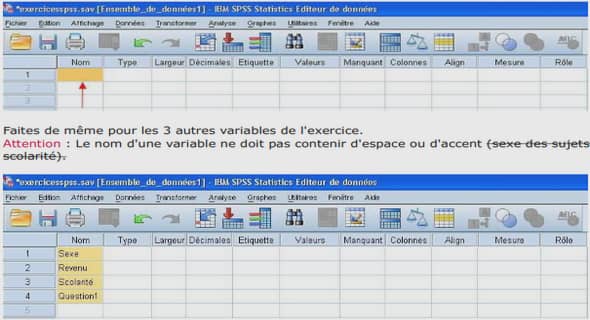
Le chaos : des questions théoriques aux enjeux sociaux
Algorithme pour un opérateur évaluant une seule fonction Dans cette section sont détaillées les étapes de la génération d’un opérateur évaluant une seule fonction sur un intervalle. On illustre le fonctionnement de l’algorithme par l’étude d’un opérateur pour la fonction sinus sur l’intervalle [0, π/4[ , sans appliquer de transformation sur l’argument pour plus de simplicité. On pose wI = 12 bits, et on vise une erreur moyenne d’environ µ = 2−12 . Un polynôme de degré 3 est utilisé pour l’approximation, et la précision interne de l’opérateur est de 14 bits (g = 2). L’approximation polynomiale de départ est estimée numériquement par la commande minimax de Maple. Le polynôme minimax de degré 3 pour la fonction sinus sur l’intervalle [0, π/4[ , avec des coefficients arrondis à 10 décimales, est : p ∗ (x) = −0.0000474553 + 1.0017332478 x − 0.0095826177 x 2 − 0.1522099691 x 3 . Son erreur est d’au plus εth = 4.75×10−5 , ce qui est équivalent à plus de 14.3 bits de précision, dans le cadre d’une évaluation exacte avec des coefficients d’une précision infinie pour l’évaluation du polynôme. 1.5.1 Étape 1 : quantification des coefficients p ∗ i Dans un premier temps, les multiplications utilisées pour l’évaluation des monômes p ∗ i × x i sont éliminées. Pour ce faire, la valeur théorique p ∗ i est remplacée par une valeur qi proche, mais qui peut être écrite sous la forme d’un nombre en borrow-save avec seulement un petit nombre ni de chiffres non nuls. Ceci permet d’approcher la multiplication p ∗ i × x i à l’aide de (ni − 1) additions seulement. Une erreur proportionnelle à |p ∗ i − qi | est faite, qui dépend à la fois de p ∗ i et de ni . Cette erreur peut être diminuée en accroissant la valeur de ni . La figure 1.1 montre l’erreur commise lors de la quantification des valeurs écrites sur 12 bits fractionnaires qui sont comprises entre 0 et 1, pour ni = 3 (en haut) et ni = 4 (en bas). Algorithme de quantification L’algorithme de quantification d’un coefficient p ∗ i en utilisant ni bits non nuls avec l bits de précision est décrit dans l’algorithme 1. À chaque itération, la puissance de 2 la plus proche du reste partiel (initialisé à p ∗ i ) est calculée et ajoutée à qi . On itère jusqu’à ce que ni chiffres non nuls aient été ajoutés à qi ou qu’une erreur inférieure à 2 −l ait été atteinte (la puissance de 2 la plus proche du reste est plus petite que 2 −l ). Si ni est suffisant, le résultat de la quantification est une approximation de p ∗ i écrite avec aussi peu de chiffres non nuls que possible et une erreur inférieure à 2 −l . S’il n’est pas possible d’approcher p ∗ i avec une erreur inférieure à 2 −l , le coefficient quantifié est écrit sur ni chiffres non nuls et aussi proche que possible de p ∗ i . On veut aussi que le coefficient retourné ait la plus petite largeur possible, c’est à dire la plus petite différence entre les rangs des bits de poids le plus fort et le plus faible. Par exemple, l’algorithme devrait retourner (11.01)bs plutôt que (101.01)bs pour la valeur 3.25 quantifiée avec ni = 3 chiffres non nuls. À la première itération, on veut donc avoir t = 1 plutôt que t = 2. Pour ce faire, lorsqu’il reste plus d’un chiffre non nul à utiliser, au lieu d’incrémenter t lorsque r > 3 2 × 2 t on ne va l’incrémenter que si r > 13 8 × 2 t . Le calcul de t devient : Figure 1.1 Erreur de quantification des valeurs 12 bits sur l’intervalle [0, 1[ pour ni = 3 (en haut) et ni = 4 (en bas). t ← ⌊log2 |r|⌋; si r > 13 8 × 2 t alors t ← t + 1 sinon si n + 1 ≥ ni et r > 3 2 × 2 t alors t ← t + 1 La condition n + 1 ≥ ni permet de ne pas perdre de précision. En effet, sans cette condition, la quantification de 3.25 avec ni = 1 chiffre non nul donnerait (10)bs, ce qui est une approximation moins précise que (100)bs. Exemple 1.2 La quantification de p ∗ 1 = 1.0017332478 se fait avec différentes précisions suivant la valeur de n1 : Si n1 = 1, q1 = 20 = (1.00000)bs approche p ∗ 1 avec une précision de 9.1 bits (p ∗ 1 − q1 = 0.0017332478).
ALGORITHME POUR UN OPÉRATEUR ÉVALUANT UNE SEULE FONCTION
Algorithme 1 : Algorithme de quantification. Données : un coefficient p ∗ i , une contrainte ni et une précision l. Résultat : qi coefficient borrow-save proche de p ∗ i écrit sur au plus ni chiffres non nuls. n ← 0 ; qi ← 0 ; r ← p ∗ i t ← ⌊log2 |r|⌋ si r > 3 2 × 2 t alors t ← t + 1 tant que n < ni et t ≥ −l faire r ← r − 2 t signe(r) qi ← qi + 2t signe(r) n ← n + 1 t ← ⌊log2 |r|⌋ si r > 3 2 × 2 t alors t ← t + 1 Si n1 = 2, q1 = 20 + 2−9 = (1.000000001)bs approche p ∗ 1 avec une précision de 12.1 bits (p ∗ 1 − q1 = 0.0002198772). Si n1 = 3, q1 = 20 + 2−9 − 2 −12 = (1.000000001001)bs approche p ∗ 1 avec une précision de 15.3 bits (p ∗ 1 − q1 = 0.0000242634). Selon le support d’implantation, certaines représentations peuvent être préférables à d’autres. Par exemple, dans une implantation sur ASIC, il peut s’avérer plus efficace de favoriser les représentations avec un minimum de chiffres négatifs, car une soustraction peut être plus coûteuse à réaliser qu’une addition. Dans ce cas, lors de la quantification de la valeur 1.375, la représentation (1.011)bs devra être choisie plutôt que la représentation apparemment équivalente (1.101)bs. Quantification des coefficients d’un polynôme On sait que le polynôme minimax est le meilleur polynôme d’approximation à coefficients réels d’une fonction pour la norme du maximum, en supposant que son évaluation est faite exactement. Cependant, dans un circuit des contraintes s’appliquent aux coefficients du polynôme et à son évaluation. Les coefficients sont par exemple arrondis vers une valeur en virgule fixe en précision finie. Il n’y a alors aucune garantie que le polynôme résultant de l’application de ces contraintes sur les coefficients du minimax soit bien la meilleure approximation polynomiale à coefficients contraints [14]. Afin d’améliorer la qualité de l’approximation q(x) dont les coefficients (sauf q0) sont quantifiés, on applique un procédé itératif où la différence entre la valeur du polynôme minimax p ∗ et celle du polynôme contraint q est réutilisée pour ajuster les qi . L’algorithme part des monômes de faible degré, et réinjecte cette erreur dans le calcul des coefficients de degré supérieur (à ce niveau, le domaine d’étude est inclus dans [−1, 1[ , donc les monômes ont d’autant moins d’impact que leur degré est élevé). Ce procédé itératif permet de corriger en partie l’erreur due à l’application des contraintes. On va ainsi obtenir une meilleure approximation contrainte de ce que donne l’application directe des contraintes aux coefficients p ∗ i du minimax, comme c’était le cas dans l’article d’ASAP
OPÉRATEURS MATÉRIELS POUR L’ÉVALUATION DE FONCTIONS MULTIPLES
Calcul des contraintes de quantification ni Comme le montre la figure 1.1, les ni ont une influence majeure sur la précision des coefficients quantifiés qi par rapport aux coefficients réels p ∗ i du minimax. Dans l’article d’ASAP, on fixait arbitrairement la valeur des ni à 3. Il est désormais possible de déterminer automatiquement une valeur minimale pour les ni qui donne un polynôme d’approximation approchant la fonction avec une précision suffisante. Le calcul des contraintes est décrit dans l’algorithme 2. Algorithme 2 : Calcul des ni . Données : le polynôme minimax p ∗ (x), l’erreur visée µ. Résultat : les contraintes de quantification ni permettant d’atteindre µ. (n1, n2, . . . , nd) ← (0, 0, . . . , 0) On calcule q(x) pour les contraintes (n1, n2, . . . , nd). tant que εavg(q(x)) > µ faire e(x) ← minimax ((f − q)(y), y ∈ [a, b[, d) ← e0 + e1x + · · · + edx d pour i = 1 à d faire si R [a,b[ |eix i | > µ alors ni ← ni + 1 On recalcule les coefficients quantifiés de q(x) avec les nouvelles contraintes (n1, n2, . . . , nd). Le polynôme e(x) qui apparaît dans l’algorithme sert à caractériser l’erreur commise en évaluant la fonction f à l’aide d’un polynôme quantifié q. Chaque monôme eix i de e(x) peut être vu comme la contribution à l’erreur du monôme de degré i, due à la fois à l’erreur du minimax et à la quantification du coefficient qi . Exemple 1.3 On calcule des valeurs des contraintes ni pour une approximation polynomiale de degré 3 de la fonction sinus, avec une précision visée de 12 bits. À chaque étape, la contrainte ni en gras a été incrémentée par l’algorithme, parce que le monôme de degré i de e(x) indiquait une trop grande contribution à l’erreur. (n1, n2, n3) νavg (en bits) νmax (en bits) (0, 0, 0) 1.1 0.2 (1, 1, 1) 7.3 5.3 (2, 2, 2) 9.8 7.5 (2, 2, 3) 12.6 9.2 Les contraintes ni calculées par l’algorithme reflètent le besoin en précision de chaque coefficient quantifié qi . Elles dépendent de la magnitude de p ∗ i , du degré i du monôme (on a x ∈ [−1, 1[ , donc un monôme a en général d’autant moins d’influence que son degré est haut), et de la difficulté d’approcher p ∗ i par un coefficient quantifié (figure 1.1). Bien que le coefficient p ∗ 1 = 1.0017332478 ait une forte amplitude, n1 = 2 suffit car p ∗ 1 est proche (à 12.1 bits près) de q1 = 20 + 2−9 . Par contre, p ∗ 3 = −0.1522095004 est plus petit, mais n3 = 3 chiffres non nuls sont requis pour avoir une approximation suffisamment proche q3 = −2 −3 − 2 −5 + 2−8 (à 12.9 bits près).
Étape 2 : approximation des puissances x i
Une fois les coefficients du polynôme quantifiés, on a toujours besoin de quelques multiplieurs pour évaluer q(x) = q0+q1x+q2x 2+. . .+qdx d . En effet, il faut calculer les puissances x i de l’argument. Puisqu’un schéma d’évaluation parallèle est utilisé, on a besoin de toutes ces puissances en même temps. Deux manières de les calculer sont présentées et comparées ici. La première repose sur des opérateurs optimisés calculant chacun une puissance. La seconde utilise un réseau de multiplieurs de Booth modifiés et de squarers, qui implantent un équivalent matériel de l’algorithme d’exponentiation rapide. Opérateurs spécialisés pour le calcul des puissances Dans [3], les estimations des puissances de x étaient obtenues en développant le tableau de produits partiels (Partial Products Array) de x i puis en y appliquant des simplifications logiques classiques utilisées pour le carré [11, p.221], [13, p.201]. Ces simplifications reposent sur l’application de règles logiques qui permettent de diminuer le nombre de produits partiels ou de modifier leur répartition. Dans le cadre de l’extension de la méthode présentée à ASAP [3], nous avons étudié les opérateurs pour les puissances entières, et obtenu de nouvelles réductions logiques ainsi qu’une stratégie de réduction efficace. Ces travaux ont été présentés [4] lors de la conférence SPIE en 2006. Les nouveaux opérateurs pour le calcul des puissances sont obtenus par une méthode hybride basée sur ces travaux et ceux présentés dans [31]. Une description détaillée en est faite en section 1.9. Structure square-and-multiply pour le calcul des puissances Notre programme est aussi capable de calculer les puissances de x à l’aide d’un équivalent matériel de l’algorithme d’exponentiation rapide (square-and-multiply). Cet algorithme calcule la puissance ième de x récursivement de la façon suivante : x i = x, si i = 1, (x 2 ) i/2 si i est pair, x × (x 2 ) (i−1)/2 si i > 2 est impair. Par exemple, x 5 est calculé sous la forme x × ((x 2 ) 2 ). Dans le circuit, les composants sont partagés entre les différentes puissances, c’est à dire que x 2 sert à calculer x 4 qui lui-même est utilisé pour obtenir x 5 . La figure 1.2 montre une unité de ce type utilisée pour le calcul exact des puissances 2 à 6 de x. Estimation des puissances Les opérateurs calculant les puissances décrits ci-dessus retournent un résultat exact, ce qui est inutile dans le cadre de notre application. Il est donc possible de réduire la surface du circuit en appliquant un schéma de troncature aux tableaux de produits partiels qu’ils contiennent. Dans l’article d’ASAP [3], on appliquait un schéma de troncature directe, qui consiste à n’implanter qu’une partie du tableau de produits partiels correspondant aux colonnes de poids fort. Le schéma de troncature variable [30] (VCT) est un bon candidat. Il s’agit d’un schéma dépendant des données, qui donne une précision meilleure que le schéma de troncature directe. On aura donc besoin de moins de colonnes dans les tableaux de produits partiels pour atteindre la même 18 Figure 1.2 Structure square-and-multiply pour le calcul exact des puissances 2 à 6 de x. précision, d’où des opérateurs plus petits. Le schéma de troncature VCT approche la valeur des retenues générées dans la partie tronquée en utilisant la première colonne des produits partiels tronqués, qui est multipliée par 2 (décalée d’une position vers la gauche). Les produits partiels de poids plus faibles sont omis. Lorsqu’on applique ce schéma aux opérateurs spécialisés pour le calcul des puissances, on déplace des produits partiels dans le PPA : il est possible d’appliquer de nouveau le procédé de réduction décrit en section 1.9 pour diminuer encore plus la surface de l’unité. L’estimation tronquée de x i , notée ∆i (x, ci), est caractérisée par le nombre de colonnes ci du tableau de produits partiels qui sont conservées et implantées. Ce tableau tronqué est soit celui d’un opérateur optimisé, ou vient des multiplieurs et unités d’élévation au carré d’une structure square-and-multiply. Calcul des contraintes d’estimation ci La valeur minimale de ci qui permet d’obtenir une estimation suffisamment précise de x i dépend principalement de p ∗ i . En effet, plus p ∗ i est petit et plus on peut se permettre d’utiliser une estimation grossière de x i dans l’approximation du monôme p ∗ i x i . Les contraintes ci étaient fixées arbitrairement dans l’article d’ASAP [3]. Une procédure automatique est maintenant intégrée à l’algorithme qui permet d’obtenir les valeurs minimales suffisantes des ci pour les deux types d’unités de calcul des puissances. Dans le cas des puissances calculées en parallèle dans des opérateurs spécialisés, le nombre de colonnes ci utilisées pour l’estimation de x i est calculé en partant de ci = 1 et incrémentant ci jusqu’à ce que l’erreur faite en approchant le monôme p ∗ i x i par qi × ∆i (x, ci) soit inférieure à µ. Pour une structure square-and-multiply, l’estimation de x i est réutilisée dans le calcul des puissances suivantes, comme le montre la figure 1.2. Il faut donc non seulement que les ci soient suffisants pour que qi × ∆i (x, ci) approche p ∗ i x i précisément, mais aussi qu’en réutilisant ∆i (x, ci) on soit capable d’approcher les monômes suivants précisément. Pour ce faire, on détermine les ci dans l’ordre croissant. On part de ci = 1 et on l’incrémente jusqu’à ce que les approximations de p ∗ i x i et de tous les p ∗ jx j avec j > i (en supposant que les multiplications et carrés aux étapes j > i sont calculés exactement) soient toutes assez précises. Le coût matériel du calcul exact des puissances est proportionnel à (wI ) d pour les opérateurs optimisés parallèles, et proportionnel à (wI ) 2 seulement pour la structure square-and-multiply. Les optimisations, en particulier le tri et les réductions logiques, ne servent qu’à diminuer la constante de proportionnalité. On pourrait donc penser que les puissances parallèles ne sont pas aussi efficaces qu’une structure square-and-multiply. C’est en effet le cas pour un calcul exact des puissances, comme on peut le voir dans [31] pour un calcul du cube. L’opérateur spécialisé devient plus gros pour wI ≥ 16. Cependant, on ne calcule ici qu’une estimation des puissances, afin de remplir un critère de précision finale. Les opérateurs tronqués, pour des degrés allant jusqu’à 6 et des précisions d’au plus 24 bits, demandent en général des ressources similaires pour les deux manières de calculer les puissances. Pour des fonctions impaires comme par exemple le sinus, les puissances parallèles sont souvent un meilleur choix, car les puissances de x y sont calculées indépendamment. Les puissances paires sont alors évaluées très grossièrement. Dans une structure de type squareand-multiply, on est obligés d’évaluer les puissances paires (par exemple x 2 ) avec une précision.
Introduction |