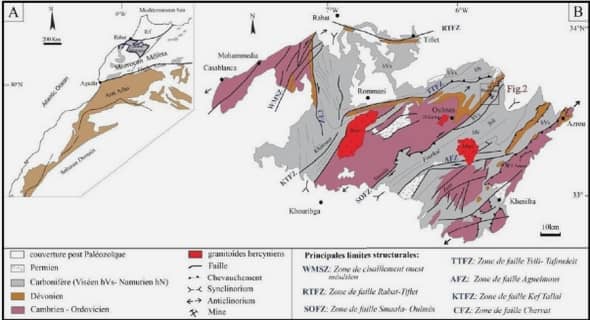
Contrainte des modèles génétiques de réservoirs par une approche de reconnaissance statistique de forme
Modélisation numérique d’un réservoir
La caractérisation d’un réservoir est indispensable tout au long de son évolution, de sa découverte à son épuisement. C’est là où les modèles numériques représentent au fur et à mesure le gisement exploité. La construction d’un modèle numérique nécessite un minimum de connaissances sur le réservoir, notamment, les caractéristiques physiques, qui sont obtenues essentiellement à partir de forages de reconnaissance, de carottages et de diagraphies. Naturellement, les caractéristiques physiques d’un réservoir varient continûment dans l’espace et dans le temps. Mais les moyens numériques de modélisation sont limités par la capacité de calcul. C’est la raison pour laquelle le gisement est discrétisé en blocs, auxquels on attribue différents lithofaciès et des propriétés pétrophysiques numérisées. Expérimentalement, la modélisation d’un réservoir consiste à représenter numériquement ses hétérogénéités à différentes échelles. Une telle modélisation se fait selon les trois grandes étapes suivantes : La modélisation géologique est la première étape de modélisation du réservoir. Elle consiste en une description numérique de la structure lithologique interne, c’est-à-dire des volumes constituant les différents objets géologiques (failles, fractures, lentilles, chenaux …). Les hétérogénéités du réservoir dépendent des processus sédimentaires mettant en jeu le temps, la température et un certain nombre de conditions physico-chimiques. Elles peuvent donc être de nature et d’échelle différentes [Bour et al. (2002), Kazemi et al. (2005)] (Fig. 1). Le modèle numérique géologique est souvent très détaillé et représente les objets géologiques contrôlant l’écoulement (la dimension de la maille de discrétisation est autour de 10m). La variabilité des structures géologiques est, en général, plus fine verticalement qu’horizontalement. Cette anisotropie spatiale impose l’anisotropie de discrétisation, i.e. la dimension horizontale de maille est souvent supérieure à sa dimension verticale (e.g. maille d’un modèle géologique en 3D peut être d’ordre de 10m, 10m et 1m en X, Y et Z). Fig. 1 Formations sédimentaires d’échelle différente. Cette première étape de modélisation est très importante, car la qualité de simulation du comportement d’un réservoir est fortement liée au réalisme du modèle géologique. Pour cette raison, il est indispensable de savoir intégrer des données de natures différentes (sismique, diagraphie, mesure de carotte …) dès cette première étape de modélisation [Beucher (1998)]. L’étape suivante est la modélisation pétrophysique. Une fois les objets géologiques et leur répartition spatiale modélisés, il importe de spécifier les propriétés des roches qui les constituent [Bour et al. (2001), de Dreuzy et al. (2004)]. Les principales variables d’intérêt Modélisation numérique d’un réservoir sont la porosité, la perméabilité, la résistance de la roche. Ces propriétés sont définies sur le maillage géologique afin de mieux décrire leur variabilité. La dernière étape de modélisation de réservoir est une modélisation hydrodynamique. Un modèle discrétisé du réservoir étant bâti, des simulations d’écoulement peuvent être envisagées [Sarda et al. (2001)]. Par souci d’économie de temps calcul, les modèles hydrodynamiques sont réalisés sur des grilles plus larges que les modèles géologiques (la maille d’un modèle hydrodynamique en 3D est typiquement d’ordre de 100m, 100m et 10m en X, Y et Z). Bien que jugé irréaliste par les géologues, ce modèle hydrodynamique s’avère néanmoins efficace pour simuler le comportement d’un réservoir et en prédire la production. La qualité de la prédiction fournie par le modèle hydrodynamique dépend de nombreux facteurs. Ici nous nous bornons à n’en mentionner que les deux plus importants : Le premier facteur à prendre en compte pour construire un modèle réaliste de réservoir est la reproduction de sa structure interne. Par exemple, la substitution d’un réseau de fractures par un milieu poreux dans le modèle géologique engendre une sous-estimation de la vitesse de fluide dans le modèle hydrodynamique. De son coté, la sous-estimation de vitesse de fluide provoque une sous-estimation du temps d’arrivée de l’eau au puits de production. La simulation des écoulements dans un tel contexte nécessite donc une très bonne représentation des hétérogénéités majeures que constituent les objets géologiques. Le deuxième facteur, qui affecte largement la qualité de prédictions en production, est l’intégration des données dynamiques (calage de données d’essais de puits ou de production) qui est effectuée à cette étape de modélisation. Si même après avoir effectué un calage historique, les données obtenues par la modélisation hydrodynamique restent éloignées des données réelles, nous serons amenés à modifier le modèle géologique [Roggero et al. (2005)] afin de réduire cette différence et mieux représenter l’hétérogénéité souterraine.
Modélisation géologique
La construction d’un modèle géologique de réservoir est basée sur la représentation de l’environnement de dépôt géologique, y compris les hétérogénéités majeures contrôlant l’écoulement des fluides (chenaux fluviatiles, couches imperméables, failles …). La fiabilité de ce modèle augmente au fur et à mesure qu’il est conditionné aux données quantitatives telles que mesures de carottes, diagraphie, sismique. On peut distinguer deux types d’approches de modélisation géologique : l’approche génétique et l’approche stochastique.
Approche génétique
Les premiers travaux entrepris pour modéliser la structure géologique interne d’un réservoir relèvent de cette approche. Ils s’appuient sur une modélisation des processus de sédimentation, permettant ainsi de respecter les hétérogénéités naturelles du réservoir. Cette modélisation est avant tout déterministe par prise en compte des lois physiques qui régissent l’évolution des milieux fluviatiles à échelle géologique, mais présente aussi un aspect aléatoire pour reproduire le comportement parfois erratique de la nature. Les modèles génétiques des premiers travaux de Matheron (1969) ont été repris et poursuivis dans plusieurs directions. Le modèle d’architecture fluviatile résulte de la simulation des blocs gréseux représentant des ceintures de chenaux. Ce modèle est basé sur une formulation mathématique de concepts et de connaissances géologiques sans pour autant intégrer des processus sédimentaires. Le modèle hydraulique de bassin repose sur l’utilisation de lois hydrauliques à l’échelle du bassin, ce qui lui permet d’appréhender la géométrie générale du réservoir. Lorsqu’il s’appuie sur les lois physiques de sédimentation, ce type de modèle intègre de nombreux paramètres contrôlant la formation des dépôts. Le modèle fluviatile dynamique porte à la fois sur la géométrie des systèmes fluviaux et sur leur évolution dynamique. La tendance à incorporer le maximum de processus physiques liés aux formations sédimentaires (transport hydraulique, déviation et éboulement des chenaux, migration latérale etc.) rend la modélisation génétique de plus en plus complexe. Pour plus de détail, le lecteur pourra consulter les travaux de Kolterman et Gorelick (1996) qui dressent un inventaire des différents types d’approche génétique. Au cours des dernières années, des progrès considérables ont été réalisés dans la compréhension des systèmes sédimentaires méandriformes. Teles et al. (1998) et plus tard Modélisation géologique Introduction 16 Lopez (2003) proposent une modélisation génétique qui incorpore des processus de sédimentation ainsi que l’évolution tectonique de chenaux en temps géologiques pour restituer le système méandriforme dans toute sa complexité. L’avantage majeur des modèles génétiques est qu’ils fournissent des résultats facilement interprétables en termes de processus sédimentaires. Ils conduisent également à des architectures géologiques beaucoup plus réalistes que les modèles stochastiques. Leur principal inconvénient est qu’il est difficile de les conditionner de manière satisfaisante à des données quantitatives telles que les données de puits ou de sismique. Le conditionnement d’un modèle contenant des objets géologiques parait beaucoup plus facile si sa structure interne est définie par une fonction aléatoire. C’est ainsi que peu à peu apparaît l’approche stochastique.
Approche stochastique
L’approche stochastique consiste à concevoir une fonction aléatoire pour représenter l’hétérogénéité spatiale d’un réservoir. De nombreux modèles probabilistes peuvent être envisagés pour caractériser un réservoir [Matheron (1968), Chilès et Delfiner (1999), Lantuejoul (2002)]. Un modèle est choisi en fonction de l’environnement de dépôt, de l’échelle de travail et de la géométrie spécifique (connue à priori par les géologues). Parmi les modèles stochastiques d’utilisation courante, il est d’usage de distinguer deux grandes catégories : les modèles de type pixel et les modèles de type objet. Les modèles de type pixel fournissent des réalisations d’une fonction aléatoire aux nœuds d’une grille, régulière ou non. En utilisant peu de paramètres (par rapport au modèle génétique et au modèle de type objet), le modèle de type pixel est capable de décrire de fortes hétérogénéités tout en intégrant des relations entre faciès géologiques (Fig. 2). Il existe un vaste choix de modèles de type pixel. Son choix effectif est dicté par la structure géométrique à reproduire. Citons ici deux modèles d’utilisation courante : la fonction gaussienne seuillée [Matheron et al. (1987)] et la simulation séquentielle d’indicatrice [Journel et Alabert (1990)]. Fig. 2 Exemple de la simulation plurigaussienne. Les images en haut sont gaussiennes. En bas à droite l’image représente la proportion et le schéma de troncature de 3 types de faciès. Le résultat de la troncature est en bas à gauche. [Lantuéjoul 2002]. Les modèles de type pixel se prêtent bien au conditionnement par des données quantitatives, y compris des données dynamiques de production [Hu (2000)]. Souvent, des statistiques spatiales sont disponibles (moyenne, variance, variogramme …) [Hu et Le Ravalec-Dupin (2004)]. Ces statistiques peuvent être utilisées pour ajuster la fonction aléatoire représentant le modèle afin d’améliorer la reproduction de la géométrie d’un milieu hétérogène. Mais, ni la diversité des modèles, ni leur ajustement ne permettent de capter et de reproduire certaines structures géologiques complexes telles qu’un système de chenaux méandriformes par exemple. Sous l’appellation modèles de type objet, on désigne tout modèle qui utilise des formes géométriques plus ou moins complexes pour représenter les hétérogénéités d’un réservoir (chenaux [Deutsch et Wang (1996)], failles et fractures [Cacas et al. (2001), Gauthier et al. (2002)], crevasses, barrières etc.). Ces formes géométriques ou objets sont des représentations idéalisées des corps géologiques du réservoir. Chaque objet est défini par sa position et par ses caractéristiques géométriques (forme, taille, orientation). Des règles de répulsion ou d’attraction entre les corps simulés doivent être employées afin de décrire leur répartition dans l’espace. Un exemple (Fig. 3) d’utilisation de l’approche objet en milieu fracturé peut être vu chez Jenni (2005).
Introduction |