Bases de données et échantillonnage
Circuler fait partie des activités principales de l’homme. Cette activité évolue en conséquence au fil du temps à long terme, et comprend en même temps des phénomènes périodiques à court terme. Le trafic routier a beaucoup varié selon le temps : à long ou moyen et même à court terme, il y a les changements de technologie dont ceux du moyen de transport routier et de l’infrastructure, de l’utilisation des systèmes intelligents et d’information avancés, etc. ; à chaque instant, il y a la condition de météorologie, l’ambiance environnementale (parfois appelée la lisibilité de la route), l’information survenue, etc. Le trafic routier varie aussi selon l’espace, par exemple la zone d’aménagement (urbain, péri-urbain, commerciale, rural, etc.), le type du réseau routier (autoroute, route nationale, route départementale, etc.), la position du tronçon (en section droite et plate, à proximité d’une intersection, en virage, etc.) et la localisation latérale de la voie (sur la voie rapide, voie lente, etc.)…Toutes ces influences et plusieurs autres sont prises de façon consciente ou inconsciente par le conducteur. Elles participent de toute manière à la décision finale au volant qui représente un comportement individuel dans le trafic. Ce comportement une fois enregistré entre ensuite dans une base de données du trafic. Enfin, l’analyse statistique va traiter la base de données pour fournir des connaissances sur le comportement de l’ensemble (ou bien comportement collectif).
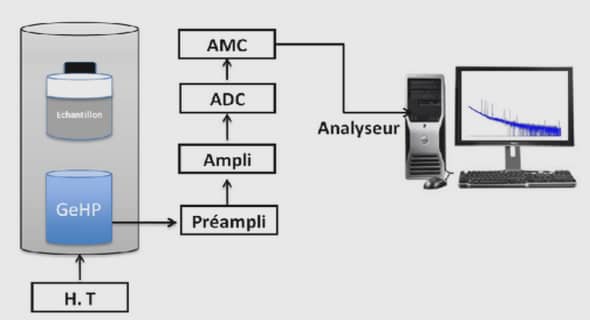
Comme plusieurs facteurs sont mis en jeu dans la réalité du trafic, la constitution de la base de données précitée devrait dans une certaine mesure faciliter la connaissance des facteurs principaux en précisant où, quand et dans quelles conditions les informations ont été obtenues. Le but est d’approcher et d’interpréter le mieux possible le comportement collectif des conducteurs. Par conséquent, l’identification des échantillons dans la base de données constitue une étape préliminaire et indispensable pour le calibrage, la modélisation probabiliste et la validation. La première étape consiste à enregistrer de manière automatique les données individuelles au moyen des stations de mesure. La durée de l’enregistrement peut varier de quelques heures à quelques jours pendant lesquelles les informations de passage véhicule par véhicule sont transmises à la station. Trois types de données de base dans l’étude de TIV sont traités : l’instant de passage (normalement en centièmes de seconde), la vitesse instantanée (en m/s) et la longueur (en dm) des véhicules. Pour faciliter le traitement des données tout en respectant l’information privilégiée de la variable TIV, les enregistrements du premier type sont éliminés tandis que dans le cas des erreurs du second type, la vitesse et la longueur du véhicule considéré sont ajustées à celles correspondantes du véhicule précédent. Cet ajustement du deuxième type d’erreur n’entache pas en revanche la distribution des TIV très courts obtenue car peu d’erreurs dans la base de données sont survenues au final. D’autant que l’assimilation d’une remorque par un véhicule particulier, si tel était le cas, peut être considérée comme une définition élargie du TIV ce qui est aussi intéressant à interpréter.
Les données brutes comportent éventuellement des variations non-aléatoires, c.à.d que les caractéristiques des données peuvent comprendre des tendances statistiques. Il faut soit tenir compte spécifiquement de ces tendances dans les modèles, soit se restreindre aux échantillons stationnaires possédant des propriétés stables et n’évoluant pas en fonction du temps. Deux méthodes sont utilisées pour éliminer les échantillons non-stationnaires de TIV : la première consiste à regrouper les données selon quelques critères prédéterminés tandis que la deuxième consiste à échantillonner en se basant sur la stabilité du nombre de véhicules arrivés dans une période. La première méthode appelée méthode de groupement a besoin généralement d’une base de données assez importante afin d’éviter la fragmentation et la stratification – c.à.d un trop faible nombre de données dans chaque « case » issue du croisement des modalités des variables d’influence. La deuxième méthode étant la méthode de raffinement assure la stabilité du débit. Pour les deux méthodes d’échantillonnage, l’idée commune est d’utiliser des critères statistiques pour obtenir une stabilité au niveau des données réelles. Une troisième méthode utilise un processus d’analyse de tendance en vue de choisir les échantillons des TIV [11]. Dans notre étude, les tests de tendance de cette méthode sont employés en complément après que la méthode de raffinement a été utilisée. Les deux méthodes précitées sont décrites en détail.