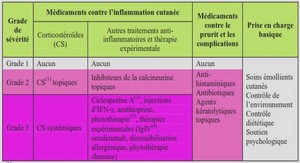
Grammaire du Français
Construction semi-automatique
Notre grammaire DRTN lexicalisée finale, qui est utilisée pour l’analyse syntaxique, est composée de l’ensemble des grammaires spécialisées pour chacun des éléments prédicatifs que nous traitons. Cette grammaire est générée automatiquement à partir d’un ensemble de meta-grammaires que nous avons Grammaire du Français CHAPITRE 4. ANALYSE SYNTAXIQUE PROFONDE 144 construites manuellement. Une meta-grammaire est composée d’un ensemble de graphes paramétrés associés à une table du lexique-grammaire. L’utilisation des graphes paramétrés fonctionne sur le même principe que le système de génération de grammaires par graphes patrons inclus dans les logiciels INTEX et Unitex (même si la nomenclature est un peu différente). Ce système de graphe patron a été repris dans plusieurs travaux exploitant les tables du lexique-grammaire pour l’analyse de textes ([Senellart, 1999] [Paumier, 2003a] par exemple) ou des recherches linguistiques sur corpus [Camugli Gallardo et Blanc, 2006]. Dans le cas de notre grammaire, chaque graphe paramétré décrit un constituant syntaxique de la grammaire dont le prédicat est une variable qui sera instanciée durant la phase de lexicalisation de la grammaire. Nous pouvons voir la meta-grammaire d’une table (c’est-à-dire l’ensemble des graphes associés à cette table) comme la grammaire de toutes les constructions syntaxiques de cette table, même si chaque construction n’est pas compatible avec toutes les entrées. Chaque chemin de cette grammaire est identifié par un paramètre qui réfère à la propriété qui lui correspond dans la table. Un paramètre a le format suivant : @X@, où X est l’intitulé d’une colonne de la table. Durant la phase de lexicalisation, le processus de génération de la grammaire construit pour chaque entrée de la table, une grammaire spécialisée dans laquelle seuls les chemins correspondant aux propriétés syntaxiques acceptées par cette entrée sont conservés. Lorsqu’une propriété identifiée par un paramètre est acceptée par l’entrée (c’est-à-dire lorsque l’intersection de la ligne et de la colonne considérées contient un +), le paramètre est remplacé par la chaîne vide dans le grammaire générée. La chaîne vide assure la continuation du chemin dans l’automate et donc que la construction est conservée. Quand la propriété n’est pas acceptée, la transition est supprimée de la grammaire ce qui a pour effet de bloquer l’ensemble des chemins passant par cette transition. Certaines propriétés ne sont pas de nature booléenne, mais contiennent des valeurs textuelles (par exemple la valeur d’une préposition), dans ce cas, le paramètre est remplacé dans la grammaire lexicalisée par la valeur de cette propriété. Il est également possible de nier un paramètre : le paramètre @ !X@ signifie que le chemin identifié par ce paramètre sera conservé uniquement si la propriété d’intitulé X n’est pas acceptée par l’entrée considérée. Enfin, le paramètre spécial @%id@ sera remplacé au moment de la lexicalisation par le numéro de ligne de l’entrée considérée. Ce paramètre est utile pour identifier de façon unique une entrée d’une table du lexique grammaire, même lorsque cette table contient plusieurs entrées pour un même lemme. Par exemple, la figure 4.35 présente un graphe paramétré associé à la table 6. Cette table comporte la description des verbes à structure transitive simple avec complément direct phrastique, c’est-à-dire les verbes (comme admettre) qui entrent dans la construction N0 V N1, avec N1=:que P + N : Luc a finalement admis (son erreur + que Lea l’a quitté). Nous décrivons dans notre graphe les formes de base pour les verbes de cette table2 . Les différents chemins de la grammaire sont identifiés par des paramètres qui réfèrent aux propriétés de la table leur correspondant. Par exemple, le paramètre @N0=Nhum@ réfère à la colonne dans la table indiquant si le verbe admet un sujet humain, le paramètre @N0V@ réfère à la colonne qui indique si le verbe admet l’ellipse de son objet direct. De même, le paramètre @entry@ à valeur textuelle fait référence à la colonne dans la table où est donné le lemme de l’entrée. Le graphe de la figure 4.36 montre le résultat de la lexicalisation de la grammaire pour le verbe admettre.
Constituants syntaxiques généraux
Outre les descriptions lexicalisées, qui sont générées à partir de notre metagrammaire, nous avons également fait la description de constituants généraux non lexicalisés qui sont utilisés dans la plupart des constituants de notre grammaire. Il s’agit, entre autres, des constituants Ins, pour la description des adverbes d’une phrase, SN pour la description des syntagmes nominaux, SA pour celles des syntagmes adjectivaux, et V pour la description du noyau verbal. Notons que ces descriptions générales peuvent également invoquer des descriptions lexicalisées. Par exemple, notre grammaire des SN reconnaît des formes générales de groupes nominaux, mais intègre également les descriptions lexicalisées des groupes nominaux à tête prédicative qui sont générées à partir de la meta-grammaire des tables de noms. Cette même grammaire décrit la possibilité de modifier le nom tête par une proposition relative qui est elle-même décrite par la grammaire lexicalisée de son prédicat principal. Il en est de même pour la grammaire des adverbes, qui comprend par exemple la description des phrases introduites par une conjonction de subordination. Ainsi, toutes ces descriptions générales forment une sorte de liant entre les descriptions lexicalisées décrites dans la meta-grammaire, et permettent de ce fait d’obtenir une grammaire cohérente capable d’analyser des énoncés complexes comprenant plusieurs propositions enchassées. Nous présentons ici plus en détail notre grammaire SN décrivant les syntagmes nominaux et notre constituant V qui décrit le noyau verbal d’une phrase (conjuguée, infinitive ou participiale). Constituant SN Le graphe de la figure 4.38 présente notre grammaire SNsimple, pour la description des syntagmes nominaux simples, c’est-à-dire non coordonnées. A gauche, nous décrivons la tête du syntagme nominal, qui peut être réalisée soit par un pronom tonique (moi, lui-même, etc.), indéfini (personne, quelqu’un, etc.) ou démonstratif (celui-ci, ceux, etc.), soit par un nom propre décrit dans le constituant Npr, soit par un autre groupe nominal non récursif décrit dans le constituant chunk. Dans tous les cas, nous unifions la structure de traits associée à ce constituant avec l’attribut head du constituant englobant (avec l’équation head=$$), et nous faisons remonter les informations indiquant son genre, son nombre, sa personne, sa sous-catégorie sémantique et son lemme au niveau du SN (équations ˆgender, ˆnumber, ˆpers, ˆsubcat et ˆlemma).