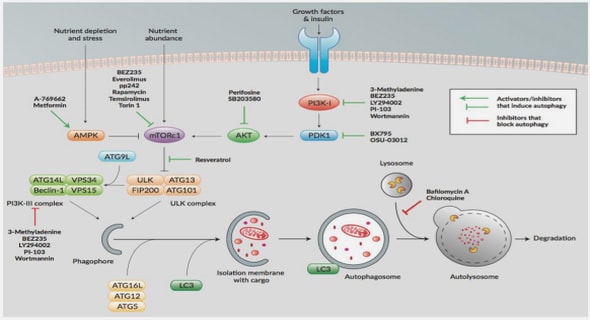
Knowledge Discovery in Biological Data
Optimisation and Metaheuristics
The optimisation problem is a kind of problems where an exact solution can’t be found in reasonable time (Kann 1992). Optimisation is everywhere, such as aeronautics, biology, and economy. Optimisation has been widely used in Bioinformatics to solve combinatorial problems with biological data. The nature of manipulated data has been used to classify the optimisation problems in two categories (discrete and continuous optimisation problems). The nature of the objective and the feasibility of the solution can also classify optimisation problems in different categories. In the current chapter, we present the general model of an optimisation problem, by describing the categories of different optimisation problems. After that we describe the optimality searching characteristics and the well-known metaheuristics for the optimality searching. We described an algorithm from each metaheuristic category. Ant Colony Optimisation algorithm, Particle Swarm Optimisation for population based algorithms, neighbourhood searching and discontinuous algorithms. Genetic algorithm from evolutionary algorithms, and Tabu search for trajectory based algorithms and memory usage algorithms.
Combinatorial Optimisation
Computational complexity theory is a subfield of theory of computation that classifies the practical difficulty of solving problems (Hazewinkel 2001). The time consuming of the solving methods is the main criteria to classify those methods. Combinatorial optimisation consists of finding the optimal object from a set of finite objects. Combinatorial optimisation methods can be divided mainly into two categories: Exact and approximate methods. Exact methods are the methods that provide the exact solution or all possible exact solutions for the problem. There is a large number of exact solvers for combinatorial problem such as, Dynamic programming (Bellman 1958) and Branch and Bound (Land et a., 1960). These methods are time consuming and hard to be used in a complex problems. The second category of the combinatorial problem solvers is the approximate methods (Vazirani 2003), aims to find approximate solutions, near the best solution or the best solution means that it doesn’t guarantee to find the best solution. Approximate algorithm is often used for problems that don’t have an algorithm in polynomial time, this class of algorithm called NP-hard (non-deterministic polynomial-time hard) (Daniel et al., 1994). The approximation ratio is the ratio between the result obtained by the algorithm and the optimal profit. Further detailed information about this specific class will be synthesised extensively in the next section. 2.3 Optimisation ISO 26262 defines the functional safety standard for the passenger vehicle industry, one of the main problems for vehicle designer is to find the optimal allocation and decomposition of the Automotive Safety Integrity Levels (ASILs) to the different components of the system (Papadopoulos et al., 2010). This allocation must satisfy some requirements called Custsets (CS) and ensure the minimum cost of the total allocation. The airline industry faces one of the largest scheduling problems of the industrial transport related services. The objective is to find the efficient planning and scheduling for the different aircrafts and staffs (Farah et al., 2011). Optimisation is everywhere, peoples always try to find the optimal, the efficient, the best, the ideal, the perfect, the decisive, the powerful, or the productive solution to their problems. The optimisation is one of the most used tools in decision aid science and in the analysis of real systems (Belegundu et al., 2011). What we need (martials) in order to use the optimisation methods to solve a given problem? The main thread is to define the objective(s) of the problem, means to set a quantitative measure to compute the robustness of a given solution of the problem. This objective is based on all influenceable parameters and their allowed values of the systems which will be considered as unknowns in the optimisation process. The optimisation problem which can be seen as the maximisation or minimisation of a function subject to a set of constraints on its variables (Nocedal et al., 2006). The mathematical modelling of an optimisation problem is as follows: Let x be a set of parameters (vector of variables), f is a function of x, and C is a vector of constraints on the variables x. The optimisation problem can then be stated as follows: Objective: To find 𝑥 = Which Minimise/Maximise f(x) Subject to: 𝐶𝑖(𝑥) The optimisation problems can be classified in numerous ways. First, discrete optimisation problems which refer to the class of optimisation problems which the solution we investigate is one of a number of objects in a finite set (Lee 2004). The discrete variables can take only a finite number of values such as the qualitative and categorical variables, like when we want to find the best instructions that improve the performance of machines. For some problems, the variables are restricted to be integers, this kind of problems are known as integer programming problems (𝑥 ∈ Z). An example of integer programming problem is the ASIL allocation problem, it defines a set of safety levels to ensure the required total safety of the system. It would not make sense to advise the company to allocate the third and half safety level to such components. On the other hand there is continuous optimisation problems when the solution we investigate is from an unaccountably infinite set, usually real numbers (𝑥 ∈ R). If the variable x can contain any value within some range is called continuous (Boyd et al., 2004). In discrete and continuous optimisation problems the x variable vector can take value in specific domain. In some optimisation problems some values of the x variable’s domain are not allowed. Optimisation problems can be divided in two classes. First, unconstrained optimisation problems with unrestricted domain for the x variable’s, means you have to optimize the objective function without having to care about the variables values. Second, constrained optimisation problems with restricted domain for the variables x, such as peoples maximizing benefits subject to a budget constraint. The solution within the allowed rang, are called feasible solutions (Verfaillie et al., 1996). The aim of optimisation is to find the optimal solution in a given set of feasible solutions. This optimal can be local optimum or global optimum, if the optimum is the best solution among all the feasible solutions, this solution is called global optimum solution. The global optimum is better according to the objective function than for all x in some open interval containing this solution. In some applications, it’s difficult to identify the global best solution, an optimal solution, called local optimum is found in reasonable time, this solution is better than its entire neighbourhood. This local optimal is better according to the objective function than all x in the allowed domain. In a given problem there can be many local optimum that are not global optimum (Horst et al., 2000). The function f is used to decide that this solution is better than other solutions, f is called objective function and it serves as the criteria to determine the quality of the solution. Optimisation problems can contain only one objective function with a set of constraints, called single objective optimisation problems. A single objective function with several constraints may not adequately represent an optimisation problem, in this case we might need to represent the problem with several objective functions called multi-objectives optimisation problem, called also multi-criteria optimisation, or multi-attribute optimisation (Hwang et al., 1979). Optimisation problem can be without any objective function, (for example, design of integrated circuit layouts), the objective is to find a set of variables that satisfies the model constraints. Designer doesn’t need to optimise anything, this kind of problems known as feasibility problems.
Optimality Searching Algorithms
Searching for the optimal solution among all possible solutions of an optimisation problem is like finding solution to the maze game. The only guarantee is that at least one solution exists, but the time required to achieve this solution is up to the used strategy to find it. Suppose that we search for the path without any guidance, the search process can be in infinite time hence of the purely random search. A huge number of methods have been proposed to improve the optimal solution finding by developing new searching strategies. The optimisation method can be classified into two categories based on the relation between the problem and the method to solve this problem. The heuristics are a problem dependent methods they take in consideration the advantage of the problem to converge quickly to optimal solution, the heuristics are specific methods adapted to a given problem (Jon 1983). The second category sets is the metaheuristics which are a problem-independent methods, they are general methods to solve all optimisation problem and they do not take advantage of any specificity of the problem (Blum et al., 2003). Large numbers of metaheuristics have been proposed to solve combinatorial problems. These methods can be classified in numerous ways, the classification are not absolute, means the same propriety can be used by several algorithms in different ways. Many studies have been carried out on the metaheuristics classification. Author in (Blum et al., 2003) proposes a large classification based on number of solutions per iteration, the use of the search history, the kind the objective function and the source of inspiration, these characteristics are organised as follows: • Trajectory methods Vs. Discontinuous methods: The trajectory methods aim to find the optimal solution of an optimisation problem by exploring the possible solution from the neighbourhood of this feasible solution only. The discontinuous methods explore the solutions in a trajectory form and also can jump to solution in other region of the solution space (Betts 1998). • Population-based Vs. Single-point search: the population based optimisation methods use a set of feasible solution at each iteration, and the single-point based optimisation methods used one feasible solution and start exploring the solution space from this solution (Parpinelli et al., 2011). • Memory usage Vs. Memoryless methods: the difference between the methods that uses memory and the methods that don’t use memory is the use of the historical information (previous visited solutions) to control further amelioration of the objective function but exploring new non visited solutions (Rego et al., 2006). • Nature-inspired Vs. Non-nature inspiration: Some optimisation algorithms are based on natural and biological phenomena. This kind of algorithm imitates the behavior of biological process or swarm intelligence based methods (Yang et al., 2010). These characteristics identify the search strategy and the structure of metaheuristic algorithms. We can summarise these characteristics in two main categories: the number of solution manipulated by the algorithm and the use of the search history. In the following we describe some important meta-heuristic techniques that have been widely used for solving optimisation problems.
Genetic Algorithm Genetic
Algorithm (GA) is a bio-inspired metaheuristic algorithm developed by (Goldberg et al., 1988). GA is a stochastic optimisation algorithm imitates the natural evolution process of genomes. The GA is based on three operations, selection, crossover and mutation. These operations are applied iteratively to improve the quality of the solutions (see Figure 2.1). GA starts by generating a population of random feasible solutions (individuals), the initialisation can be made in different ways, the basic GA uses random initialisation of the start population, each solution is considered as an individual on the population. GA optimisation process is based on a set of operators, allow the algorithm to improve the intilai population in ordre o achieve the optimal solution.The optimisation process of GA is as follow: two solutions are selected among the individuals of the initial population, by one of the well-known selection techniques. This two selected solutions will be considered as two fathers, this two, later will be crossed to generate two other new solutions considered as (Children), this new solutions (Children) can be mutate according to a given mutation probability. The quality of each solution is computed with the fitness function, this function controls the evolution of the GA population by the deletion of bad and insertion of good solutions in the population. These processes are repeated until the termination criteria is achieved which can be the number of generation or if the population is stabilised. A simple description is presented in the next sections.
1.1 Field of Research |