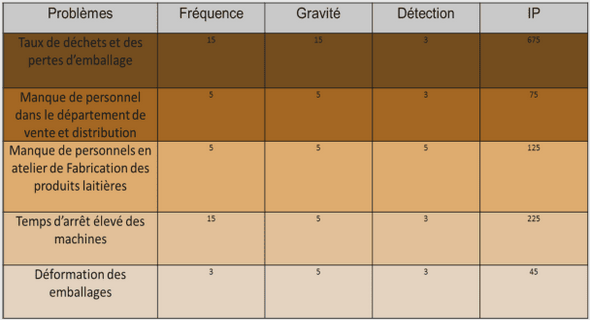
Image denoising
Removing noise from images is an essential pre-processing step to many image analysis applications. The problem of image denoising can be defined formally as recovering the original image x from its noisy observation y = x + n, where n is a zero-mean additive noise vector (e.g., Gaussian, Laplacian, Rician, etc.). Approaches for this problem can be roughly divided in three categories: spatial domain, transform domain and learning-based methods (Katkovnik et al., 2010). Spatial domain methods leverage the correlations between local patches of pixels in an image. In such methods, pixel values in the denoised image are obtained by applying a spatial filter, which combines the values of candidate pixels or patches. A spatial filter is considered local if its support for a pixel is a distance-limited neighborhood of this pixel. Numerous local filtering algorithms have been proposed in the literature, including Gaussian filter, Wiener filters, least mean squares filter, trained filter, bilateral filter, anisotropic filtering and steering kernel regression (SKR) (Szeliski, 2010). Although computationally effective, local filtering methods do not perform well in the case of structured noise due to the correlations between neighboring pixels.
On the other hand, nonlocal filters like nonlocal means (NLM) (Buades et al., 2005a; Mahmoudi and Sapiro, 2005; Coupé et al., 2008; Wang et al., 2006) consider the information of possibly distant pixels in the image. Various works have shown the advantage of nonlocal filtering methods over local approaches in terms of denoising performance (Zimmer et al., 2008; Dabov et al., 2007; Mairal et al., 2009), in particular for high noise levels. However, nonlocal spatial filters may still lead to artifacts like over-smoothing. Unlike spatial filtering approaches, transform domain methods represent the image or its patches in a different space, typically using an orthonormal basis like wavelets (Luisier et al., 2007), curvelets (Starck et al., 2002) or contourlets (Do and Vetterli, 2005). In this transform space, small coefficients correspond to high frequency components of the image which are related to image details and noise. By thresholding these coefficients, noise can be removed from the reconstructed image (Donoho, 1995). Compared to spatial domain approaches, transform domain methods like wavelets better exploit the properties of sparsity and multi-resolution (Pizurica et al., 2006).
However, these methods employ a fixed basis which may not be optimal for a given type of images. Recent research has focused on defining the transform basis in a data-driven manner, using dictionary learning (Elad and Aharon, 2006; Mairal et al., 2009; Dong et al., 2011a). Although many denoising approaches based on dictionary learning are now considered state-of-the-art, these approaches are often computationally expensive. Finally, denoising methods based on statistical learning model noisy images as a set of independent samples following a mixture of probabilistic distributions such as Gaussians (Awate and Whitaker, 2006). Mixture parameters are typically inferred from data using an iterative technique like the expectation maximization algorithm. However, these methods are sensitive to outliers (i.e., pixels with high noise values), which affect the parameter inference step. Various techniques have been proposed to deal with this problem. In (Portilla et al., 2003), scale mixtures of Gaussians are applied in the wavelet domain for greater robustness. Moreover, a Bayesian framework is presented in (Dong et al., 2014b), which extends Gaussian scale mixtures using simultaneous sparse coding (SSC).
Image completion
Image completion or inpating is another important problem in image processing and low level computer vision, which consists in recovering missing pixels or regions in an image. Let Ω 20 be the set of observed pixels (i.e., the mask) in image y, the goal is to recover the full image x under the constraint that PΩ(x) = PΩ(y), where PΩ denotes the operator projecting over elements in Ω. In the generative model of Eq. (1.2), the degradation operator Φ corresponds to a diagonal matrix such that Φii = 1 if pixel i ∈ Ω, else Φii = 0. Over the years, a flurry of studies have aimed at solving the problem of image completion (Chierchia et al., 2014; He and Wang, 2014; Heide et al., 2015; Ji et al., 2010; Zhang et al., 2012, 2014a; Li et al., 2016; Kwok et al., 2010). Approaches for this task can be classified as structure-based, texture-based or low-rank approximation-based methods. Structure-based methods focus on the continuity of geometrical structures in the image, and attempt to fill-in missing structures in a way that is consistent with the rest of the image. Approaches in this category include partial differential equation (PDE) or variational-based methods (Masnou, 2002), convolutions (Richard and Chang, 2001), and wavelets (Chan et al., 2006; He andWang, 2014). Because they focus on structure, however, such approaches are usually unable to recover large regions or regions with complex textures. In contrast, texture-based regions address the image completion task via a process of texture synthesis. Statistical texture synthesis approaches extract features from pixels surrounding the missing region to build a statistical model of texture (Levin et al., 2003; Portilla and Simoncelli, 2000).
This model is then used to generate a texture for the missing region that has the same visual appearance as the available textures. Methods based on textures can operate at the pixel or patch level. Pixel-based textural inpainting techniques generate missing pixels one-byone, using techniques like Markov Random Fields (MRF) to ensure consistency with neighbor pixels (Efros and Leung, 1999; Tang, 2004). Patch-based or examplar-based techniques (Criminisi et al., 2004; Drori et al., 2003; Kwok et al., 2010) preserve the consistency of the missing region by reconstructing it patch by patch, as opposed to pixel by pixel. The key idea of such techniques is to find candidate patches from the image and combine them to fill-in the missing region. This process is typically applied iteratively, until the filled region is consistent internally and with surrounding pixels (Criminisi et al., 2004). In general, the quality of results depends on various factors such as patch size, patch matching algorithm, patch filling priority, etc. However, unlike pixel-based approaches, image completion methods using patches can leverage nonlocal patterns in the image to obtain a higher performance. The last category of image completion methods are based on low-rank approximation.
The methods stem from recent advances in the fields of matrix completion (Zhang et al., 2012; Wright et al., 2009; Eriksson and van den Hengel, 2012; Buchanan and Fitzgibbon, 2005; Eriksson and Van Den Hengel, 2010; Candes and Recht, 2012; Cai et al., 2010) and tensor completion (Romera-Paredes and Pontil, 2013; Tomioka et al., 2010;Weiland and Van Belzen, 2010; Liu et al., 2013b). The general principle of these approaches is to divide the image into even-size sub-regions (i.e., patches), in such way that some patches contain both observed and missing pixels. Patches are then stacked into a matrix/tensor, and those with missing pixels are recovered by solving a matrix/tensor completion problem. For instance, in (Li et al., 2016), a low-rank matrix approximation technique is combined with a nonlocal autoregressive model to reconstruct image patches efficiently. Moreover, a truncated nuclear norm regularization technique is proposed in (Zhang et al., 2012), which can reconstruct patches with a higher accuracy by considering only a small number components (i.e., singular vectors).
Super-resolution
In super-resolution (SR), the degradation operator Φ corresponds to a down-sampling matrix and the problem is to recover the high-resolution image x from its low-resolution version y. Hence, this task is often considered as interpolation. Image super-resolution is essential to enhance the quality of images captured with low-resolution devices, and has become a popular research area since the preliminary work of Tsai and Huang (Tsai and Huang, 1984). Numerous techniques have been proposed for this task over the last years, stemming from signal processing and machine learning. Based on the number of observed low-resolution images, these techniques can be separated into single-frame or multi-frame methods. Single-frame methods (Glasner et al., 2009; Yang et al., 2010a; Bevilacqua et al., 2012; Zeyde et al., 2010) typically employ a learning algorithm to reconstruct the missing information of super-resolved images based on the relationship between low- and high-resolution images in a training dataset.
In contrast, multiple-image SR algorithms (Capel and Zisserman, 2001; Li et al., 2010) usually suppose some geometric relationship between the different views, which is then used to reconstruct the super-resolved image. SR methods can also be grouped based on whether they work in the spatial domain or a transform domain (e.g., Fourier (Gunturk et al., 2004; Champagnat and Le Besnerais, 2005) or wavelets (Zhao et al., 2003; Ji and Fermüller, 2009)). SR methods in the spatial domain are numerous and include techniques based on iterative back projection (Zomet et al., 2001; Farsiu et al., 2003), non-local means (Protter et al., 2009), MRFs (Rajan and Chaudhuri, 2001; Katartzis and Petrou, 2007), and total variation (Farsiu et al., 2004; Lian, 2006). Patch-based SR methods address the problem by learning a redundant dictionary for highresolution patches, and aggregating the reconstructed high-resolution patches into a superresolved image (Freeman et al., 2000; Chang et al., 2004; Yang et al., 2010a; Bevilacqua et al., 2012; Zeyde et al., 2010; Timofte et al., 2013). Recently, deep-learning SR techniques like convolutional neural networks (CNN) (Dong et al., 2016; Kim et al., 2016) have gained a tremendous amount of popularity. Such techniques learn an end-to-end mapping between low resolution and high-resolution images, composed of sequential layers of non-linear operations (e.g., convolution, spatial pooling, rectification, etc.). The main drawback of such techniques is their requirement for large volumes of training data, and their tendency to overfit the training dataset.
INTRODUCTION |