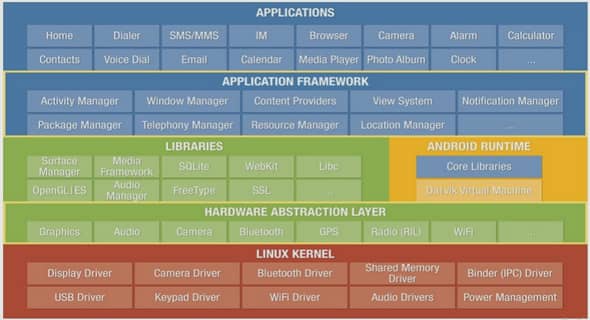
L’apprentissage par renforcement implique de l’effort mental
L’apprentissage par renforcement est un mécanisme relativement universel. Il consiste dans l’idée simple qu’un évènement immédiatement suivi d’une récompense sera associé à l’obtention de cette récompense et qu’un évènement immédiatement suivi d’une punition sera associé au fait de subir cette punition. L’universalité de ce mode d’apprentissage dans le règne animal, des pigeons aux Primates, explique que ce mode d’apprentissage soit rattaché à des structures « primaires » qu’on retrouve chez les plupart des Vertébrés, comme les ganglions de la base et les neurones dopaminergiques (Averbeck and Costa, 2017; Grillner and Robertson, 2016; Mannella et al., 2013). De ce fait, on pourrait aussi s’attendre à ce que ce mode d’apprentissage, ayant prouvé son efficacité au fil de l’évolution, soit invariant à travers la plupart des espèces chez lesquelles on peut l’observer.
À l’inverse, la capacité d’exercer du contrôle cognitif est restreinte à quelques espèces. Cette capacité consiste plus ou moins à être capable d’établir une stratégie d’actions, notamment dans des situations où des distractions ou des automatismes doivent être inhibés en vue d’atteindre un but désiré. Le contrôle cognitif fait partie des capacités qui ont été massivement développées chez les Primates, et l’homme en particulier, grâce à l’expansion du cortex préfrontal (Carlén, 2017). L’apprentissage par renforcement, dans sa version la plus simple, sans changement dynamique des probabilités associées à chaque évènement, peut être vu comme un processus automatique d’apprentissage par essai-erreur où les valeurs associées à une action donnée sont automatiquement mises à jour en fonction des feedbacks associés à chaque action. De ce fait, l’apprentissage par renforcement ne nécessiterait pas l’implémentation de contrôle cognitif. D’un autre côté, certaines versions de l’apprentissage par renforcement partent du principe que, dans le cadre d’une situation nouvelle ou lorsque l’incertitude est élevée, l’apprentissage par renforcement va de pair avec l’allocation de ressources mentales, jusqu’à ce que, à force de répétitions, le processus devienne éventuellement automatisé. John M. Pearce et Geoffrey Hall, dans le cadre du conditionnement classique, proposent par exemple que, tant qu’un stimulus n’est pas complètement prédictif, il implique l’utilisation d’un processeur cognitif qui permette de comparer les options à disposition et de délibérer (Pearce and Hall, 1980).
Participants
Dans cette étude, nous avons utilisé une tâche d’apprentissage par renforcement requérant des participants d’apprendre, par essai-erreur, à identifier les symboles leur permettant de maximiser leurs gains et de minimiser leurs pertes. Nous voulions voir si cette tâche impliquait, ou non, l’activité de structures liées à l’allocation de contrôle cognitif. L’apprentissage par renforcement, dans un cas simple qui n’incluait pas de changement dynamique des probabilités, pourrait avoir lieu de manière automatique sans nécessiter l’activité de structures liées à l’allocation de contrôle cognitif. Nous nous attendrions alors que les structures du réseau des valeurs, comme le vmPFC identifié dans notre première étude, permettent de représenter la valeur subjective associée aux différents symboles de la tâche et de la mettre automatiquement à jour. L’activité du dmPFC, que nous avons liée à l’effort implémenté au cours de la délibération dans une tâche impliquant une prise de décision (voir Figure 27), pourrait ne pas être impliqué dans cette tâche si elle se fait de manière automatique. A l’inverse, si cette tâche implique un effort au moment où les participants délibèrent, la tâche pourrait impliquer l’activité du dmPFC. Comme dans notre première étude, nous avons utilisé le temps de délibération comme un reflet des ressources éventuellement engagées au cours de la délibération. Nous avons ensuite regardé quels étaient les corrélats cérébraux de ce temps de délibération pour voir si le dmPFC était ou non impliqué au moment de la délibération suggérant que la tâche impliquait un certain effort mental.
Analyse comportementale
Nous avons modélisé le comportement de chaque individu séparément en utilisant un modèle de « Q-learning » standard (Watkins and Dayan, 1992) à l’aide de la VBA_toolbox (Daunizeau et al., 2014). Le modèle a été inversé en utilisant l’approche variationnelle bayésienne avec une approximation de Laplace. Ce modèle dit de « Q-learning » est utilisé de longue date pour modéliser l’apprentissage par renforcement et rend bien compte des choix opérés par les participants dans des tâches de ce type (FitzGerald et al., 2012; Palminteri et al., 2009; Pessiglione et al., 2006). Le principe du modèle est que chaque option de chaque paire est associée à un état caché, une valeur Q, et que cet état évolue au fur et à mesure de la tâche en fonction de la séquence de choix et de feedbacks. Ces états cachés représentent la récompense (ou la punition) attendue du fait de sélectionner l’option en question. Toutes les valeurs Q initiales ont été définies avec une valeur de zéro. Nous partions ainsi du principe que comme les participants ne savaient pas quelle est la valeur associée à chaque option au début de chaque session, ils démarraient avec une valeur attendue nulle pour chaque option. Par la suite, la valeur associée à chaque option évolue, au sein d’une fonction d’évolution, selon la formule : Nous avons utilisé les mêmes paramètres α et β pour les symboles associés aux gains et les symboles associés aux pertes. Nous avons aussi utilisé les mêmes paramètres à travers les 3 sessions d’un individu donné. Le taux d’apprentissage α permet de modéliser le fait que chaque individu pourrait accorder un poids différent aux feedbacks obtenus. La VBA_toolbox permet de trouver, pour un participant donné, le set de paramètres α et β qui maximise l’énergie libre du modèle selon l’approche variationnelle bayésienne.