau. Il est composé par la classe abstraite couche et les diffé-rentes classes filles CoucheEntree, CoucheSortie et CoucheCachee, notre classe Neurone et notre classe Réseaux qui définit la topologie du réseau(feed-forward dans notre cas). Le deuxième paquet contient notre classe Backpropagation qui hérite de notre classe abstraite Apprentissage.
Théorie du chaos et l’application logistique
Introduction
L’étude du chaos nous fait remonter jusqu’ aux travaux du météorologiste Edward Lorenz en 1963[26]. Il a calculé les courants de convections de l’atmosphère à l’aide d’un ordinateur et retrouva l’effet d’amplification considérable des petites différences des condi-tions initiales. Des petites causes comme des orages localisés peuvent avoir de grands effets sur le temps au niveau de l’hémisphère. La sensibilité de tels systèmes à de très petits changements dans les conditions initiales entrainait l’impossibilité de prédire leur com-portement.
Le terme chaos fut proposé peu après pour décrire ce genre de situation. Dans les années 1970, Lorenz appliqua ses considérations à la biologie des populations [25] et l’on s’aperçut plus tard que les comportements chaotiques concernent de multiples phénomènes dans divers domaines, comme le fonctionnement du laser[27], l’évolution de l’écosystème [28] ou la cinétique des réactions chimiques[29].
En 1971, Floris Takens et David R montrèrent que le comportement chaotique n’est pas intrinsèquement lié à un grand nombre de paramètres et introduisirent la notion d’attracteur étrange pour désigner la courbe caractéristique des paramètres d’un système chaotique [30].
Depuis, le chaos est devenu incontournable dans de nombreux domaines comme : l’étude des systèmes dynamiques, l’électronique, la biologie, la finance et l’économie et dans l’analyse des séries temporelles, etc.
L’application logistique
L’application logistique est le cas le plus simple d’un système dynamique discret et non autonome [31] .c’est-à-dire dépendant du temps. Elle est apparue pour la première fois en 1838, et qui est utilisée par Pierre-François Verhulst pour modéliser la dynamique de la po-pulation en Biologie [32]. En 1985, Mandelbrot a ensuite étudié ce modèle pour ses aspects chaotiques en construisant son diagramme de phase appelé ensemble de Mandelbrot[33].
En général, un système dynamique discret est décrit par un système d’équations aux différences finies ou bien une récurrence.
Table des matières
Introduction
I Réseaux de neurones Théorie et création
1 Les réseaux de neurones
1.1 Historique
1.2 Les neurones biologiques
1.3 Le neurone formel
1.3.1 Les fonctions d’activation
1.4 Les réseaux de neurones artificiels
1.4.1 Topologie
1.5 Apprentissage des réseaux
1.5.1 L’apprentissage supervisé
1.5.2 L’apprentissage non supervisé
1.6 Les réseaux multicouches à propagation de l’information vers l’avant
1.6.1 L’algorithme de rétro-propagation
1.6.2 Amélioration
1.6.3 Overfitting
2 Création d’un réseau de neurones
2.1 Les neurones
2.2 L’architecture du réseau
2.2.1 Notre classe couche
2.2.2 Le réseau
2.3 Apprentissage du réseau
2.3.1 L’apprentissage du réseau
2.3.2 Backpropagation
II Application logistique et prédiction des séries temporelles
3 Théorie du chaos et l’application logistique
3.1 Introduction
3.2 L’application logistique
3.2.1 Définition
3.3 Observations
3.3.1 Allure de la fonction
3.3.2 Orbite ou trajectoire du système
3.3.3 Points fixes
3.3.4 Points périodiques et Orbites périodiques
3.3.5 Orbite attractive et orbite répulsive
3.4 Les bifurcations
3.4.1 Branches de points fixes et de points périodiques
3.5 Les exposants de Lyapounov
3.6 Conclusion
4 Séries temporelles et prédiction
4.1 Introduction
4.2 Définition
4.3 Types de séries chronologiques
4.4 Prévision
4.4.1 Les méthodes
4.5 La prévision par le perceptron multicouche
4.5.1 Recherche de l’architecture de notre PMC
4.5.2 La phase d’apprentissage du réseau
4.5.3 La Prédiction
5 Applications et résultats
5.1 Présentation des données
5.2 Simulation
5.3 Résultats
5.3.1 Séries non chaotiques : μ = 2 et μ = 3.5
5.3.2 Séries temporelles chaotiques μ = 4
Conclusion générale
A Codes sources I
A.1 Classe série temporelle
A.2 Classe Prédiction
A.3 Classe Jacobi
A.4 Classe Matrix
A.5 Classe Chart
A.6 Classe Data
B Méthode de Jacobi XXIII