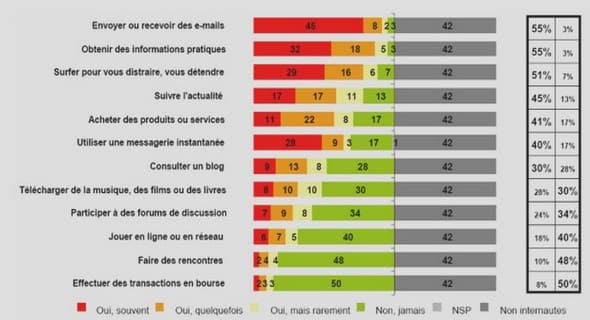
TECHNOLOGIQUES DES SYSTEMES D’INFORMATION GEODECISIONNELS
La modélisation dans les systèmes informatiques décisionnels L’objectif de ce sous-chapitre est de présenter dans un premier temps les fondements théoriques et méthodologiques du décisionnel et dans un second temps une transposition d’un cas simple de modélisation multidimensionnel appliqué au domaine des risques naturels.
Définition des systèmes d’information décisionnels
L’utilité des systèmes décisionnels
Les systèmes d’information décisionnels (SID) sont nés d’un besoin des entreprises de fournir aux décideurs des moyens d’accéder aux données de leurs propres systèmes dans le but de piloter leurs activités. Ces moyens ne sont pas satisfaits par les systèmes de gestion de bases de données traditionnels. En effet ceux-ci fonctionnent selon un mode dit transactionnel c’està-dire conçus spécifiquement pour ajouter, modifier, supprimer des données propres à une activité métier. Le mode transactionnel est désigné sous le terme OLTP (« On-Line Transactionnal Processing »). Dès lors qu’il s’agit de faire du reporting ou de l’analyse de données pour piloter l’activité les systèmes informatiques se sont rapidement trouvés limités ; pour arriver à fournir des tableaux de synthèse pour les équipes de direction il fallait mettre en place des requêtes complexes, coûteuses en temps de réponse et en ressources informatiques. Les SID sont apparus comme une nécessité pour faire face à l’augmentation des volumes de données et à la difficulté grandissante des décideurs à disposer de résultats tangibles sur les différentes branches d’activité. Des outils ont été conçus spécifiquement pour extraire les données provenant de sources hétérogènes, les stocker dans un ensemble homogène orienté métier puis enfin restituer les résultats dans des interfaces d’analyse et de reporting. On peut citer l’outil DataStage édité par IBM1 et les outils Informatica2 . Ces outils sont mis à la disposition des décideurs pour supporter de manière efficace leurs prises de décision [Codd 1993] [Inmon 1994] [Chaudhuri et al. 1997]. Dans le secteur de l’assurance comme dans d’autres secteurs industriels, les processus OLAP sont utilisés pour les fonctions de reporting auprès des directions techniques et des équipes de directions afin de suivre l’évolution de leurs branches d’activité (suivi des achats, des ventes, de la production, etc.). Les valeurs suivies sont souvent quantitatives et financières : montants des ventes, chiffres d’affaires par magasin, niveaux de rentabilité des points de vente, etc. Parfois les valeurs suivies sont qualitatives comme des notations sur l’appréciation des performances : satisfaction des clients, satisfaction des actionnaires, satisfaction des partenaires et des employés. Les outils d’analyse et de reporting permettent de naviguer à l’intérieur des processus décisionnels et des entrepôts de données ou magasins de données pour consulter les résultats des indicateurs suivant les axes thématiques métiers choisis pour la conception de ces structures de données qu’on appelle aussi « cube de données ». A titre d’exemple une société d’assurance consolide des cubes dédiés à des thèmes comme la production (encaissements des primes par branche et par produit), sur les sinistres (par type de sinistre), sur les forces commerciales (les distributeurs agents, courtiers, réseau salariés), sur la productivité (par processus métiers, par engagement de service) ou bien sur des spécialités comme la réassurance ou la coassurance. D’autres cubes sont orientés spécifiquement sur le pilotage technique intégrant à la fois des données de production et des données sur les sinistres (calcul du S/P et du ratio combiné, calcul du bonus malus, etc.). Le pilotage stratégique global repose davantage sur le concept de tableau de bord permettant d’avoir une vue d’ensemble de la situation de l’entreprise. Les indicateurs de performance sont jaugés et présentés sur des axes intégrant à la fois la performance financière, la satisfaction des clients, la mesure des processus métiers et le degré d’apprentissage organisationnel au travers de l’amélioration continue des processus. C’est ce qui est défini dans le Tableau de Bord (TDB) Prospectif de Kaplan et Norton [Kaplan et al., 1996]. Cette démarche conduit à industrialiser la stratégie de l’entreprise depuis une vision globale jusqu’à une vision opérationnelle par le biais d’indicateurs mesurables et concrets (ces indicateurs pouvant être quantitatifs ou bien qualitatifs). Les SID constituent un socle de base pour alimenter et consolider ces TDB. Dans la vision de Lebraty ([Lebraty, 2008]) « d’une architecture technologique décisionnelle » du système d’information de l’entreprise, le SID se positionne comme un bloc support dans un environnement tridimensionnel : – les processus métiers qui sont transverses à l’organisation de l’entreprise (ex : gestion de la relation client, gestion des prestataires, gestion de la production) – les fonctions spécialisées qui sont propres à chaque service ou département de l’organisation de l’entreprises (ex : comptabilité, commercial, production) – le décisionnel comme support aux décisions opérationnelles et aux décisions stratégiques La figure 12 montre la transposition de cette architecture tri-dimensionnelle à l’environnement d’une société d’assurance.
L’architecture décisionnelle
Le SID n’est pas intégré dans le Système d’Information Opérationnel (SIO) de l’entreprise. Ce dernier est entendu comme la partie contenant l’ensemble des données transactionnelles enregistrées lors des actes de gestion réalisés par les opérateurs de l’entreprise. Si l’on prend l’exemple d’une société d’assurance, les bases de données opérationnelles vont essentiellement contenir les contrats d’assurance souscrits, les sinistres des clients, les missions des experts et des réparateurs, les informations sur les clients, les produits commerciaux, les garanties et les règles de gestion associées. Les opérateurs sont les souscripteurs, les gestionnaires de sinistre, les agents généraux, les courtiers voir même les clients eux même. Le SIO contient le vivier de données exploitable par la suite pour l’analyse dans les SID. En effet la construction des indicateurs pour le reporting et le pilotage consiste à puiser dans les données transactionnelles. Les utilisateurs finaux d’un SID au sein d’une société d’assurance sont les membres de la direction technique, les actuaires, les équipes de direction régionales, les services financiers et comptables et enfin la direction générale. – 62 – Un des traits de la distinction entre le SIO et le SID réside dans l’architecture du système de stockage des données. Dans un SIO l’environnement transactionnel de stockage pour les sociétés d’assurance repose historiquement sur des environnements de type MainFrame ou « Ordinateur Central » en français. De par leur fiabilité et leur puissance, ils sont parfois les seuls ordinateurs capables de répondre aux besoins de leurs utilisateurs (traitement de très grandes banques de données accédées par des dizaines ou des centaines de milliers d’utilisateurs). Dans ce type d’environnement les données sont stockées dans des fichiers de type VSAM ou bien dans des Systèmes de Gestion de Bases de Données Relationnels (SGBDR) comme DB2. D’autres environnements transactionnels hors MainFrame utilisent des SGBD comme ORACLE, MySQL ou SQL Server comme mode de stockage. La modélisation relationnelle conçue par Codd dans les années 60 chez IBM [Codd, 1970] repose sur un stockage sous forme de tables avec un système de normalisation pour éviter la redondance lors de la saisie, l’unicité et l’intégrité des données en s’appuyant sur les principes de l’algèbre relationnelle (théorie des ensembles, logique des prédicats du premier ordre). Mais ce mode de stockage ne propose pas de fonctions de synthèse, d’analyse et de consolidation nécessaires à la prise de décision (par exemple il sera difficile de savoir quel est le nombre de ventes du produit X pendant le trimestre A de l’année B dans la région C avec un environnement relationnel). C’est en 1993 que Codd établi douze règles d’architecture pour mettre en place des structures dites multidimensionnelles. Parmi ces règles, les caractéristiques d’une structure multidimensionnelle sont : – orientée-sujet : signifie que les données sont structurées selon des centres d’intérêt des managers. Afin de réaliser une telle structure de données, de nouveaux modèles de données ont été mis en œuvre (modèle multidimensionnel en étoiles ou en flocons) – intégrée : les données proviennent de différentes sources et sont réunies au sein de l’entrepôt de données – évoluant avec le temps : chacune des données est liée à une date – non volatile : les données sont conservées et pas remplacées dans un processus de mise à jour. Finalement Kimball [Kimball, 1996] et Immon [Immon, 1996] vont exploiter ces règles pour définir les méthodes de conception des entrepôts de données (datawarehouse DW). Un Datawarehouse ou « Entrepôt de données » se définit comme suit : « Un système de DW organise et conserve les données nécessaires aux processus informationnels et analytiques dans une perspective de long terme. Ce système correspond à un ensemble de données orientées selon un sujet, intégrées, évoluant dans le temps et non volatiles, qui a pour but l’aide au processus de prise de décision de gestion » [Immon, 1996] Les Datawarehouses peuvent être découpés en Datamarts ou « Magasins de données » pour cibler encore plus finement les problématiques et se focaliser sur la décision autour d’un thème particulier.