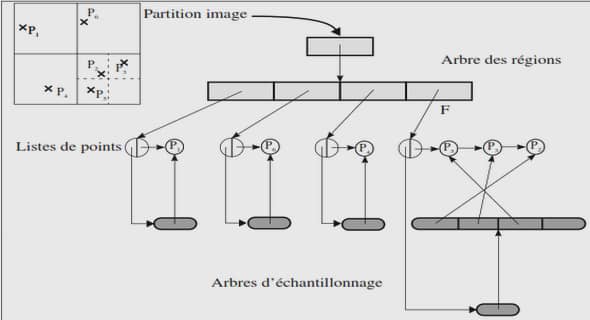
Annoter par règles selon leur confiance
les marqueurs insérés dans le cadre d’une annotation. Pour une règle d’annotation T , la fonction Ret (T ) = ‘VERB/rencontrerCELEB/NP CELEB/NP’ . Nous voyons alors la possibilité de réaliser, comme pour les systèmes orientés connaissancesprésentés en 3.1, des transductions, c’est à dire l’insertion de marqueurs au sein du texteafin de réaliser l’annotation en entités nommées. Ainsi, nous définissons la transduction comme l’affectation de marqueurs au sein d’un énoncé. Pour cela, nous requérons que la règle d’annotation, lorsque les marqueurs sont omis, dispose d’une occurrence dans l’énoncé. De plus, nous contraignons cette affectation de telle sorte que l’alternance des marqueurs insérés et des items de l’énoncé se géné- ralise hiérarchiquement en la règle d’annotation. La séquence obtenue par transduction sera M peut contenir plusieurs marqueurs à insérer pour une position au sein de l’énoncé, comme par exemple pour la règle d’annotation ‘<fonc> DET/le NC/président </fonc> <pers> CELEB/NP CELEB/NP </pers>’. Nous nous en tenons à cette définition et n’entrons pas ici dans des discussions plus approfondies sur le principe des transductions. Mentionnons simplement que nous réalisons au plus une seule transduction par occurrence associée dans un énoncé à chaque règle d’an- notation et que nous affectons, s’il y a litige, les marqueurs le plus à gauche possible, tout en tenant compte de contraintes liées aux guides d’annotation. De manière plus générale, nous savons que pour un énoncé donné, si nous disposons nombreuses règles d’annotation extraites, il y a nécessité de prendre une décision sur les transductions possibles, ce qui peut être réalisé de multiples manières.
Annoter par règles selon leur confiance
Nous sommes donc, à partir des règles d’annotation, en mesure de réaliser des transduc- tions sur un énoncé. Nous pourrions naïvement chercher à réaliser toutes les transductions possibles et considérer que l’on a obtenu une annotation. Ce principe est mis en difficulté pour les deux raisons suivantes : – Règles partielles : jusque là, nous n’avons pas émis de contraintes sur la formation des marqueurs au sein d’une règle d’annotation, l’application d’une règle d’annotation peut conduire à introduire un seul marqueur, des marqueurs de types différents, etc.– Imbrications et chevauchements : réaliser une transduction ne tient pas compte des marqueurs déjà insérés dans l’énoncé et peut aboutir à une annotation avec des chevauchements ou des imbrications, qui sont généralement interdites par les guidesNous le voyons, chacune de ces deux raisons empêche d’appliquer toutes les règles d’annotation systématiquement. La problématique est ici de produire en sortie une anno- tation qui soit conforme aux règles édictées dans le guide d’annotation. Il est trivial de montrer que les règles partielles ne produisent pas une annotation valide. Pour les im- brications et chevauchements, nous faisons remarquer que même l’application des règles les plus simples peut être problématique. Par exemple réaliser toutes les transductions de la règle ‘<pers> CELEB/NP CELEB/NP </pers>’ sur les items ‘CELEB/NP/Léopold CE- LEB/NP/Sédar CELEB/NP/Senghor’ produira l’annotation ‘<pers> CELEB/NP/Léopold <pers> CELEB/NP/Sédar </pers> CELEB/NP/Senghor </pers>’.
Un mécanisme de contrôle est donc indispensable pour réaliser les transductions. En première approche, nous nous inspirons du mode de fonctionnement des transducteurs : appliquer les règles d’annotation selon un ordre prédéfini, sur les occurrences les plus à gauche, tant qu’elles reconnaissent des entités nommées et produisent une annotation va- lide. Pour ce faire, nous écartons les règles dites partielles en ne sélectionnant que celles dont l’application produit une annotation conforme au guide. Enfin, la confiance nous pa- raît être une mesure naturellement adéquate à utiliser pour ordonnancer les règles. Nous rapportons en chapitre 9 les résultats obtenus avec ce premier modèle modèle utilisant les règles d’annotation pour reconnaître les entités nommées. Cependant, outre le fait d’écarter les règles partielles, ordonner les règles par leur confiance paraît intuitivement insatisfaisant. Effectivement, les règles les plus confiantes correspondent souvent à des motifs peu fréquents ou redondants dans les données explo- rées et se généralisent difficilement à de nouveaux documents. Dès lors que les règles sont extraites très exhaustivement de données, des cas particuliers (tournures de phrases, ex- pressions linguistiques, etc.) apparaissent, que le système doit utiliser avec précaution. Par ailleurs, les règles moins confiantes pourraient être utilisées, non pour réaliser l’anno- tation, mais pour conforter une hypothèse d’annotation incertaine. Nous postulons alors la nécessité pour le système de se fonder sur des combinaisons de preuves concordantes avant de prendre des décisions. Ainsi, nous sommes amenés à considérer un modèle plus élaboré, dans lequel certaines règles d’annotation constituent individuellement des indices nécessaires (mais non suffisants individuellement) pour réaliser une transduction.