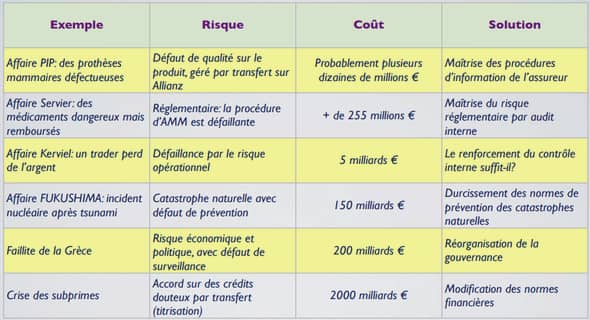
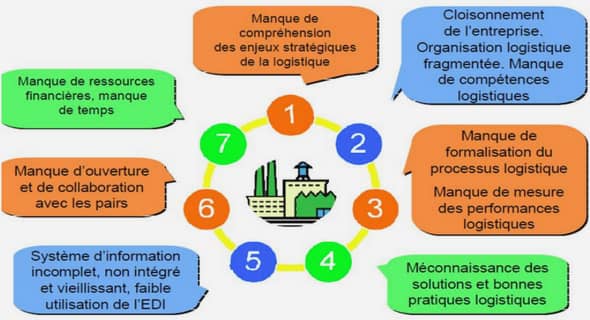
Choix discrets expérimentaux- rappels méthodologiques
Dans le cadre des choix discrets expérimentaux, les individus sont confrontés à un ensemble de choix réalisables (et hypothétiques) concernant par exemple des moyens de transport (comme le bus ou le métro) et qui seraient différenciés par les attributs ou caractéristiques qui caractérisent chaque choix comme les prix et les durées du trajet et/ ou encore par les niveaux de confort. Généralement, les choix sont proposés aux individus de manière à les mettre en situation où ils devront inévitablement faire des compromis. L’intérêt de l’approche se situe d’ailleurs dans cette capacité à mettre en avant les compromis qui pourraient exister entre différents attributs caractérisant l’ensemble des choix. Faisant partie de la méthode des préférences exprimées, la méthode des choix discrets expérimentaux est une méthode d’évaluation fondée sur la nouvelle théorie de la consommation de Lancaster, qui stipule que les préférences pour un bien dépendent non pas de la consommation directe de ce bien mais plutôt indirectement des caractéristiques que ce bien possède ; et sur la théorie de l’utilité aléatoire (Hanley et Mourato, 2001). Le cadre théorique de l’utilité aléatoire décompose la fonction d’utilité indirecte de l’individu en deux composants : un élément observable qu’on assume comme étant une fonction linéaire des caractéristiques des différentes alternatives, et d’un élément aléatoire. La fonction d’utilité indirecte Uni d’un individu n en choisissant une alternative i, est donnée par l’équation (1) : Uni = Vni + Ɛni = ß’ Xni + Ɛni (1) Vni est la composante observable de l’utilité et Ɛni représente les termes aléatoires (tous les facteurs inobservables qui influencent les choix de l’individu), qui sont assumés comme indépendamment et identiquement distribués en valeurs extrêmes (IID). Xni sont les vecteurs des différents attributs –spécifiques de l’alternative i pour l’individu n, tandis que ß est le vecteur des ‘poids’ de l’utilité.
L’hypothèse que les termes aléatoires soient indépendamment et identiquement distribués en valeurs extrêmes (IID) nous permet d’exprimer l’équation (2) en termes de distribution logistique (Hanley et Mourato, 2001). Ainsi, on aura : Pr [(Uni > Unj) ∀ i ≠ j] = exp (µVni) / ∑g exp (µVng) (3) Où le terme µ désigne le paramètre d’échelle, qui est inversement lié à la variance des termes aléatoires (Swait et Louvière, 1993), et g représente l’ensemble des alternatives restantes disponibles pour l’individu n. Dans cette spécification de choix probabilistique connue sous le nom de modèle logit conditionnel (CLM)19, on ne peut pas identifier séparément le paramètre d’échelle µ en travaillant sur un seul ensemble de données, c’est pourquoi on assume généralement que celui-ci est égal à l’unité. En conséquence, la sélection des choix doit se conformer à la règle d’indépendance des alternatives non pertinentes (IIA- Independence from Irrelevant Alternatives), qui spécifie que la probabilité relative de deux alternatives sélectionnées ne sera pas affectée par le rajout ou la suppression d’une alternative (Hanley et Mourato, 2001).
Cependant, la validité de la règle IIA est rarement rencontrée dans la pratique, étant donné que celle-ci impose une forte restriction sur les comportements de choix. Ainsi, l’application du CLM doit toujours être suivie d’un test qui va vérifier la validité de l’IIA comme celui de Hausman (Hausman et McFadden, 1984). Si la restriction imposée par l’IIA est violée, alors d’autres modèles comme le modèle logit mixte devraient être utilisés. Le principal avantage du modèle logit mixte comparé au CLM réside dans le fait qu’au lieu de fixer les coefficients des estimateurs des variables observées dans la spécification de la fonction d’utilité, on fait varier ces coefficients aléatoirement dans la population. La variance de ß (voir équation 1) dans ce cas va provoquer des corrélations entre les différentes alternatives. En effet, pour chaque individu, ß va devenir la somme de la moyenne b de la population et de l’écart-type σn, qui représente la variation des préférences individuelles relative à la préférence moyenne. L’équation (1) précédente est réécrite comme suit (Train, 1998) : Uni = b’ Xni + σn’ Xni + Ɛni Dans cette expression, à cause de la composante inobservable de la fonction d’utilité, σn’ Xni + Ɛni est corrélée sur les différentes alternatives (à cause de σn), et le modèle logit mixte n’est plus restreint par la règle de l‘IIA. La probabilité qu’un individu n va choisir l’alternative sera alors donnée par (Train, 1988) : Prni = ∫ Lni (ß) f (ß) dß (5) Où Lni (ß) = exp (β’Xni) / ∑j exp (β’Xnj) à cause de la propriété des termes aléatoires qui sont indépendamment et identiquement distribués, et f(ß) représente la fonction de densité des variations des préférences parmi la population.
Etant donné qu’on cherche à comparer les préférences des citoyens d’un pays en voie de développement à celles d’un pays développé, on a conservé les mêmes paramètres (nombre d’alternatives, nombre d’attributs, et nombre de niveaux pour chaque attribut) utilisés par Markova-Nenova et Wätzold (2017) pour concevoir leur expérimentation sur les choix réalisés à Cottbus, en Allemagne, pour la conception de notre expérimentation. Ainsi, pareillement que les choix discrets expérimentaux de Cottbus, le scénario concerne le lancement d’un projet de lever de fonds qui aurait pour but de conserver les forêts épineuses du plateau Mahafaly, actuellement menacées par les pratiques des cultures sur brûlis. Le projet cherche à mettre en place un fonds de conservation qui serait financé par des donations individuelles, duquel la population locale du plateau Mahafaly pourrait recevoir des compensations monétaires pour l’abandon des pratiques de cultures sur brûlis.