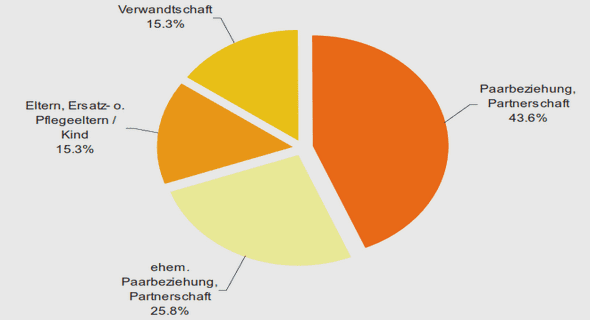
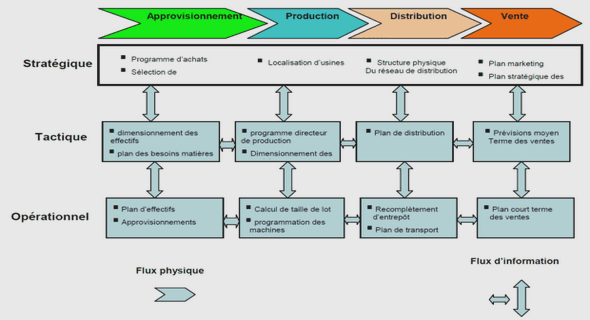
TACHE COUPLEE INVENTIVE ET CRITERES DE PERFORMANCE
PRESENTATION DU MODELE GENERAL
REPRESENTATION PAR DES ETATS ET DES ACTIONS
Nous allons supposer un ensemble E = {e1, e2, …} qui représente l’ensemble des états possibles du monde. Dans ce modèle, il est toujours possible de transiter de n’importe quel état ei du monde vers un état ej par l’application d’une action ai,j. Pour simplifier l’explication, nous utiliserons un indice unique pour énumérer les actions. L’ensemble des actions sera alors noté A = {a1, a2, …}. Il est à noter qu’une action peut être applicable ou non dans un état donné. La structure < E, A > possède une structure de graphe orienté. Dans ce graphe, un état ei peut être relié à un état ej (mais pas nécessairement) suivant l’application d’une action. Réciproquement, l’état ej peut être relié au même état ei par une autre action. Figure 8. Illustration de la structure du graphe < E, A> L’exécution d’une tâche est représentée comme la transition d’un état initial einitial vers un nouvel état efinal désiré. Tout problème peut être modélisé par un triplet (einitial, efinal, test(ej, efinal)) tel que : einitial représente l’état du monde initial tel qu’il peut être observé ; efinal représente l’état du monde espéré que l’on cherche à atteindre ; 144 test(ej, efinal) est une fonction qui permet de vérifier si tout état ej est égal à l’état efinal recherché. Le but de celui qui résout le problème va être de trouver la séquence d’action ai , ai+1, …, aj tel que chaque ak de la séquence soit applicable à l’état du monde qui résulte de l’application de l’action précédente ak−1. En effet, nous avons vu que certains états ne sont pas reliés directement les uns aux autres par une action et la transition nécessite de passer par des états intermédiaires. Dans notre illustration (figure 8), le passage de l’état e4 à l’état e2 nécessite de transiter par l’état intermédiaire e3. L’exécution d’une tâche comme une séquence d’actions peut être vue différemment suivant le contexte d’application : cela peut être une suite d’instructions informatique, un algorithme, une fonction, une méthode ou bien un plan d’action.
ILLUSTRATION AVEC LE LABYRINTHE
Prenons le cas classique d’un labyrinthe dont l’objectif est de trouver la sortie. Les états ici sont représentés par la position discrète sur le tableau de la figure 9. Par exemple le point de départ, symbolisé par le point gris, est à la position (3 ;2) tandis que la sortie en orange est au point (8 ;8). Il existe quatre actions élémentaires qui peuvent être appliquées pour changer l’état du monde : monter (ce qui correspond au mouvement monter (0 ;1) ; descendre (0 ;-1) ; aller à gauche (-1 ;0) ; aller à droite (1 ;0)). A chaque action, l’exécutant teste sa position par rapport à la sortie grâce à la fonction test. Si les deux sont différentes, alors l’exécutant appliquera une nouvelle séquence d’action jusqu’à arriver à la position finale. Nous avons représenté sur la figure une séquence d’actions qui permet de passer de l’état initial (la position (3 ;2)) à la position finale représenté par la porte de sortie. Cette séquence n’est pas la seule possible entre l’état initial et l’état final.
LE COUT DE L’EXPLORATION VS LE COUT D’UNE SOLUTION
Dans notre exemple simple du labyrinthe, l’espace de tous les états possibles est représentable entièrement. Or, ce n’est pas toujours le cas dans un processus de résolution de problèmes, et l’exécutant doit souvent explorer plusieurs combinaisons d’actions avant d’en trouver une qui mène à l’état désiré. En fait, plus la taille de l’espace d’actions augmente, plus il y a de combinaisons possibles à générer et donc à tester. En terme pratique, cela engendre des coûts liés à l’exploration. Par exemple, s’il s’agit d’une résolution algorithmique, le nombre d’opérations possibles à séquencer peut rapidement devenir très grand et donc augmenter d’autant le nombre de combinaisons d’opérations possibles. En parallèle de ces coûts liés à l’exploration, il existe également le coût de la mise en œuvre d’une solution (ou séquence d’actions). En effet, les actions à appliquer peuvent avoir des coûts associés. Cela veut dire que non seulement l’exécutant doit trouver une solution, mais il doit également faire en sorte que le coût de cette solution soit le minimum possible ou qu’il reste en dessous d’un certain budget. Cette fonction de coût peut simplement être le temps passé à réaliser une séquence d’action, ou bien être multicritères : par exemple une combinaison entre le coût monétaire et le temps passé. Remarquons que lorsque la fonction de coût est connue, elle est utilisée pour guider l’exploration : souvent, le processus d’exploration va privilégier les directions qui vont baisser le coût global.
LE COUT DANS LE CALCUL DE CORRELATION
Pour illustrer ces notions de coûts, prenons l’exemple du calcul de l’écart type de la variable X par un ordinateur. Un estimateur du coefficient de corrélation est donné par : �! = ! ! (�! − �) ! ! !!! avec � = ! ! �! ! !!! ; Pour effectuer le calcul numérique, nous proposons deux séquences d’actions différentes. La première consiste à calculer chacun des termes de l’équation indépendamment les uns des autres, c’est-à-dire le carré de la différence pour chaque terme entre lui-même et la moyenne �. Pour chaque terme, l’ordinateur devra calculer à chaque itération cette moyenne et la supprimer de sa mémoire vive. Ainsi la moyenne sera calculée N fois, N étant le nombre de termes pour la variable X. La deuxième méthode consiste à calculer d’abord la moyenne, la conserver dans la mémoire vive de l’ordinateur, puis calculer la différence entre chaque terme avec la moyenne sans avoir besoin de recalculer la moyenne à chaque fois. La différence majeure entre les deux méthodes peut se quantifier en terme de temps de calcul sur l’ordinateur : il y a N-1 actions supplémentaires dans la première méthode, sans que cela modifie le résultat final obtenu. En fait, l’ordinateur calculera à chaque fois la moyenne des termes, au lieu de ne la calculer qu’une seule et unique fois.
REMARQUES SUR LE MODELE
Représentation des états
La première remarque de fond à propos de ce formalisme concerne simplement la notion « d’état ». En fait, dire qu’on peut avoir des descriptions univoques et claires d’un « état » de la nature du monde est une hypothèse fondamentale. Or, elle laisse en suspens un certain nombre de questions : qu’est-ce qu’un état? Peut-on le représenter ou peut-il même être connu? Cela ne dépendrait-il pas des capacités d’une entité cognitive? Ces questions sont difficiles à trancher sur le plan philosophique, épistémologique et cognitif et font débat depuis l’introduction de ce modèle, dont les limites ont été discutées sous plus d’un angle (e.g. Dummett, 2000; Harman, 2002; Shapiro, 1996; Simon, 1973). En pratique, un état est souvent présenté comme un ensemble de relations �!, �!, … ∈ � qui sont vraies dans cet état. L’ensemble R des relations entre les objets suppose l’existence d’un langage qui permet de décrire le monde, par exemple en utilisant la logique de premier ordre. Ces relations décrivent les états et les relations qui s’appliquent à un domaine d’objet D. Une relation peut concerner un objet seul ou un groupe d’objets. Par exemple l’objet « pomme » est associé au prédicat « rouge » qui lui attribue une couleur, tandis que cette même pomme est également reliée à une « table » par la relation « sur » qui permet de dire que « la pomme est sur la table ». Par la suite, nous supposerons l’existence d’un langage ou d’une ontologie capable de décrire les différents objets que l’on observe suivant l’état décrit.
Complexité et capacité de calcul
Sur le plan informatique, les limites du modèle sont d’un autre ordre et se réfèrent à la fois à la complexité du problème étudié ainsi qu’à la capacité à bien exécuter les actions. Quand le problème concerne un ensemble restreint d’objets et de relations simples, il est possible de se représenter l’état du monde tel qu’il est. On suppose, par exemple, que l’espace d’état est fixe et connu au départ. Cela signifie que l’on a un ensemble dès le départ, tel qu’on l’a décrit ici, soit, on connaît une fonction de transition � ∶ �� qui indique quels sont les états accessibles à partir de l’état initial �! »!#!$%. Dans tous les cas, ce formalisme fait l’hypothèse qu’on connait les actions possibles et leurs conditions d’application, ce qui permet la transition d’un état à l’autre. Il est alors possible de tester et donc de connaître toutes les combinaisons d’actions possibles pour atteindre l’état final espéré. Dès que la taille du problème atteint quelques centaines de variables, le modèle devient rapidement trop complexe pour que toutes les combinaisons puissent être connues et testées. Pire, même dans le cas où celui-ci connaîtrait toutes les conséquences de ces actions, il pourrait très bien faire des erreurs dans l’application de certaines de ces actions.
Appropriation du modèle dans notre contexte
Ce formalisme, bien connu a été largement utilisé dans diverses littératures aussi bien pour étudier le raisonnement cognitif et le processus de conception que pour construire la logique informatique. Il permet en effet d’avoir une représentation simple et intuitive d’un processus de 147 raisonnement et de proposer un cadre et une méthode pour résoudre un problème. Nous avons également vu que sa simplicité a également été fréquemment critiquée, remettant en cause la légitimité de son utilisation dans un certain nombre de situations. Dans le cadre de notre étude, nous allons élaborer notre interprétation des tâches déléguées à la foule au travers de ce formalisme. Nous ne le présentons ni comme un modèle cognitif ni dans le but d’une résolution informatique, mais plutôt comme un modèle qui nous permet de cerner et discuter la question de la performance d’une foule. Nous allons reprendre l’ensemble des tâches que nous avons déjà identifiées dans le chapitre précédent, à savoir tâche élémentaire, recette et résolution de problèmes et les réinterpréter dans le cadre du formalisme traditionnel. Nous montrerons que ce formalisme permet d’identifier les critères de performance associés à chacune des tâches. Ensuite nous verrons quels sont ces limites pour prendre interpréter le processus de formulation d’hypothèses basées sur les données et nous proposerons une extension de ce formalisme.