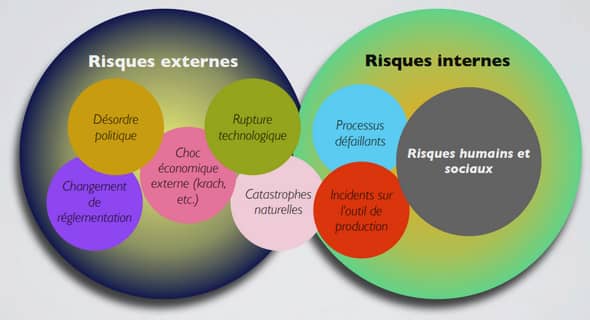
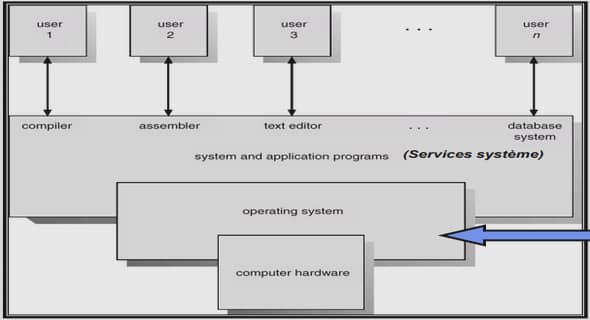
ETUDE DES EXPRESSIONS FIGEES DU FRANÇAIS
Recherches sur le figement linguistique: études portant sur d‟autres langues en dehors du français
D‟emblée, nous pouvons dire que bien des chercheurs, des précurseurs se sont intéressés, à divers titres, au phénomène du figement qui nous préoccupe aujourd‟hui. Voulant continuer à défricher ce domaine du figement, nous comptons partir d‟abord des travaux de nos devanciers sur lesquels nous nous appuierons bien souvent pour essayer d‟aller de l‟avant. Ainsi donc, contrairement aux chercheurs en langue française qui se sont intéressés aux expressions figées, peut-on dire de manière tardive, les chercheurs en langue anglaise se sont très tôt imposés dans ce domaine du figement qu‟ils appellent souvent : « phraseology » ou « idiomaticity ». Nous allons prendre, ici, pour modèle les recherches en langue anglaise bien qu‟il faut tenir en compte le fait que d‟autres langues aussi connaissent le phénomène et s‟intéressent à lui. Ce penchant que nous avons pour l‟anglais n‟est pas fortuit. C‟est juste pour montrer que nous y avons plus de matière (données collectées, documents etc.) et nous maîtrisons relativement cette langue mieux que les autres que nous aurons à évoquer aussi. Ainsi, parmi les différentes recherches auxquelles nous nous intéresserons, dans les deux sections qui suivent, nous aurons, entre autres, des thèses et des ouvrages mais aussi des articles et des dictionnaires dits de spécialité. 24 Pour étayer certains points dans cette section, nous aurons recours à l‟anglais le plus souvent. Et une fois qu‟une citation sera donnée, dans certains cas, nous pourrons apporter, si nécessaire, une explication pour éclairer ce que nous avons cité ; une manière pour nous d‟éviter une traduction maladroite qui dénaturerait l‟idée donnée dans la langue source.
A propos des études antérieures: thèses et ouvrages
Dans les analyses linguistiques, « les exemples en langues étrangères fournissent une ouverture indispensable à une linguistique trop centrée sur le français. »25 « Anyone claiming that English might be exceptionally idiomatic should also clarify what they understand by the term idiomatic. As Grant and Bauer (2004) point out, idiomaticity can be defined in two ways: 1. Narrowly, it pertains to the relatively high density of „idioms‟, i.e. the use of the sort of standardized expressions that are typically included in „idiom dictionaries‟. 2. Broadly, it refers to „native-like selection‟ in the language (Pawley & Syder, 1983) Ŕ that is, to the whole of a language‟s stock of standardized phrases, which includes idioms, but also various other kinds of multiword units such as strong collocations, proverbs and formulae in general.» 26 I. Thèse : Nous ouvrons cette rubrique en parlant d‟abord de Larsson Aas qui est l‟un de ces chercheurs qui s‟intéressent au figement de la langue. Son travail (une thèse27) est basé sur un corpus oral recueilli en partie auprès d‟apprenants suédois et norvégiens. Ses recherches s‟intéressent à ce que certains appellent communément les FS28 en langue anglaise. 25 Guelpa, P. (1997), Introduction à lřanalyse linguistique, Paris, Armand Colin/Masson, p .7 26 Stengers, H. et al. (2007), « The effectiveness of a phrase learning approach on fluency, complexity and accuracy in and beyond the EFL classroom » C‟est l‟abréviation de Formulaic Sequences ou Formulaic speech. On peut dire également Formulaic tout court et cette désignation correspond en français à ce qu‟on appelle les séquences préfabriquées (S.P) ou encore chez certains chercheurs les Routines conversationnelles (formules qui permettent de faciliter le discours et qui reviennent souvent dans une conversation). On peut avoir comme exemples : „‟s‟il vous plait‟‟, „‟ je vous en prie‟‟, „‟il n‟y a pas de quoi‟‟ etc. 23 Dans cette étude, l‟objectif du chercheur est de voir comment identifier et décrire les expressions figées récurrentes dans le discours de ses cibles; c‟est comme il le dit lui même: « It further (this project) considers how we may best identify and describe recurring language patterns and their functions in naturally occurring speech »29 Structurée en six étapes, la démonstration de Aas présente, elle, deux étapes fondamentales que sont les quatrième et cinquième respectivement intitulées: „„Recurrent word-combinationřř et „Ř Formulaic sequences in advanced learner languageřř. Ces deux étapes évoquées constituent pratiquement le centre de l‟étude et lui ont permis d‟aboutir à une conclusion qui donne les forces et les limites du travail ; le début du travail étant consacré à l‟élaboration d‟un tour d‟horizon sur les recherches antérieures sur le thème et sur la revue du matériel (corpus) et des méthodes utilisées pour réaliser l‟étude. S‟agissant ici de la première étape du travail de Larsson qui est en l‟occurrence l‟introduction, on peut dire que ce qu‟il faut retenir là est le passage suivant: « This study aims to shed light on the inventory of recurrent word-combinations in native and non-native English speech, by means of a contrastive approach employing corpus data as its main source of material. » 30 Il signale en fait que son étude a pour ambition d‟apporter un éclairage sur les formulaic (tels que: You know/ tu sais ; in spite of/ en dépit de ; You see/tu vois ; of course/bien sûr etc.) utilisés chez les usagers, locuteurs natifs ou nonnatifs de l‟anglais. Le matériel sur lequel s‟est basé le chercheur est un doublecorpus : D‟abord pour les locuteurs natifs : “The primary source of material for this study is one native speaker corpus, the Louvain Corpus of Native English Conversation (LOCNEC)” Et pour les locuteurs non-natifs (deux sous-corpus): “Two subcorpora of the non-native speaker corpus LINDSEI (the Louvain International Database of Spoken English Interlanguage), which contain speech produced by Swedish and Norwegian advanced learners of English.”31 29 Ass, L. (2011), Ibid. p. I (Abstract) 30 Ass, L. (2011), Ibid. p. 2 31 Ass, L. (2011), Ibid. p. 1 24 Ce qu‟il convient également de noter est que l‟étude de Aas se présente à la fois comme étant théorique et acquisitionnelle. L‟aspect théorique se voit dans la mesure où il fait (surtout dans la deuxième étape, celle qui suit l‟introduction) un état sur des recherches précédentes (c‟est l‟étape dénommée „theorical background‟‟). L‟aspect acquisitionnel vient bien après et fait voir comment les étudiants, apprenants auxquels il s‟intéresse, utilisent les expressions qu‟il appelle „„recurrent word-combinations‟‟. La conclusion de l‟étude constitue la dernière étape et elle met l‟accent sur les forces et limites de la démonstration comme il l‟indique lui-même dans le travail. Il rajoute, en outre, des propositions sur des applications qu‟on pourrait faire de ses résultats et des pistes pour des études futures. En témoignent les lignes qui suivent: « The study shows some of the strengths and weaknesses of employing a hypothesis finding, corpus-driven approach to the identification and description of formulaic language. It confirms the pervasiveness of recurrent language in both native- and non native speech, and presents quantitative results showing how particular word combinations are under- and overrepresented in the learner material as compared to the native speaker corpus. »32 C‟est pour dire donc ici que l‟étude n‟a pas eu que des aspects positifs mais elle a également rencontré des obstacles dans l‟identification et la description du phénomène (formulaic language). L‟étude confirme, par ailleurs, la récurrence du langage préfabriqué dans le discours des enquêtés (apprenants). Et cette récurrence, en effet, des expressions figées se traduit bien dans les résultats par deux pôles extrêmes qui sont celui de l‟usage très abondant et celui de l‟usage très faible. Ainsi, retrouve Ŕt- on, dans l‟étude de Aas, par l‟intermédiaire des colonnes qui suivent ce qui en est du suremploi et du sous-emploi de certaines de ces expressions récurrentes. Nous avons donc: Overuse : Underuse: I think (itřs/so) I mean (I) I donřt (know/think)/I dunno you know I guess (so) thatřs right (or) something (like that) (that) sort of (like/thing) (and) stuff (like that) (a) bit of of course (and) things (like that) kind of Table 5.1: Over- and underused word-combinations in LINDSEI-SW as compared to LOCNEC.La tendance générale des résultats de l‟étude de Aas montre, peut- on dire, qu‟une expression se dégage du lot à savoir la combinaison „„I thinkřř comme on le retrouve ici : ŖIt seems that I think is a dynamic and versatile formulaic sequence which is used to perform a number of functions, and that this picture is more striking in learner speech than in the language of native speakers.ŗ 34 Ce que nous pouvons toutefois retenir de cette l‟étude en anglais est qu‟elle a tenté de toucher à divers horizons en s‟intéressant à des aspects tels que celui de l‟usage des combinaisons étudiées (formulaic) à l‟oral, celui de l‟acquisition, et ce, en s‟appuyant sur des cibles, des locuteurs natifs et non natifs. II. Ouvrages : 1/ Hudson: Au-delà de l‟étude de Aas, nous pouvons également signaler celle de Hudson. D‟emblée, on peut dire que l‟ouvrage35 de ce chercheur s‟intéresse au figement comme il le dit dans les premiers mots de son introduction: “The subject of this book is fixednessŗ 36 . La matière à laquelle il fait allusion, ici, est celle dont il fait référence dans le passage suivant : ŖSome prototypical examples of fixed expressions are: above board, after all, all right, as if, at all, at the same time, bark up the wrong tree, bow and arrow, by hand, by the way, comings and goings, fed up, food for thought, foot the bill, force of habit, give up („resign‟), hot dog, I mean, in case, in fact, in spite of, old hat, or something, red herring, rough and ready, sort of, take off („imitate‟), you knowŗ 37 Avec ce que nous avons là, on est déjà édifié sur l‟orientation du travail du chercheur sur le figement. Basé sur un corpus oral composé de deux grandes branches (LLC, CANCODE) 38 on peut retenir que le travail est également divisé en trois grandes parties comme il l‟indique: Hudson, J. (1998), Ibidem 38 LLC: The LondonŔLund Corpus of Spoken English; CANCODE: The Cambridge and Nottingham Corpus of Discourse in English (British English speech), that corpus is a part of the Cambridge International Corpus (CIC), (spoken British English). 26 “The book is divided into three distinct parts reflecting three very different perspectives on fixedness.ŗ 39 L‟introduction qui ouvre ce travail jette les bases de l‟étude en donnant une idée des problèmes qu‟on peut rencontrer dans ce domaine du figement. Pour montrer, par exemple, que le phénomène est difficile à cerner, il avance qu‟il ne suffit pas seulement pour un apprenant de connaitre le sens des mots de la langue mais qu‟il faut aussi connaitre le sens de certaines combinaisons particulières. C‟est ce que nous retrouvons ici: ŖFor a non-native speaker of English to achieve native-like fluency it is not sufficient to learn the meanings of the words of the language and to combine them according to the rule system described in grammars and textbooks. There is always the problem of idiomaticity, or Řsounding rightř, which involves making choices beyond those offered by the lexicon and the grammar.ŗ 40 Le chercheur ajoute dans l‟introduction toujours l‟objectif d‟une manière générale qu‟il se fixe : étudier les expressions figées sur un plan „„théorique‟‟ et sur un plan „„appliqué‟‟. Il présente, par ailleurs, quelques uns de ses objectifs spécifiques à savoir: a/ Catégoriser les différents types d‟expressions existants en anglais b/ Identifier les critères de figement des expressions en se basant sur son corpus c/ Chercher à voir comment se développe le phénomène, son évolution et donner des perspectives. Pour ce qui est de la première partie intitulée „„Realizationřř, elle s‟intéresse dans une certaine mesure aux études antérieures sur le phénomène, à différents types d‟expressions et en particulier aux combinaisons où l‟on retrouve le mot „„all‟‟ (for all time, with all respect, all round, all over, after all, above all). La deuxième partie, „„Conceptualizationřř, quant à elle revient sur le sens, la compréhension ou plutôt l‟interprétation des expressions figées. Il s‟agit ici de montrer d‟une certaine manière la difficulté qu‟on rencontre à déterminer le sens d‟une expression et de ne pas se fier toujours aux mots qui constituent l‟expression (se méfier du sens littéral de certains mots, des métaphores, des polysémies). La dernière partie du travail, „„Discourseřř, s‟intéresse à l‟évolution du phénomène „„fixednessřř et à son impact sur le langage. Ici, certains points sont mis en avant à savoir: l‟économie linguistique, les fortes récurrences dans le discours etc. Les résultats de l‟étude de Hudson montrent dans l‟ensemble qu‟il importe de faire une classification bien solide des expressions figées comme les mots de la langue classés en catégories ou en parties du discours. Il ajoute qu‟il y a des avantages du point de vue théorique comme appliqué à procéder ainsi dans la mesure où cela faciliterait d‟une part l‟apprentissage chez les apprenants de la langue (ici il s‟agit de l‟anglais) et d‟autre part cela permettrait de mieux développer l‟usage des dictionnaires électroniques. Pour appuyer ces propos, nous nous référons aux passages suivants : A / ŖThat there might be practical advantages to be gained from classifying fixed expressions as words, using the basic wordclass system of English: noun, verb, adjective, adverb, preposition, etc. There are both applied and theoretical advantages of such a classification. Learners need to know not only the semantics, pragmatics and phonology of linguistic units, but also their grammatical roles (…) Natural language processing would also benefit from an exhaustive catalogue of fixed expressions, categorized according to their grammatical role, in the form of electronic dictionaries.ŗ 41 B / ŖThat the evolution of fixed expressions is an important, non-arbitrary process of language change; that a cline of development can be described: ad hoc expression > fixed expression > word; and that this development alternates with grammaticalization.
Introduction générale |