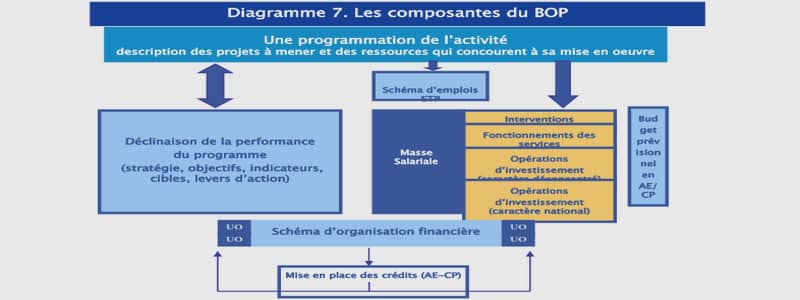
Les SAMU : un objet d’étude très hétérogène à l’échelle nationale
Afin d’illustrer et d’objectiver l’hétérogénéité des SAMU, nous avons collecté des données sur les SAMU à l’échelle nationale. Au travers de cette étude, nous faisons l’hypothèse que les SAMU peuvent être regroupés suivant des critères structurels Pour ce travail, nous n’avons pas inclus les SAMU des DOM-TOM français par manque de données les concernant. Ainsi notre étude ne sera valable que pour les départements de métropole ainsi que la Corse. Dans cette section, nous explorons les données de ces 93 SAMU afin de proposer une classification.
Les données brutes agrégées sur l’année 2018
Pour faire cette analyse, nous nous appuyons sur les données nationales pour chaque département français. La figure 2.1 présente les données utilisées classées en trois catégories différentes. Les données démographiques des départements sont issues du site de l’INSEE, les données sur les informations structurelles et les performances des SAMU proviennent de la SAE. 2 . Il est important de noter que la SAE est une base de donnée déclarative réalisée à partir de la remontée d’informations fournie par les SAMU issu de systèmes d’informations non harmonisés et non centralisés. Nous détaillons ci-dessous la liste des données et leur signification. Ces critères peuvent être répartis suivant plusieurs catégories : des critères démographiques qui traitent des caractéristiques géographiques du département, des critères structurels sur la composition du SAMU et comment il est équipé, cela correspond aux moyens de l’urgence, et des critères sur les caractéristiques de la demande de soin urgent.
Les critères démographiques
Les critères démographiques permettent de renseigner sur les grandeurs du périmètre géographique d’interventions ainsi que sur les caractéristiques de la population — Région : Ce champ correspond à la région administrative à laquelle le département est relié, cet item ne nous sert pas pour la classification à proprement parlé, mais nous permet de situer le département à l’échelle régionale. — Dept. : Ce champ correspond au nom du département. — Code : Ce champ correspond au code de numérotation du département. — Population : Ce champ renseigne le nombre d’habitants dans le département en 2018. — 75ans et + : Ce champ renseigne le pourcentage d’habitants de plus de 75 ans sur le territoire. — Superficie : Superficie du territoire exprimé en 𝑘𝑚2 . — Densité : Densité de la population du territoire en habitants / 𝑘𝑚2 .
Les critères structurels sur la composition du SAMU
L’offre de soins L’offre de soin permet de caractériser les moyens disponibles au niveau du département pour répondre aux situations d’urgences. Nous qualifions l’offre de soin par les ressources existantes et non pas les ressources engagées dans les interventions — SMUR général correspond au nombre de bases SMUR sur le département. — Antenne SMUR correspond à des bases SMUR ouvertes de manière ponctuelle (selon l’affluence touristique saisonnière par exemple). — Ambulance : le nombre d’UMR à disposition du SAMU. — Véhicule léger : le nombre de VL à disposition du SAMU. — Heures moyennes hebdomadaires des MR. — Heures moyennes hebdomadaires des ARM. — Moyens aériens : le nombre de moyens aériens de type hélicoptère. — Moyens maritimes : Pour les SAMU côtiers qui disposent d’un accès maritime. — Le nombre de Médecins Généralistes (MG). — Le nombre de MG pour 100 000 habitants.
Les caractéristiques de la réponse de soin d’urgence
La demande de soins Cette catégorie permet de renseigner les caractéristiques du besoin de la population en terme de services d’urgence. — Sorties terrestres primaires. — Sorties terrestres secondaires. — Sorties terrestres dans le cadre de transports infirmiers inter- hospitalier. — Appels présentés. — Dossiers de Régulation. — Dossiers de Régulation Médicale. — Le nombre d’appels par habitant. Le territoire Français est varié, on y trouve des zones très urbanisées ainsi que des territoires plus ruraux. Le relief est tout aussi varié avec des zones montagneuses, des littoraux, des zones qui combinent les deux, des plaines et des vallées. Notre territoire est riche et d’une grande diversité. Cette diversité pourrait avoir un impact sur la manière dont on consomme et dispense le soin d’urgence. Ainsi, nous souhaitons vérifier s’ il existe des types de SAMU qui dépendent de cette diversité. La figure 2.2 présente un extrait de cette base de données ainsi constituée et des données présentées précédemment que nous avons utilisées. Une première manière de découvrir ces données est d’utiliser une approche de type statistique descriptive afin de voir ce que l’on peut obtenir pour chacune des catégories. Le tableau 2.1 présente les statistiques obtenues sur ces critères tels que la moyenne, la déviation standard, les valeurs minimums et maximums ainsi que les différents quartiles.
Définir des groupes de SAMU sur la base des données nationales
Application du clustering hiérarchique agglomérant Afin d’aller plus loin dans la découverte de nos données que l’étude des statistiques descriptives, nous nous sommes penchés sur l’apprentissage automatique, plus connu sous le nom de Machine Learning (Mitchell, 1999). Le Machine Learning peut se définir comme un champ d’études de l’intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d’« apprendre » à partir de données. Avec cette technique on distingue deux approches principales : l’apprentissage supervisé et l’apprentissage non supervisé (Kaufman et al., 2009). Dans chacune des catégories, on retrouve plusieurs outils, plusieurs algorithmes permettant de traiter des données. L’apprentissage supervisé est intéressant lorsqu’on connaît déjà les catégories formées par nos données. L’apprentissage non supervisé est utilisé pour des données qui ne sont pas classées suivant des catégories. De ce fait, on ne dispose que des individus formés par les données et ces derniers ne sont pas regroupés suivant leur similitude. Les algorithmes d’apprentissage non supervisés ont pour objectif de former des groupes homogènes d’individus selon leurs attributs. Une fonction de distance sera utilisée pour calculer la distance entre des paires d’exemples. Une fois ces groupes formés, c’est à l’humain de donner du sens au résultat obtenu et d’identifier les motifs récurrents dans les groupes, ce qui les rassemble et ce qui les différencie. Dans notre cas, l’apprentissage non supervisé semble tout à fait adapté puisque nous avons plusieurs individus (les SAMU) avec des caractéristiques, et nous cherchons à les regrouper suivant des groupes homogènes pour voir quels sont les critères qui permettent de les rassembler. On parle alors de méthode de regroupement (clustering) (Kaufman et al., 2009). Plusieurs algorithmes sont courants au sein du clustering. Lorsqu’on connaît le nombre de groupes, on peut utiliser l’algorithme du k-mean. Or, ici nous ne savons pas a priori combien de groupes de SAMU nous allons obtenir, ainsi nous avons plutôt opté pour une approche hiérarchique qui a l’avantage de laisser le choix sur le nombre de groupes à former. Nous avons utilisé un algorithme de clustering hiérarchique agglomérant (hierarchical agglomerative clustering) (Müllner, 2011). Les systèmes de clustering agglomératif partent de la partition de l’ensemble de données en nœuds simples. Puis ces données sont fusionnées avec les données les plus proches les unes des autres afin de former un nouveau nœud. Le processus est répété jusqu’à ce qu’il n’y ait qu’un seul nœud qui comprend l’ensemble des observations. La représentation en sortie de l’algorithme est un dendrogramme par étape dont voici la définition (Müllner, 2011) : Définition. Soit un ensemble fini 𝑆0 de cardinalité 𝑁 = ‖𝑆0‖, un dendrogramme par étape est une liste de 𝑁 − 1 triplet (𝑎𝑖 , 𝑏𝑖 , 𝛿𝑖) (𝑖 = 0, …, 𝑁 − 2) tel que 𝛿𝑖 ∈ [0,∞) et 𝑎𝑖 , 𝑏𝑖 ∈ 𝑆𝑖 , où 𝑆𝑖 + 1 est récursivement défini comme 𝑆𝑖 ∖ 𝑎𝑖 , 𝑏𝑖), ∪𝑛𝑖 et 𝑛𝑖 ∈/ 𝑆 ∖ 𝑎𝑖 , 𝑏𝑖 , un repère pour un nouveau nœud. Détaillons cette définition, l’ensemble 𝑆0 correspond à l’ensemble des points étudiés (dans notre cas, les 96 départements français métropolitains). À chaque étape, 𝑛𝑖 correspondant au nouveau nœud formé par le regroupement des nœuds 𝑎𝑖 et 𝑏𝑖 espacé de la distance 𝛿𝑖 . Cela revient à dire que deux départements sont proches, car la distance entre leurs vecteurs de composantes est proche. L’algorithme contient 𝑁 − 1 étapes, car lors de la dernière étape on obtient un nœud qui regroupe les 𝑁 nœuds initiaux (les 96 départements). Pour expliquer le fonctionnement du clustering hiérarchique, nous proposons un exemple abstrait présenté dans la figure 2.3. Afin d’être capable de représenter la distance graphiquement entre les individus, cet exemple n’utilise que deux critères. Nous avons 8 individus définis par ces deux critères, ce qui nous permet de faire une représentation graphique comme sur la partie gauche de la figure. La première étape de l’algorithme considère chaque individu comme un groupe. La deuxième étape va chercher le plus proche voisin de chaque point, de manière à regrouper les points deux à deux en minimisant leur distance euclidienne. On obtient alors trois doublets (4, 5),(1, 2),(6, 8) et deux monoïdes (3) et (7). La troisième étape va essayer de rassembler ces groupes deux à deux, toujours en cherchant à minimiser leur distance. On obtient alors 3 groupes qui rassemblent les doublets précédents avec le monoïde le plus proche [7,(6, 8), (︀ 3,(4, 5),(1, 2))︀ ]. L’étape suivante rassemble ces trois groupes de manière à obtenir deux groupes formés du doublet (1, 2) d’un côté et [ (︀ 7,(6, 8))︀ , (︀ 3,(4, 5))︀ ] de l’autre. Enfin la dernière étape forme un seul groupe contenant tous les individus. Si on présente les résultats sous la forme d’un dendrogramme comme sur la partie droite de la figure 2.3 on obtient un arbre avec quatre niveaux. Chaque niveau présente un nombre de groupes différents qui contient plus ou moins d’individus. C’est donc au décideur de choisir le nombre de groupes le plus pertinent dans son cas d’étude en fonction des critères étudiés.
Les verrous scientifiques
L’état de l’art réalisé dans la section 1 démontre que l’emphase a été principalement mise sur la partie aval de l’organisation alors même que des problèmes critiques ont été démontrés sur la partie amont. Il y a donc un manque évident dans la littérature de solutions concrètes permettant d’adresser la problématique métier discutée précédemment. Des verrous scientifiques doivent donc être levés pour être en mesure d’évaluer l’impact des types d’organisation sur les performances des centres d’appels. Il n’est pas encore aisé aujourd’hui de statuer de manière objective sur la prédominance d’un modèle par rapport à un autre. Il est donc nécessaire d’apporter des éclairages sur l’effet des organisations sur les indicateurs de performance des centres d’appels. Afin d’être en mesure d’évaluer ces organisations sur la base de faits objectivés, il est nécessaire d’aborder prioritairement la question de l’accessibilité des données ; ce qui, aujourd’hui dans le domaine de la santé, n’est pas évident. En effet, les systèmes d’information en santé sont souvent limités et pas toujours à jour. Cela rend l’accès à la donnée complexe. Avec la modernisation récente des systèmes de santé et l’accès aux données qui l’accompagne, de nouvelles opportunités apparaissent. L’analyse des données doit permettre de mieux comprendre le fonctionnement des organisations de santé d’une part, et les résultats de ces analyses doivent permettent de créer de la connaissance, de modéliser les systèmes de santé pour les challenger, les éprouver et enfin les améliorer d’autre part. Le fait d’être capable de reproduire le comportement des centres d’appels à l’aide de doubles numériques par exemple devrait permettre de faciliter de telles démarches de progrès permanent. Ce genre d’environnement virtuel est en effet un atout majeur dans le développement de nouvelles manières de fonctionner car il ne présente aucun risque pour les usagers, au contraire d’une expérimentation terrain. La littérature met par ailleurs en évidence que le niveau de détail dans la modélisation des centres d’appels d’urgence se limite le plus souvent à la prise en compte des appels entrants uniquement. Les appels sortants ou les appels internes ne sont que rarement pris en compte, ce qui peut influer sur la précision des modèles par rapport au monde réel. L’intégration de nouveaux outils d’analyse, d’optimisation et de pilotage des organisations des systèmes de gestion des appels d’urgence apparaît donc comme une évidence qu’il convient d’accompagner. Le présent travail de recherche ambitionne d’apporter sa contribution à cet objectif.